
최근 LoRA와 QLoRA 논문을 읽으며 양자화를 비롯한 모델 경량화에 대한 개념에 대해서 조금 공부하였습니다. 기본적으로 모델 경량화가 가능한 이유는 애초에 모델이 필요 이상으로 많은 파라미터를 갖도록 설계되어 있기 때문이며, 고차원 공간을 효율적으로 사용하지 못하고 있음을 의미합니다. 따라서 파라미터를 더 낮은 차원의 공간에 컴팩트하게 분포하게 만듦으로써 모델 성능은 유지하고 크기는 줄일 수 있습니다. 이런 개념이 어쩌면 Distillation이 가능한 이유와도 비슷하다고 생각해서 DistilBERT를 다룬 논문 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter를 읽고 정리하였습니다. 결론적으로는 그 배경에 깔린 개념이 조금은 다르다는 것을 알 수 있었는데, 자세한 내용은 리뷰 본문에서 다뤄보겠습니다.
1. Overview
ULMFiT과 같은 연구 덕분에 NLP 분야에서도 대규모의 사전 훈련된 언어 모델을 통한 전이 학습에 대한 연구가 활발하게 이루어졌습니다. 이런 연구 덕분에 많은 태스크에서 모델의 성능이 크게 향상됐지만, 모델의 규모는 점점 더 커지는 추세입니다. 그리고 계속해서 모델 규모를 늘리고 있음에도 다운스트림 태스크에서 파인 튜닝된 모델의 성능 또한 여전히 계속 좋아지고 있습니다.
그런데 이렇게 모델이 점점 더 커지는 추세는 몇 가지 문제를 낳았습니다. 먼저 기하급수적으로 크기가 증가한 모델의 연산 과정에서 초래된 환경 문제가 있습니다. 그리고 NLP 어플리케이션을 실시간으로 온디바이스 환경에서 제공하려는 시도에서도, 이런 추세는 메모리 요구량 때문에 사용할 수 있는 모델의 종류에 많은 제약을 가하게 됩니다.
이 논문에서는 지식 정제(knowledge distillation)을 통해 사전 훈련된 소규모 모델이 여러 다운스트림 태스크에서 뛰어난 성능을 보일 수 있음을 입증하였습니다. 이러한 모델은 큰 규모의 사전 훈련된 모델보다 성능이 뒤떨어지지도 않으며 추론 과정이 가볍고 빠르며, 학습에 필요한 시간과 비용도 적게 듭니다.
2. Knowledge Distillation
Knowledge Distillation
지식 정제는 학생(student)라고 불리는 컴팩트한 모델이 규모가 큰 교사(teacher) 모델과 같은 성능을 갖도록 하는 모델 압축 기법입니다.
지도 학습에서 분류 모델은 정답에 해당하는 레이블을 예측할 확률을 최대화하도록 훈련됩니다. 따라서 일반적인 훈련 목표는 모델 예측에 대한 분포와 실제 정답에 대한 분포의 크로스 엔트로피를 최소화하는 것입니다. 잘 학습된 모델은 학습 데이터에서 정답 클래스에 대한 확률은 높고 나머지 클래스에 대한 확률은 0에 가까울 것입니다. 하지만 정답이 아닌 클래스에서도 다른 클래스보다는 확률이 높은 경우가 종종 있습니다. 이는 테스트 데이터에서 모델의 일반화 능력을 의미하기도 합니다. 예를 들어서 I think this is the beginning of a beatiful [MASK] 라는 문장에서 BERT는 day와 life라는 토큰에 높은 확률을 부여하는데, 이 외에도 future, story, world 등의 유효한 예측(long tail of valid predictions)에 대해서는 다른 오답 클래스보다는 높은 확률을 부여합니다.
지식 정제에 대한 Geoffrey Hinton의 논문 Distilling the Knowledge in a Neural Network을 간단히 요약하면 다음과 같습니다. 모델의 훈련 목표는 주어진 데이터에 대한 정답 클래스를 올바르게 예측하는 것입니다. 하지만 학습 단계에서는 결국 학습 데이터에 대하여 모델이 최적화되기 때문에, 새로운 데이터에 대한 일반화 여부를 확신하기 어렵습니다. 결국 일반화를 위해서는 사전에 어떻게 하면 일반화된 예측을 할 수 있을지를 염두하고 훈련 목표를 설계해야하지만, 보통은 매우 어렵습니다. 그런데 어떤 앙상블 모델은 서로 다른 모델의 예측을 평균한 것이기 때문에 일반화가 잘 될 것이라고 기대할 수 있고, 그 사실이 실험적으로 입증되기도 했습니다. 지식 정제는 이런 아이디어에서 착안하여, 규모가 큰 모델의 정답 클래스와 정답은 아니지만 다른 클래스보다는 조금 더 높은 확률을 갖는 일부 유효한 예측들을 일종의 앙상블 모델의 예측처럼 생각합니다. 이를 소프트 타겟(soft target)이라고 부르고, 작은 모델의 훈련 목표로 설정하는 것입니다.
Training Loss
학생 모델은 교사 모델의 soft target probabilities에 대한 distillation loss를 학습합니다. 즉, ti와 si가 각각 교사와 학생 모델이 추정한 확률이라고 할 때 Lce=∑itilog(si)를 학습합니다. 이 훈련 목표는 교사 모델의 확률 분포를 사용하기 때문에 더 풍부한 내용을 바탕으로 학습할 수 있게 해줍니다. 앞서 언급한 Hinton의 논문에서와 같이 이 논문에서도 softmax-temperature pi=exp(zi/T)∑iexp(zj/T)를 사용합니다. 수식에서 T는 출력 분포의 smoothness를 조절하며 zi는 클래스 i에 대한 모델의 점수입니다. 학습 단계에서 교사와 학생 모델에는 같은 값의 T를 사용하지만, 추론 단계에서는 T을 1로 설정하여 전체 수식이 softmax함수와 같은 역할을 하도록 합니다.
최종적인 훈련 목표는 distillation loss Lce와 지도 학습에 사용되는 훈련 손실의 선형 결합입니다. 여기서 지도 학습 손실은 BERT와 같이 maksed language modeling loss Lmlm을 사용하였습니다. 또한 cosine embedding loss Lcos를 추가하면 교사와 학생 모델의 은닉 상태 벡터가 잘 align된다는 사실을 발견하여 이 손실도 함께 사용되었습니다.
3. DistilBERT: a distilled version of BERT
Student Architecture
이 연구에서 학생 모델인 DistilBERT는 BERT와 기본적으로 같은 아키텍처를 갖지만, token-type embedding과 pooler가 제거되었고, 레이어의 개수를 절반으로 줄였습니다. 트랜스포머 아키텍처에서 수행되는 대부분의 연산은 고도로 최적화할 수 있기 떄문에, 은닉 차원은 레이어 개수에 비해 연산 효율에 큰 영향을 미치지 않는다는 것을 발견하였습니다. 따라서 레이어의 개수를 줄이는 것에 중점을 두었습니다.
Student Initialization
최적화와 아키텍처에 대한 선택 외에 학습 단계에서 sub-network의 수렴을 위해서 초기화하는 방법을 잘 선택하는 것도 매우 중요합니다. 교사와 학생 모델의 common dimensionality에서 오는 이점을 활용하기 위해 교사 모델의 레이어 두 개중 하나를 선택하여 학생 모델을 초기화하였습니다.
Distillation
BERT와 같이 DistilBERT는 gradient accumulation을 사용하여 매우 큰 배치 사이즈로 학습되었고 dynamic masking을 통해 훈련되었습니다. Next sentence prediction은 훈련 목표에서 제외하였습니다.
Data and Compute Power
DistilBERT는 BERT와 같은 학습 데이터인 English Wikipedia와 Toronto Book Corpus를 사용하였습니다. DistilBERT는 V100 GPU 8개에서 약 90시간동안 훈련되었습니다. RoBERTa와 비교하자면 이 모델은 V100 GPU 1024개에서 하루동안 훈련되었습니다.
4. Experiments
General Language Understanding
저자는 GLUE 벤치마크를 사용해 DistilBERT를 평가하였습니다. 멀티태스크 학습이나 앙상블 없이 각 태스크에 대해 파인튜닝된 DIstilBERT를 9개 태스크에서 평가하였고, 베이스라인으로는 ELMo와 BERT-base를 사용하였습니다.
실험 결과는 다음과 같습니다. 모든 태스크에서 ELMo보다 뛰어난 성능을 보이고 BERT보다 40% 적은 파라미터를 갖지만, 성능은 거의 떨어지지 않은 것을 볼 수 있습니다.
4.1 Downstream task benchmark
Downstream task
IMDb 감정 분류, SQuAD 질문 답변과 같은 다운스트림 태스크에서도 DistilBERT의 성능을 평가하였습니다. 다음 표에서 알 수 있듯이, BERT 보다 성능이 크게 뒤떨어지지 않습니다.
또한 저자는 SQuAD 데이터로 파인튜닝한 BERT를 교사 모델로 사용하여, DistilBERT를 SQuAD 데이터셋으로 파인튜닝하는 단계에서 지식 정제를 한 번 더 활용할 수 있는지에 대한 연구를 수행하였습니다. 결국 실험에서는 두 번의 지식 정제가 이루어지는데, 한 번은 사전 훈련 단계에서, 나머지 한번은 적응(adaptation) 단계에서 이루어집니다.
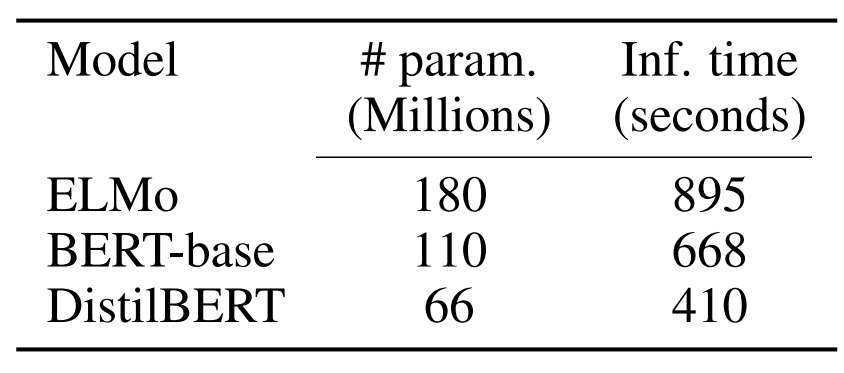
Size and inference speed
DistilBERT의 속도와 크기에 대한 트레이드오프를 분석한 결과는 다음과 같습니다. 추론 시간은 배치 사이즈를 1로 하고 CPU를 사용했을 때, STS-B 검증 데이터 전체에 대한 추론 시간을 의미합니다. DistilBERT는 BERT보다 40% 적은 파라미터를 갖고 60% 빠른 추론 속도를 보입니다.
On device computation
저자는 DistilBERT가 온디바이스 어플리케이션에서 질문 답변 태스크를 수행할 수 있는지를 연구하였습니다. 당시 최신 스마트폰인 아이폰7 플러스 기준으로 토큰화 단계를 제외하고 DistilBERT는 BERT보다 71%만큼 빠른 추론 속도를 보였으며, 경량화 기술이 적용되지 않았음에도 모델 크기는 207MB였습니다.
4.2 Ablation Study
다음 표는 세 개의 손실 함수의 다양한 조합에 따른 정제된 모델의 성능을 보여줍니다. MLM 손실은 큰 영향을 미치지 않는 것을 확인할 수 있습니다. 이 실험의 기준 모델은 세 개의 손실과 교사 모델을 활용하여 가중치를 초기화한 모델입니다.

5. Related Work
Task-specific distillation
기존의 지식 정제는 대부분 특정 태스크에 대한 상황을 가정하였습니다. Tang은 분류 태스크를 위해 파인튜닝한 BERT로부터 LSTM 기반 분류기로의 전이학습을 연구하였습니다. Chatterjee는 SQuAD로 파인튜닝한 BERT를 정제하여 작은 트랜스포머 모델로 만들었습니다. 하지만 이 논문에서는 보다 일반적인 목적으로 사전 훈련된 모델을 정제하는 것이 더욱 유리하다는 것을 입증했습니다.
Multi-distillation
Tang은 Multi-Task Knowledge Distillation을 적용하여 대규모의 QA 모델을 사용하여 컴팩트한 QA 모델을 훈련하였습니다. Tsai는 이 논문과 비슷하게 다중 언어 모델을 사전 훈련하는 방식으로 지식 정제를 연구하였습니다. 반면 이 논문에서는 이에 더하여 추가적인 손실을 결합하고, 교사 모델을 통해 가중치를 초기화하는 기법을 제안하였습니다.
Other compression techniques
Weight pruning과 같은 최신 기법은 테스트 단계에서 셀프 어텐션 헤드를 일부 제거하여도 성능이 크게 저하되지 않음을 보였습니다. 일부 레이어는 헤드를 한 개만 사용할 수도 있습니다. 또한 양자화 기술을 사용하여 모델의 크기를 줄이는 방법도 존재하지만, 두 방법 모두 이 논문의 연구와는 독립적입니다.
6. Conclusion and future work
이 논문에서는 일반적인 목적으로 사전 훈련된 BERT보다 40% 작고, 60% 빠르지만 97%의 성능을 보존하는 DistilBERT를 제안하였습니다. 언어 모델을 지식 정제를 통해 성공적으로 학습할 수 있음을 보였고, edge application에서도 DistilBERT는 매력적인 선택지임을 밝혔습니다.
7. Reflection
결국 정제는 사전 훈련된 모델이 over-parameterized model임을 가정하고 모델 파라미터를 저차원 공간으로 매핑하는 것과는 다른 개념이었습니다. Teacher 모델에서 학습한 예측에 대한 분포를 일종의 앙상블 모델의 예측으로 사용하고, 이를 바탕으로 student 모델을 학습하는 것이 지식 정제인데, 배경에 있는 수학적인 개념이 어떠한지는 구체적으로 알지 못하지만, 벡터의 차원과 관련해서 경량화가 이루어지는 것 같지는 않습니다. 그보다는 일반적인 학습 과정이 이루어짐과 동시에 teacher 모델이 학습한 지식을 참고한다고 보는 게 맞는 것 같습니다. 굳이 벡터의 차원에 비유하자면 애초에 저차원 공간을 갖는 모델이 고차원 공간에서 학습된 teacher 모델의 예측 분포를 저차원 공간에 어떻게 잘 구겨넣을지 고민하며 학습하는 형태라고 이해하였습니다. Knowledge distillation 자체가 기존에 생각한 것과는 조금 다르고, soft target이나 앙상블 같은 키워드와 함께 등장하는 게 조금 의외였어서 관련해서 조금 더 공부하고 정리해봐야 할 것 같습니다.
참고로 이 모델은 이전에 리뷰한 HuggingFace의 transformers 라이브러리에 대한 논문에서 라이브러리를 배포하며 함께 배포되었다고 알고 있습니다. 실제로 저자진도 HuggingFace라고 되어있는데, 관련해서 허깅페이스에서는 이 외에도 자체적으로 어떤 연구를 하고 논문을 출판하고 있는지에 대한 궁금증도 생겼습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (1) | 2023.11.24 |
|---|---|
| [논문리뷰] Emergent Abilities of Large Language Models (1) | 2023.11.20 |
| [논문리뷰] Training language models to follow instructions with human feedback (0) | 2023.11.10 |
| [논문리뷰] Word Translation Without Parallel Data (2) (0) | 2023.11.05 |
| [논문리뷰] Word Translation Without Parallel Data (1) (0) | 2023.11.04 |




댓글