
최근 언어 모델의 트렌드는 자기 회귀적인 사전 학습 목표를 통해 훈련된 GPT와 같은 생성형 모델에 대한 연구에 집중되어 있습니다. 그런데 GPT와 양대산맥을 이루고 있는 언어 모델이 또 하나 있었는데 바로 BERT입니다. BERT는 Bidirectional Encoder Representation from Transforemers의 앞 글자를 따 이름붙인 모델로 GPT와 같이 단방향이 아닌 양방향으로 텍스트를 학습합니다. 그래서 조금 색다른 학습 목표를 갖고 있는데 바로 문장 중간에 마스킹된 토큰이 원래 어떤 단어였는지를 예측하는 방식으로 학습되었습니다. BERT는 어텐션 메커니즘을 기반으로 하기 때문에 내재적으로 해석 가능성을 가집니다. 그래서 BERT가 등장한 이후 모델이 무엇을 학습하였는지에 대한 이해를 하려는 시도가 많이 이루어졌습니다. 이번에 리뷰할 논문인 What does BERT learn about the structure of language?도 마찬가지입니다. 논문의 저자는 BERT의 각 레이어가 언어의 어떤 특성을 학습했는지를 면밀히 분석합니다. 그러면 BERT는 어떻게 언어적 특성을 이해하고 여러 다운스트림 태스크에서 이를 바탕으로 과제를 수행하는지 알아보겠습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Introduction
Bidirectional Encoder Representation from Transformers의 줄임말인 BERT는 문맥을 바탕으로 마스킹된 토큰이 원래 어떤 토큰이었는지와 주어진 두 입력 문장이 자연스럽게 이어지는지를 함께 예측하며 학습된 트랜스포머를 기반으로 한 언어 모델입니다. 사전 학습된 모델은 아키텍처의 변형 없이 여러 다운스트림 NLP 태스크로 파인튜닝이 될 수 있으며 여러 태스크에서 뛰어난 성능을 보였습니다. 이런 놀라운 성과는 BERT가 언어에 대한 구조적인 정보를 학습했음을 의미합니다.
BERT가 학습한 언어학적 구조(proto-linguistic structure)가 무엇인지를 밝힐 수 있을까요? 이 질문에 대답할 수 있게 되면 우리는 BERT가 성공한 이유가 무엇인지, 그리고 BERT가 갖는 한계가 무엇이며 이를 발전시키기 위해서는 어떤 개선점이 필요한 지를 알 수 있습니다. 이 질문은 NLP에서 떠오르고 있는 화두인 신경망의 해석 가능성과 연관이 있습니다. Goldberg는 이와 관련하여 BERT가 문장의 주술 관계를 이해하고 있는지를 평가한 연구를 통해 BERT가 통사론적인 현상을 잘 포착한다는 것을 밝혔습니다.
이 논문에서 저자는 BERT의 각 레이어에서 무엇이 학습되었는지를 분석하기 위한 일련의 실험을 수행하였습니다. 이를 통해 하위 레이어에서는 구문 수준의 정보를 포착하며 이런 정보는 상위 레이어로 갈수록 희석된다는 것을 발견하였습니다. 또한 BERT가 언어 정보를 단계적으로 포착하여, 하위 레이어에서는 표면 정보(surface features), 중간 레이어에서는 통사론적 특성(syntactic features), 상위 레이어에서는 의미론적 특성(semantic features)를 학습한다는 것을 밝혔습니다. 그리고 BERT가 주술 관계를 이해하는지를 평가한 실험을 통해 장기 의존성과 같이 복잡한 문제를 다루기 위해서는 더 많은 레이어가 필요함을 발견하였습니다. 마지막으로 논문에서는 Tensor Product Decomposition Network(TPDN)을 사용하여 BERT가 학습한 언어 정보가 트리 구조와 같이 나타난다는 것을 보였습니다.
2. BERT
BERT는 트랜스포머 네트워크를 기반으로 하여 양방향으로 표현을 학습하도록 사전 훈련되었습니다. 학습 과정에서 BERT는 임의로 마스킹된 단어와 두 문장이 서로 이어지는지를 동시에 예측하며 표현을 최적화하였습니다. BERT의 저자는 양방향성(bidirectionality) 덕분에 모델이 아키텍처를 거의 바꾸지 않으면서도 여러 다운스트림 태스크에 빠르게 적응할 수 있었다고 주장합니다. 실제로 BERT는 여러 NLP 벤치마크에서 기존 SOTA 점수와 큰 격차를 벌리며 최고의 성능을 보였습니다.
이 연구에서 저자는 BERT의 표현에 내재된 언어적 구조를 면밀히 조사하였습니다. 실험에는 PyTorch로 구현한 BERT를 사용하였으며, 사용한 모델은 bert-base-uncased입니다. 이 모델은 12개의 레이어로 이루어지며 각각은 768개의 차원을 갖고 12개의 어텐션 헤드로 구성됩니다.
3. Phrasal Syntax
ELMo 논문에서는 LSTM에 기반한 언어 모델이 학습한 표현이 구문 수준의 정보를 이해한다는 것을 보였습니다. 이러한 사실이 BERT와 같이 전통적인 언어 모델링 기법과는 다르게 학습된 모델에도 적용되는지는 알려지지 않았습니다. 그렇다고 하더라도 학습된 정보가 여러 레이어에 걸쳐 나타날 지는 확실하지 않습니다. 이러한 질문에 답하기 위해 저자는 BERT의 각 레이어에서 부분 표현(span representation)을 추출하여 조사하였습니다. 토큰 시퀀스 $s_i,\dots, s_j$가 주어졌을 때 $l$번째 레이어의 부분 표현 $\mathbf s_{(s_i,s_j),l}$은 첫 번째 은닉 벡터 $\mathbf h_{s_i,l}$와 마지막 은닉 벡터 $\mathbf h_{s_j,l}$를 연결(concatenate)하거나,원소끼리의 곱 또는 차로 나타낼 수 있습니다. 저자는 CoNLL 2000 chunking 데이터셋에서 임의로 500개의 span과 3000개의 레이블이 된 청크를 선택하였습니다.

CoNLL2000 chunking 데이터셋은 위와 같은 데이터로 이루어져있습니다. 전체 문장을 분석한 이미지는 잘 보이지 않아서, 문장 중간에서 임의로 잘랐습니다. 각 토큰마다 pos와 chunk가 태깅되어 있는데, pos는 형태소(part-of-speech)를 의미하며 chunk는 어떤 형태의 구문(phrase)에 해당하는지를 의미합니다. 예를 들어 is widely expected to는 21, 22로 태깅되어 있는데 각각 B-VP, I-VP에 해당하며, BIO 태깅을 사용하여 동사구(Verb Phrase)의 시작과 포함됨을 의미합니다.
다음 그림은 고차원 데이터를 차원 축소하는 비선형 알고리즘 중 하나인 t-SNE를 사용하여 부분 표현을 시각화한 것입니다. BERT가 하위 레이어에서 구문 수준의 정보를 포착하지만 이런 정보가 상위 레이어로 갈수록 희석된다는 것을 알 수 있습니다. 하위 레이어의 부분 표현은 같은 카테고리에 속하는 청크를 가까이 위치시킵니다.

$k=10$으로 한 $k$ 평균 클러스터링한 결과는 앞에서 분석한 내용을 뒷받침합니다.. 여기서 $k$는 서로 다른 청크 유형의 개수입니다. 결과적으로 생성된 클러스터를 Normalized Mutual Information(NMI) 지표를 통해 분석한 결과 하위 레이어가 상위 레이어보다 구문 정보를 잘 인코딩함을 입증하였습니다.

4. Probing Tasks
프로빙 태스크는 신경망이 학습한 언어적 특성이 무엇인지 밝혀내는 데 좋은 수단입니다. 프로빙 태스크는 모델의 최종 출력을 사용하여 어떤 언어 현상의 결과를 예측하는 보조적인 분류 태스크(auxiliary classification task)의 일종입니다. 보조 분류기가 언어적 특성을 잘 예측한다면 원본 모델이 해당 특성을 잘 학습했을 것입니다. 논문에서는 프로빙 태스크를 사용하여 모델의 개별 레이어가 학습한 서로 다른 언어적 특성을 분석했습니다. 저자는 10개의 문장 수준에서의 데이터셋과 태스크를 사용하여 BERT의 각 레이어를 분석하였습니다. 태스크는 세 가지로 구분될 수 있는데 첫 번째는 surface task이며 문장 길이를 예측하는 $\texttt{SentLen}$과 단어의 존재 유무를 판단하는 $\texttt{WC}$입니다. 다음은 통사론적 태스크로 단어 순서 이해도를 평가하는 $\texttt{BShift}$, 구문 트리의 깊이를 판단하는 $\texttt{TreeDepth}$, 구문 트리의 최상위 구성 요소를 예측하는 $\texttt{TopConst}$가 있습니다. 마지막은 의미론적 태스크로 강세를 판단하는 $\texttt{Tense}$, 주절의 명사 또는 목적어의 개수를 예측하는 $\texttt{SubjNum}$과 $\texttt{ObjNum}$, 임의로 교체된 명사 또는 동사를 예측하는 $\texttt{SOMO}$와 문장 내에서 절의 순서가 임의로 반전되었을 때 이를 감지하는 $\texttt{CoordInv}$가 있습니다. 평가에는 SentEval toolkit이 사용되었습니다. 기존 연구에서 임의의 인코더도 여러 의미론적, 구조적 정보를 학습하고 있다는 사실이 밝혀졌기 때문에 가중치가 임의로 초기화된 학습되지 않은 BERT도 비교군으로 사용하였습니다.
다음 표는 BERT가 언어적 특성을 계층적으로 잘 학습하였음을 보여줍니다. 표면적인 정보는 하위 레이어에서, 구문론적 정보는 중간 레이어에서, 그리고 의미론적 정보는 상위 레이어에서 잘 학습되었습니다. $\texttt{BShift}$와 $\texttt{CoordInv}$의 두 태스크에서는 기존에 알려진 결과보다 더 높은 점수를 보였습니다. 또한 학습되지 않은 BERT의 상위 레이어는 문장 길이 예측 태스크를 학습된 BERT보다 잘 수행하였습니다. 이는 문장 길이와 같이 기초적인 언어적 특성은 학습되지 않은 모델에도 인코딩되어 있으며 오히려 학습에 의해 복잡한 정보를 저장하면서 이와 같은 기본적인 특성에 대한 정보를 잃는다는 것을 의미합니다.

표에서 괄호 안의 숫자는 untrained BERT와의 차이를 의미합니다. SentLen 태스크를 다시 보면 상위 레이어로 갈수록 학습된 BERT가 더 낮은 점수를 받았음을 확인할 수 있습니다.
5. Subject-Verb Agreement
주어-동사 일치는 신경망 모델이 구문을 잘 이해하는지를 평가하는 태스크입니다. 주어와 동사 사이에 더 많은 명사가 놓일수록 모델은 동사의 개수를 예측하기 어려워합니다. 논문에서는 이러한 명사를 attractor라고 표현하였습니다. Goldberg의 2019년 연구는 BERT가 주어 동사 일치를 놀라울 정도로 잘 학습한다고 밝혔습니다. 논문에서는 해당 연구를 확장하여 BERT의 각 레이어에 대한 평가를 수행했습니다.
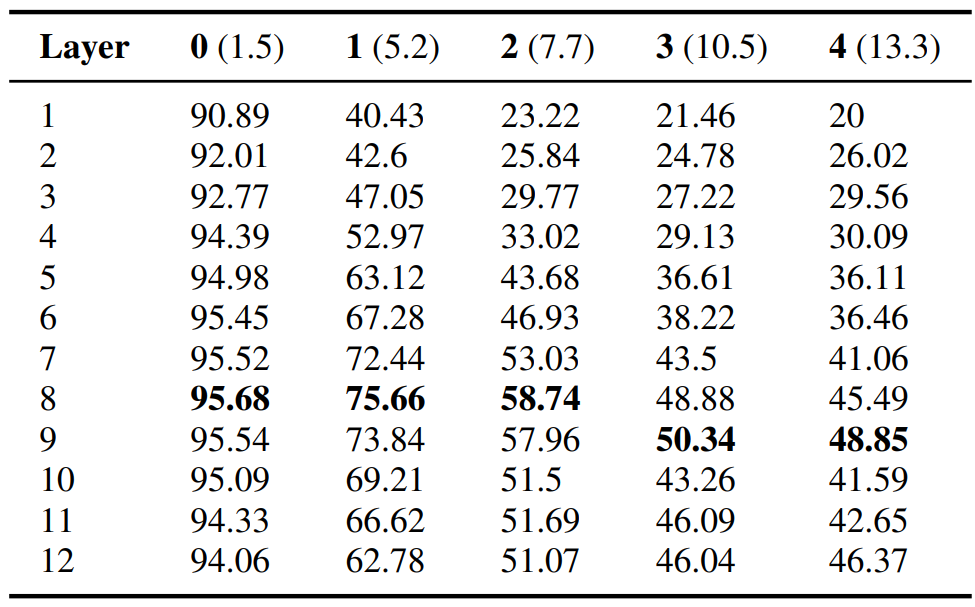
다음 표는 대부분의 경우 중간에 위치한 레이어에서 높은 성능을 보임을 알 수 있습니다. 이는 앞에서 언급한 구문론적 특성이 중간에 있는 레이어에서 잘 학습된다는 분석을 뒷받침합니다. 흥미롭게도 attractor의 숫자가 늘어날수록 주어와 동사 사이에 놓이는 단어들의 개수가 많아지고 그에 따라 문장이 길어지는데, 이 때 중간에 위치한 레이어(7번째)보다 오히려 상위의 BERT 레이어(8번째)가 장기 의존성을 잘 학습했다는 점입니다. 이는 복잡한 NLP 태스크를 수행하기 위해서는 BERT에 더 많은 레이어가 필요함을 의미합니다.
6. Compositional Structure
저자는 Tensor Product Decomposition Network(TPDN)을 사용하여 BERT의 compositional nature을 이해하려고 하였습니다. 참고로 이 표현에 대한 적절한 번역을 떠올리지 못했는데, 논문에서 기술적으로 풀이한 개념 자체가 조금 복잡합니다. 굳이 쉽게 설명하자면 모델이 학습한 개념을 어떤 구조로 표현할 수 있는가를 분석한 것입니다. 결론적으로 여기서는 BERT가 학습한 개념들을 트리 구조로 나타낼 수 있다고 하였습니다. 예를 들어 어떤 단어의 역할(role scheme)은 구문 트리에서 루트 노드에서 자기 자신까지의 경로와 관련이 있습니다. 저자는 만약 어떤 역할이 주어졌을 때 TPDN이 신경망이 학습한 표현에 근사하도록 훈련될 수 있다면 이를 통해 모델이 암시적으로 학습한 compositionality를 구체화할 수 있다고 가정하였습니다. 각 BERT 레이어에 대하여 저자는 다섯 가지 서로 다른 role scheme을 사용하였습니다. 각각 left-to-right 인덱스, right-to-left 인덱스, 그리고 앞에서 계산한 두 인덱스의 쌍, 구문 트리에서의 위치와 위치 정보를 사용하지 않는 bag-of-words 방식입니다. 추가로 random binary tree를 사용하였습니다.
TPDN 모델은 SNLI 말뭉치의 전체 문장으로 학습되었고 filler 임베딩은 BERT의 입력 레이어에 사용된 단어 임베딩을 사용하였습니다. 손실함수는 MSE를 사용하였습니다. 다음 표는 BERT와 BERT에 근사하도록 학습된 TPDN 사이의 MSE를 의미합니다. BERT는 암시적으로 트리에 기반한 scheme을 따르기 때문에 같은 scheme을 사용한 TPDN이 대부분의 레이어에서 BERT와 가장 유사하다는 것을 발견하였습니다. BERT가 어텐션 메커니즘을 사용함에도 불구하고 트리와 같은 고전적인 구조로 정보를 인코딩한다는 점에서 상당히 놀라운 결과입니다.

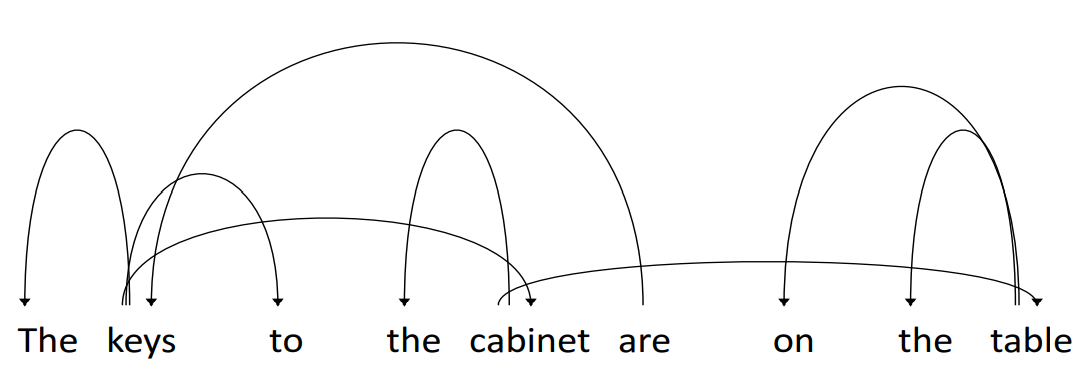
이 연구에서 영감을 받아 구문 분석 트리를 사용한 케이스 스터디를 수행하였습니다. 다음 그림은 두 번째 레이어의 11번째 어텐션 헤드에서 사용된 어텐션 가중치를 바탕으로 dependency를 분석한 결과입니다. 지시자와 명사 사이의 의존성(the keys, the cabinet, the table)과 주어와 동사 의존성(keys are)이 정확하게 포착된 것을 확인할 수 있습니다. 놀랍게도 key, cabinet, table의 연쇄적인 의존성을 통해 predicate-argument 구조 또한 부분적으로 학습되었음을 알 수 있습니다.
7. Conclusion
논문의 연구는 최근 유행하고 있는 언어 모델의 해석 가능성에 기여했습니다. 저자는 BERT가 영어의 구조적 특성을 잘 이해하고 있음을 밝혔습니다. 연구 결과를 통해 BERT에 기반한 모델에서 얻은 부분 표현이 구문에 대해 풍부하게 이해하고 있음을 밝힌 Goldberg, Hewitt, Liu, Tenney의 연구를 뒷받침하였습니다. 또한 BERT가 계층적으로 언어적 특성을 학습하며 장기 의존성을 잘 학습하기 위해서는 더 많은 레이어가 필요함을 보였습니다. 마지막으로 BERT의 내부 표현이 전통적인 구문 분석 방식과 같은 구조를 띈다는 것을 보였습니다.
8. Reflection
이 논문은 길이가 길진 않지만 뒤에 나오는 내용이 상당히 생소해서 생각보다 리뷰하는 데 오래 걸린 것 같습니다. 원래는 TPDN이나 몇 가지 배경지식에 대한 설명을 리뷰에 포함하고 싶었지만, 생각보다 완성도 있는 리뷰를 작성하지 못해서 아쉽습니다. 나중에 해당 내용들을 따로 다뤄볼 생각입니다. 사실 이 논문에서 다룬 내용은 대부분 이전에 리뷰한 contextual embedding 논문들에 나온 내용과 큰 차이가 없습니다. 어떻게 보면 해당 논문들이 contextualized embedding을 사용한 모델이 학습한 언어적 특성을 더 자세히 분석했다고 볼 수도 있을 것 같습니다. 그래도 리뷰 차원에서 한 번 읽어볼 만한 논문인 것 같습니다. 이 논문을 읽으면서 든 재미있는 생각은 명시적인 지도 학습 없이도 인공지능 모델이 언어적 특성을 계층적으로 학습했다는 것입니다. 먼저 문장의 길이가 얼마나 되는지, 어떤 단어가 존재하는 지 등을 학습하고, 구문론적 특성을 이해한 후 개별 단어의 의미론적 특성에 주목했다는 점이 흥미롭습니다. 그러니까 언어 모델이 언어에 대한 전반적인 이해를 먼저 수행하고 디테일에 접근했다는 점이 흥미롭습니다. 이런 연구를 통해 사람이 어떻게 하면 새로운 정보를 효율적으로 학습할 수 있을지를 배울 수도 있다는 생각이 들었습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (1) | 2023.12.09 |
|---|---|
| [논문리뷰] Contrastive Chain-of-Thought Prompting (1) | 2023.12.01 |
| [논문리뷰] ReAct: Synergizing Reasoning and Acting in Language Models (0) | 2023.11.24 |
| [논문리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (1) | 2023.11.24 |
| [논문리뷰] Emergent Abilities of Large Language Models (1) | 2023.11.20 |




댓글