
아마 프롬프트 엔지니어링을 다룬 논문 중 가장 잘 알려진 건 Chain of Thought가 아닐까 싶습니다. 유명한 논문은 흔히 원래 제목이 자주 차용되곤 하는데 chain of thought도 마찬가지입니다. CoT도 기존의 연구에서 빌려온 개념인지는 잘 모르겠지만, 프롬프트 엔지니어링을 다룬 많은 논문이 X of thought라는 표현을 사용하는 것 같습니다. 이번에 리뷰할 논문인 Contrastive Chain-of-Thought Prompting도 마찬가지입니다. CoT는 few shot 프롬프트에 단순히 문제와 정답만을 제시하는 게 아니라, 정답에 이르는 사고 과정을 포함한 few shot example을 입력하는 방법입니다. 이를 통해 LLM이 학습하지 않은 새로운 태스크를 해결하는 능력이 크게 증가하였다고 합니다. 특히 기존 논문에서는 reasoning task에서의 성능에 집중하였는데, 사고 과정이라는 표현 자체가 추론을 요구하는 복잡한 상황에서 이루어지는 현상을 의미하기 때문입니다.
그런데 재미있게도 이 프롬프트에 올바르지 않은 사고 과정이 포함되어도 여전히 모델 성능이 증가하였다는 연구가 제시되었습니다. 저자는 이 점에 착안하여 올바른 예시와 잘못된 예시를 모두 사용하고자 하였고, 이 연구를 바탕으로 논문을 제안하게 됩니다. 자세한 내용은 본문에서 알아보겠습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Introduction
거대한 규모를 갖게 된 언어 모델은 높은 일반화 성능을 보였고, 적절한 프롬프트가 주어진다면 학습하지 않은 과제도 잘 수행하는 창발적인 능력을 보이기도 했습니다. 단순히 모델 규모를 키우는 것만으로는 성능을 향상하기 어렵게 되자 LLM의 추론 능력을 활성화하기 위해 Chain of Thought(CoT)와 같은 프롬프트 전략이 제안되었습니다. CoT 기반 방법론은 대부분 프롬프트에 포함된 문제, 사고 과정(chain of thought), 정답 예시를 사용한 인컨텍스트 학습(in-context learning)을 통해 LLM이 새로운 문제에 대한 추론 능력을 갖게 합니다.
하지만 이런 연구에도 불구하고 CoT에 대한 이해가 부족한 상황입니다. 문제와 정답 예시가 몇 개(few-shot exampels) 주어지는 프롬프트를 standard prompting라고 한다면, CoT는 문제와 정답 사이에 정답을 도출한 과정을 설명합니다. 이를 바탕으로 이루어진 인컨텍스트 학습을 통해 모델의 추론 능력이 향상된다는 것이 CoT를 제안한 논문 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models의 연구 결과입니다. 그런데 Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters 논문에서는 올바르지 않은 논증이 주어져도 모델의 추론 능력이 향상된다는 것을 발견하였습니다.
이처럼 CoT를 통해 언어 모델의 추론 능력이 어떻게 향상되는지는 제대로 알려진 바가 없습니다. 게다가 중간 과정에서 발생한 실수가 누적되어 잘못된 추론으로 이어지기도 합니다. 논증 과정에서의 오류는 모델의 정확도를 떨어뜨릴 뿐만 아니라 모델의 신뢰성에도 부정적인 영향을 미칩니다. 따라서 중간 과정에서의 실수를 줄이는 것 또한 매우 중요합니다.
이런 문제를 해결하기 위해 저자는 사람이 음성 샘플(negative examples)에서 학습하는 방법에 착안하였습니다. 일반적으로 음성 샘플은 정답을 더욱 잘 이해하기 위해서 의도적으로 주어지는 틀린 예시를 의미합니다. 예를 들어서 풀이 과정이 명확하게 정의되지 않는 어려운 문제를 풀 때는 positive demonstration을 통해 정답에 이르는 과정을 학습하고, negative demonstration을 사용해 오답을 피하는 방법을 학습하는 것이 좋습니다. 이를 바탕으로 저자는 contrastive chain of thought를 제안합니다.
그렇다면 negative demonstration을 효율적으로 설계하는 방법이 무엇인지에 대한 의문이 자연스럽게 듭니다. 또 이 방법이 다양한 태스크에서 일반적으로 사용될 수 있는지에 대해서도 검증이 필요합니다. 저자는 contrastive CoT의 성능을 입증하기 위해 contrastive demonstration을 자동으로 생성할 수 있는 간단하고 효과적인 방법을 제안하였습니다. 또한 이 방법은 self-consistency처럼 태스크에 관계없이 적용 가능하기 때문에 CoT의 성능을 향상하기 위해서 일반적으로 사용될 수 있음을 보였습니다.
논문이 주요 기여는 다음과 같습니다. (1) 유효하지 않은 추론의 유형(invalid reasoning types)을 분석하였고 양성 및 음성 데모를 함께 사용하면 CoT의 성능을 높일 수 있음을 발견하였습니다. (2) 앞서 분석한 내용을 바탕으로 constrative chain of thought를 제안하였고 이를 통해 언어 모델의 추론 능력을 강화하였습니다. 또한 일반화 성능을 높이기 위해 자동으로 contrastive demonstration을 생성하는 방법을 제안하였습니다. (3) 추론 능력을 평가하는 다양한 벤치마크를 사용하여 CoT에 비해 눈에 띄게 성능이 향상되었음을 증명하였습니다.
2. Preliminary Study
Effect of Different Types of Contrastive Demonstrations
CoT를 통해 LLM의 추론 능력이 향상되었지만 그 원리는 알려지지 않았습니다. 직관적으로 문제를 해결하는 과정을 가지면 추론 능력이 개선된다는 것은 그럴 듯하게 들리지만, 유효하지 않은 논증을 통해서도 성능이 높아진다는 연구가 이루어지기도 했습니다. 반면 contrastive learning과 alignment 연구에서는 언어 모델이 유효한 예제와 유효하지 않은 예제를 함께 사용하면 학습 효과가 극대화된다는 것이 밝혀졌습니다. 따라서 저자는 CoT를 개선하기 위해 유효하지 않은 추론 예제를 사용할 수 있을까에 대한 질문의 답을 찾고자 하였습니다.
2.1 Components of Chain of Thought
기존의 프롬프트와 다르게 chain of thought 프롬프트는 few shot example에 정답의 근거(rationale)를 포함합니다. 각 rationale은 중간 추론 단계로 구성되며 언어 모델이 문제를 단계별로 풀이할 수 있도록 안내합니다. 이 논문의 저자는 CoT rationale의 구성 요소를 다음과 같이 정의하였습니다.
- Bridging objects는 최종 정답에 이르기 위해 모델이 지나는 기호 개체(symbolic items)를 의미합니다. 예를 들어 이 객체(object)는 산술 문제에서는 숫자 또는 수식이 될 수 있고, 사실을 묻는 문제에서는 이름이나 개체가 될 수 있습니다.
- Language templates는 추론 단계에서 언어 모델이 bridging objects를 잘 형상화할 수 있도록 안내하는 텍스트에 기반한 단서를 의미합니다.
2.2 What is Invalid Chain of Thought?
CoT의 요소를 정의했으므로 유효하지 않은 추론이 무엇인지 체계적으로 정의할 수 있습니다. 언어와 객체 요소에 모두 적용할 수 있는 두 가지 관점을 다음과 같이 정의하였습니다.
- Coherence는 rationale 내에서 추론이 올바른 순서에 의해 이루어지는가를 의미합니다. 이는 성공적인 CoT를 위해 필수적입니다. CoT는 순차적인 추론을 의미하므로 이후 단계가 이전 단계보다 먼저 등장해서는 안됩니다.
- Relevance는 rationale이 질문과 관련이 있는 정보를 포함하는지를 의미합니다. 예를 Leah라는 사람이 초콜릿을 먹고 있는 상황에 대해 질문했는데 다른 사람이 머리를 자르는 상황을 언급한다면 부적절한 정보가 포함된 것입니다.
여기에 더해 저자는 coherence와 relevance를 모두 만족하지만, 추론 과정에서 실수가 포함된 경우에 대해서도 고려하였습니다. 따라서 다음과 같이 유효하지 않은 추론을 다섯 가지 유형으로 구분하였습니다.
2.3 Experimental Setup
산술 추론 및 사실 추론 능력을 평가하기 위해 GSM8K와 Bamboogle 벤치마크를 사용하였습니다. 사용한 모델은 GPT-3.5-Turbo(0301)입니다. 각 프롬프트에는 4개의 예시가 포함되어 있고 CoT 프롬프트는 원본 논문의 설계를 따랐습니다. 각 프롬프팅 기법에 따른 예시는 다음과 같습니다.

GSM8K 벤치마크는 다음과 같이 산술 추론을 능력을 요구하는 줄글로 된 수학 문제로 이루어집니다.

Bamboogle 벤치마크는 다음과 같이 여러 단계를 거쳐 정답을 추론해야 하는 사실 추론 문제로 이루어집니다. 예를 들어 다음 그림의 첫 번째 문제에서, Levy Mwanawasa가 잠비아의 전 대통령이라는 사실을 바탕으로 잠비아의 수도가 루사카라는 것을 추론해야 합니다.

2.4 Preliminary Results
다음 결과를 통해 어떤 유형의 invalid rationale을 사용하든 CoT의 성능을 큰 폭으로 향상되었음을 알 수 있습니다. 따라서 contrastive demonstration을 사용하면 언어 모델의 추론 능력을 크게 개선할 수 있다는 사실을 알게 되었습니다.
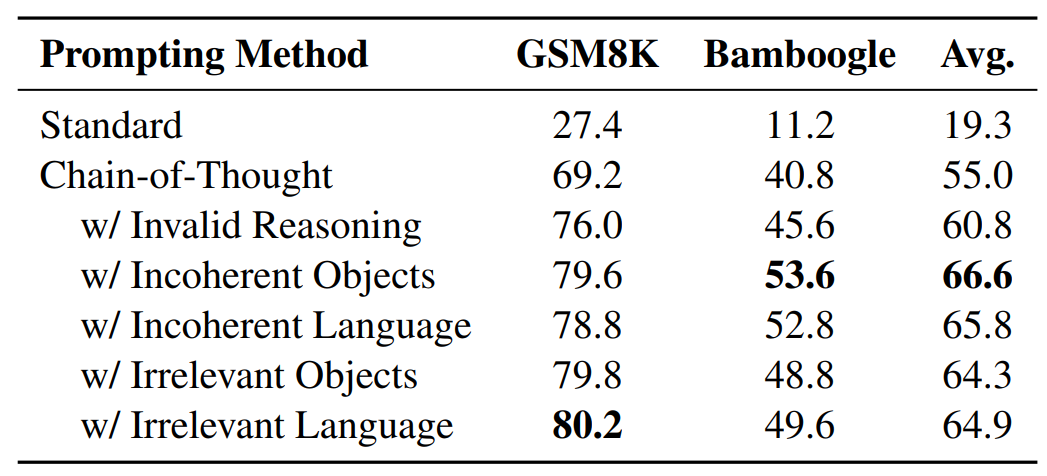
3. Contrastive Chain of Thought
앞선 실험을 바탕으로 저자는 contrastive chain of thought와 함께 contrastive demonstation을 자동으로 생성할 수 있는 방법을 제안하였습니다. 다음 그림은 이 방법론에 대한 개요를 보여줍니다.
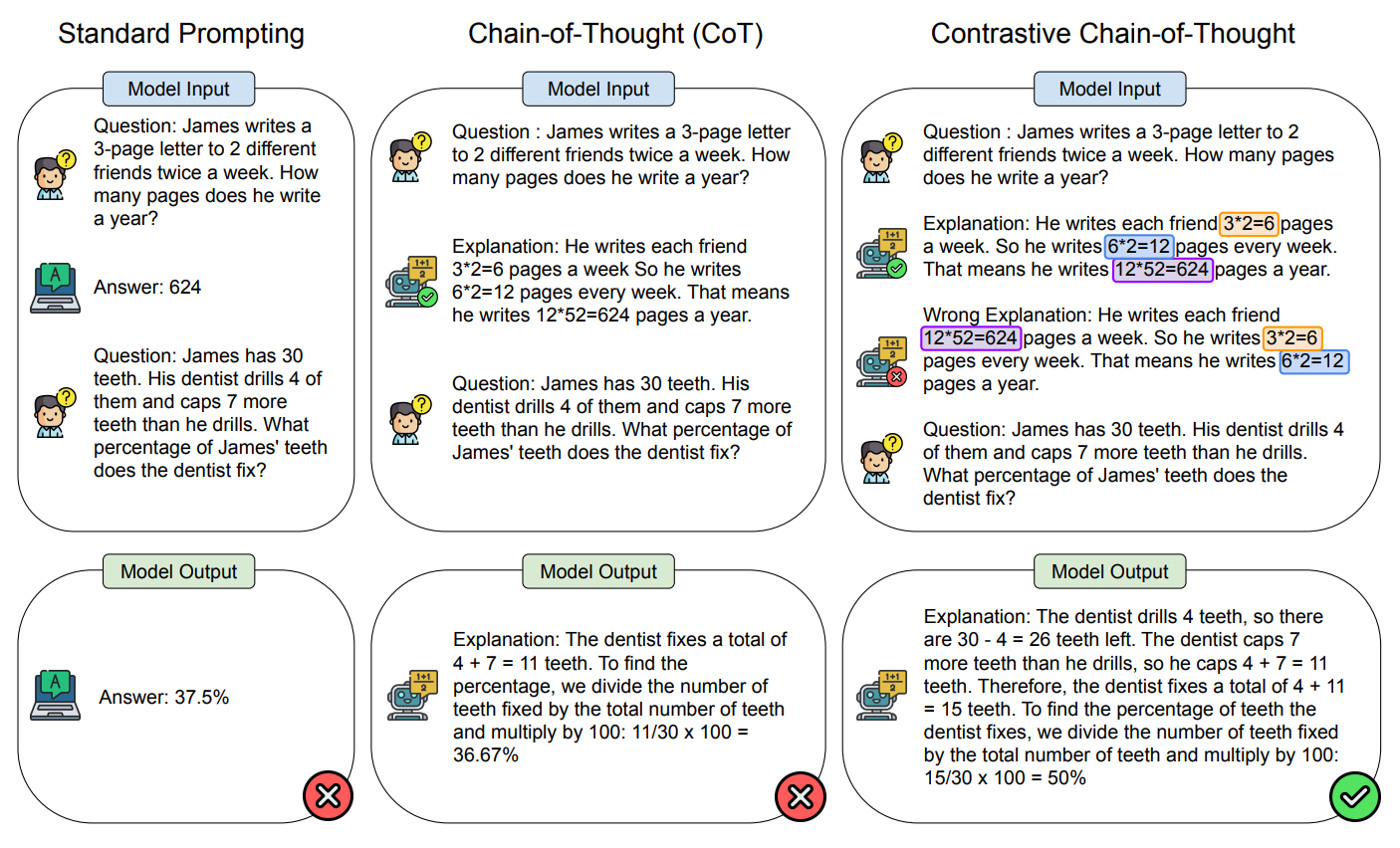
언어 모델에게 질문(question), 올바른 설명(ground truth answer explanation), 올바르지 않은 설명(incorrect answer explanation)이 제공됩니다. Standard prompting과 비교하여 이 방법은 문제를 중간 단계로 분해함으로써 모델이 복잡한 문제를 잘 풀 수 있게 합니다. 또한 기존의 CoT와 비교해서는, 유효한 설명과 유효하지 않은 설명을 모두 제공함으로써 모델이 정확한 논증 과정을 거칠 수 있도록 합니다.
기술적으로 표현하면 n개의 in-context demonstration 예시인 D=E1,…,E|n|와 질문 Q가 주어지면 모델의 목표는 적절한 응답 A를 생성하는 것입니다. 일반적인 프롬프팅에서는 예시에 문제와 정답 Ej=(Qj,Aj)만이 포함되어 있습니다. 반면 CoT는 추론 단계인 T가 추가되어 프롬프트에 Ej=(Qj,Tj,Aj)가 주어집니다. 하지만 기존의 CoT는 모델이 어떤 실수에 주의해서 문제를 해결해야 하는지를 알려주지 않습니다. 따라서 추론 과정에서 실수를 하고 오류가 전파됩니다. 반면 contrastive CoT는 올바른 추론 과정과 올바르지 않은 추론 과정을 모두 포함한 예시인 Ej=(Qj,Tj,+,Aj,+,Tj,−,Aj,−)가 프롬프트에 주어집니다.
올바른 추론인 T+를 얻기 위해서는 기존 CoT와 같이 직접 annotate를 수행하였습니다. 반면 올바르지 않은 추론인 T−는 T+를 사용하여 자동으로 생성하였습니다. 이는 잘못된 추론의 5가지 유형 중 하나인 Incoherent Objects에 기반하였는데, 개체 탐지 모델을 사용하여 숫자, 수식, 사람과 같은 개체를 추출하고 해당 객체들의 순서를 임의로 섞었습니다. 이를 통해 T−를 자동으로 생성할 수 있었습니다.
4. Experiments
4.1 Experiments Setup
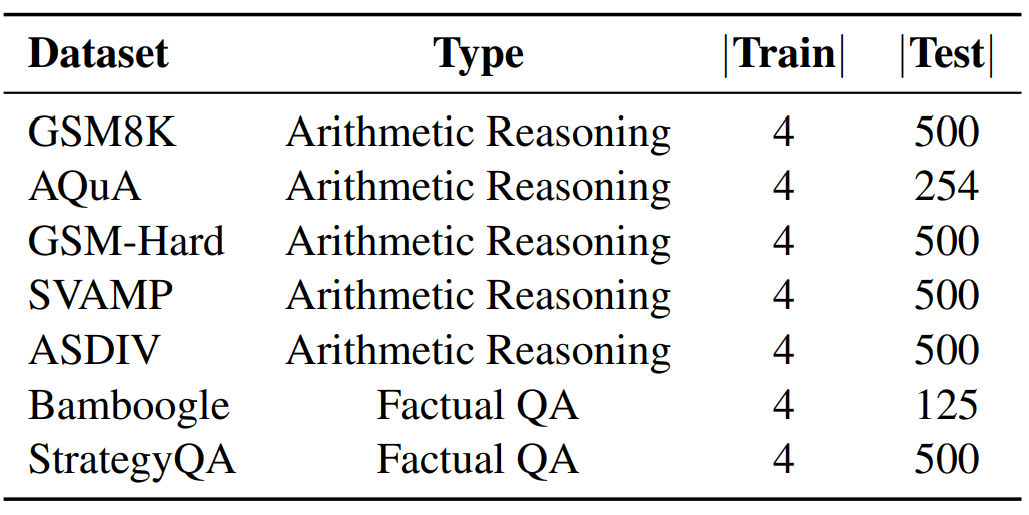
Contrastive CoT 설계 과정에서 수행한 실험과 같이 성능 검증에는 산술 추론과 사실 기반 QA 태스크가 사용되었습니다. 산술 추론에는 GSM8K와 AQuA, GSM-Hard, SVAMP, ASDIV 데이터셋이 사용되었습니다. Factual QA에는 Bamboogle과 StrategyQA 데이터셋을 사용하였습니다. 각 데이터셋에서 최대 500개의 데이터만을 사용하였고, 개수가 500개 미만인 경우 모든 데이터를 사용하였습니다.
4.2 Main Results
실험 결과는 다음과 같습니다.
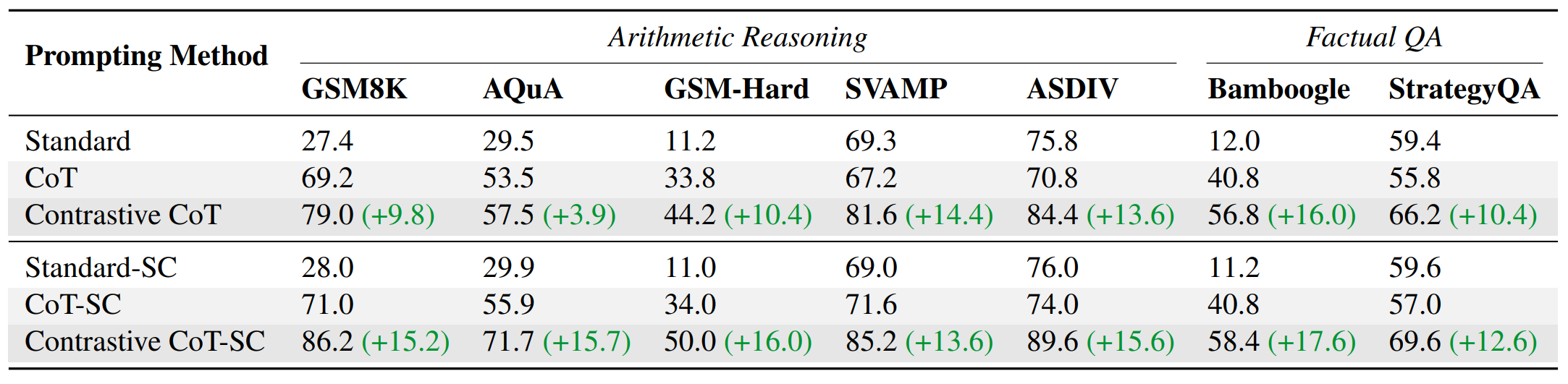
Contrastive CoT demonstrates consistent improvements over conventional CoT
Contrastive CoT가 모든 실험에서 CoT보다 뛰어난 성능을 보임을 알 수 있습니다. 또한 이 방법에서 음성 샘플을 자동으로 생성할 수 있다는 점에서 프롬프트 제작 비용도 CoT와 같다는 점에서 CoT를 단점만을 보완하였다고 볼 수 있습니다.
Contrastive CoT is more effective when applied with self-consistency
Self consistency는 CoT의 성능을 향상하는 유명한 디코딩 전략입니다. 실험을 통해서 SC와 Contrastive CoT를 함께 사용하면 성능이 한층 더 개선됨을 확인하였습니다.
5. Related Work
Large Language Models
최근 연구를 통해 언어 모델과 학습 데이터셋의 규모가 커지면 모델의 일반화 성능이 크게 개선된다는 것이 밝혀졌습니다. 게다가 LLM에 적절한 프롬프트와 데모가 주어지면 학습하지 않은 태스크마저도 잘 수행함이 입증되었습니다. 이를 통해 언어 모델을 추가적인 학습 없이 사용하는 새로운 패러다임이 제안되었습니다. 하지만 이내 단순히 모델 규모만 무작정 키워서는 어려운 추론 문제를 해결할 수 없다는 것이 알려졌습니다. 따라서 이 논문에서는 대규모 언어 모델의 추론 능력을 프롬프트만을 사용하여 향상하는 방법을 연구하였습니다.
Chain of Thought
CoT prompting은 중간 단계를 생성함으로써 언어 모델의 추론 능력을 향상하는 방법입니다. 이 연구를 시작으로 단계별 논증(step-by-step reasoning)에 대한 연구가 여럿 이루어졌습니다. 예를 들어서 automatic chain of thought라는 연구에서는 CoT 데모를 자동으로 생성하는 방법을 제안하였습니다. 또한 “Let’s think step-by-step”과 같은 특정한 문구를 사용하면 제로샷 환경에서 언어 모델의 추론 능력이 향상됨이 밝혀지기도 하였습니다. CoT에 대한 여러 연구에도 불구하고 우리는 기저에 깔린 메커니즘을 정확히 이해하고 있지는 않습니다. 이 연구에서는 invalid demonstration을 통해서도 언언어 모델의 추론 능력이 향상되었다는 연구에 영감을 받아 contrastive CoT를 제안하였습니다. 이를 통해 CoT에 대한 새로운 연구 방향성을 제시하였습니다.
Learning from Negative Examples
잘못된 풀이를 통해 학습하는 방법이 아예 새로운 것은 아닙니다. Contrastive learning을 통해 더 나은 표현을 학습하는 방법은 2020년에 제안되었습니다. 이와 비슷하게 RLHF는 잘못된 풀이에 대해서는 낮은 보상을, 정답에 대해서는 높은 보상을 얻는 방법을 통해 학습합니다. 이러한 기존 연구에 착안하여 CoT를 개선할 수 있는 일반적인 방법론인 contrastive CoT가 탄생하게 된 것입니다.
6. Conclusions
이 논문에서 저자는 잘못된 추론 예제를 사용하여 Chain of Thought의 성능을 향상하는 방법을 탐구하였습니다. CoT에 대한 사전 연구를 통해 잘못된 추론을 유형화하였고 올바른 추론과 잘못된 추론을 대조적인 방법(contrastive manner)를 사용하여 함께 제시하면 언어 모델의 추론 능력이 개선됨을 확인하였습니다. 이 때 잘못된 추론 예시를 생성하는 비용 문제를 해결하기 위해서 기존의 CoT 프롬프트를 사용하여 자동으로 contrastive CoT 프롬프트를 생성하는 방법을 제안하였습니다. 그리고 다양한 추론 태스크에서의 검증을 통해 이 방법이 CoT의 성능을 개선하는 일반적인 방법론임을 입증하였습니다. 또한 저자는 이를 통해 언어 모델의 추론 능력을 개선하기 위한 또 다른 유형의 CoT 프롬프트에 대한 연구가 이루어지기를 기대합니다.
7. Reflection
Contrastive Chain of Thought가 등장하게 된 원인은 결국 Chain of Thought를 통해 언어 모델의 추론 능력을 성공적으로 향상시키기는 했지만, 어떤 이유에서 이것이 가능한지에 대해서 제대로 알지 못했기 때문입니다. 사실 이런 점에서 프롬프트 엔지니어링은 딥러닝 모델의 해석 가능성을 한층 더 어렵게하는 연구가 아닌가 싶기도 합니다. 이미 블랙박스로 여겨지는 딥러닝 모델의 추론 과정을 프롬프트를 통해서 조작할 수 있다는 사실이 밝혀져 활발히 연구되는데, 그게 왜 가능한지마저도 알려지지 않았습니다. 저도 이런 점에서 프롬프트 엔지니어링이 과연 올바른 연구 패러다임인가에 대해서는 아직 물음표를 띄우고 있지만, 현재 딥러닝 분야는 실용적인 학문으로 발전하고 있기 때문에 아직은 일단은 성능 향상에 집중하는 단계인 것 같습니다.
이 논문이 이런 문제를 지적하고 CoT를 개선하는 방법을 연구한 것은 좋았지만, 여전히 CoT의 원리를 밝혀내지 못한 점은 아쉽게 느껴집니다. Contrastive learning을 최초로 제안한 연구에서는 이 학습 방법이 유효한 원리를 제대로 제시하였는지 아직 해당 논문을 읽지 않아서 잘 모르겠지만, 적어도 이 논문에서는 contrastive demonstration이 유용한 이유를 밝히지 않은 것 같습니다. 나름의 이론적 근거는 제시하였지만 여전히 제안한 방법론의 유용성을 실험적으로만 증명했다는 점에서 프롬프트 엔지니어링의 한계가 느껴진다고 생각하였습니다.




댓글