
명시적인 번역 쌍을 사용하지 않고 비지도 학습을 통해 단어나 문장을 번역하는 방법론을 제안한 논문 Word Translation Without Parallel Data를 리뷰해보았습니다. 이 글에서는 이전에 업로드한 논문의 전반부에 이어 실험 결과와 해석에 대한 내용을 다룹니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
4. Experiments
4.1 Evaluation Tasks
Word translation
이 태스크에서는 원본 단어가 주어졌을 때 올바른 번역을 검색하는 문제를 풀어야 합니다. 문제는 사용할 수 있는 bilingual dictionary는 구글 번역기와 같은 온라인 도구를 사용하여 생성되었기 때문에 다의성(polysemy)을 고려하지 않는다는 것입니다. 또 다른 사전은 기계 번역 시스템의 phrase table을 통해 생성되었지만, 이 경우 노이즈가 많고 상대적으로 작은 데이터에서 학습되었다는 문제가 있습니다. 따라서 저자는 이 태스크를 위해서 직접 10만 개의 단어 쌍으로 이루어진 사전을 구축하였습니다. 다음 표는 이 사전을 사용한 실험 결과입니다.
실험에서는 이 사전과 더불어 이전의 모델과 직접적인 비교가 가능하도록 Dinu가 배포한 사전을 함께 사용하였습니다. 각 언어에 대하여 저자는 1500개의 query source와 20만개의 target word를 사용하여 k=1,5,10일때 원본 단어의 번역이 검색된 횟
수를 측정하여 정밀도를 계산하였습니다.
Cross-lingual semantic word similarity
이 태스크에서는 단어 유사도를 바탕으로 cross-lingual word embedding space의 품질을 평가하였습니다. 이 태스크에서는 서로 다른 언어에서 두 단어의 코사인 유사도를 사람이 평가한 점수와 비교하였습니다. 측정 지표로는 피어슨 상관계수가 사용되었습니다.
Sentence translation retrieval
이 태스크에서는 bag-of-words aggregation 기법을 통한 문장 검색을 수행합니다. Bag-of-words aggregation은 주어진 문장을 단어의 순서와 관계없이 그 문장을 구성하는 단어들의 집합으로 표현하는 방법입니다. 단어 번역과 마찬가지로 2천 개의 원본 문장에서 k=1,5,10일 때의 검색 정밀도를 계산합니다. 문장 임베딩은 단어의 IDF 가중 평균을 통해 계산되었습니다.
4.2 Results and Discussion
Baselines
실험에서는 Procrustes 공식의 해를 사용하는 모델을 supervised baseline으로 사용하였습니다. 이 베이스라인은 NN, ISF, CSLS와 함께 사용될 수 있습니다.
Cross-domain similarity local scaling
이 모델은 이웃의 개수를 정의하는 파라미터 K만을 사용합니다. 그런데 K=5,10,50 각각의 실험에서의 성능 차이가 크지 않았기 때문에 최종적으로 K=10을 사용하였습니다. Word translation 태스크의 결과를 통해 CSLS의 강력한 성능을 확인할 수 있습니다. 게다가 CSLS는 ISF보다 성능이 뛰어날 뿐만 아니라 연산도 빠르고 하이퍼 파라미터 튜닝도 필요하지 않습니다.
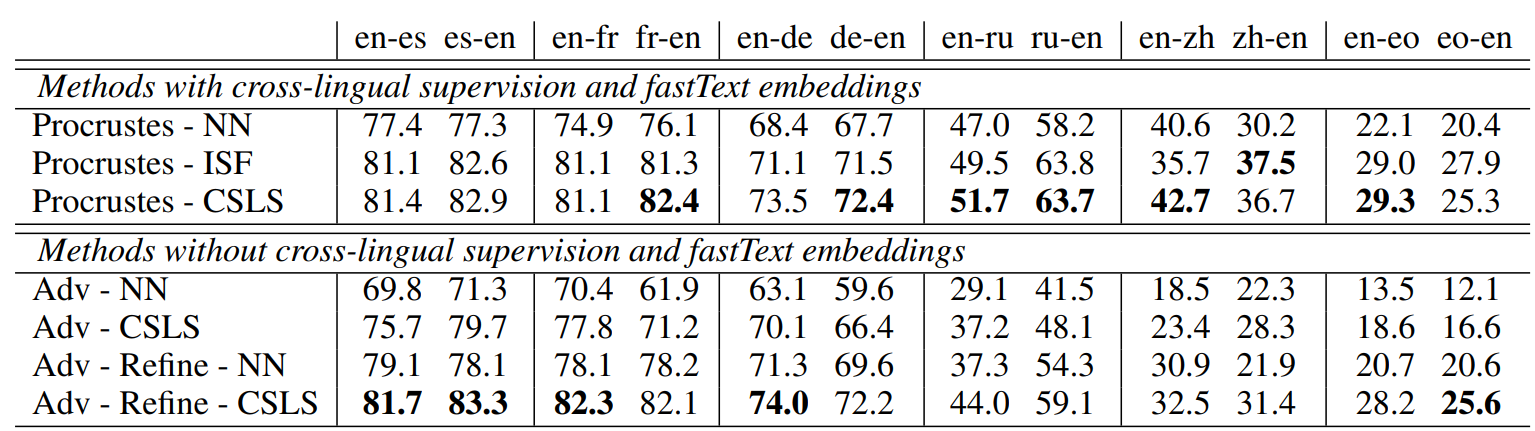
Impact of the monolingual embeddings
다음 표에서 알 수 있듯이 단어 번역 태스크에서 WaCky 데이터셋으로 학습된 CBOW 임베딩을 사용하는 것보다 Wikipedia로 학습된 fastText 임베딩을 사용하는 것이 훨씬 더 좋은 결과를 보였습니다. 그런데 같은 데이터셋을 사용하여 비교해본 결과, 이는 각 임베딩의 학습 방법보다는 데이터셋의 차이에 의한 성능 차이임을 알 수 있었습니다.
Adversarial approach
이 실험 결과는 또한 적대적 학습 방법이 parallel data 없이도 얼마나 뛰어난 성능을 보이는지를 알 수 있게 해줍니다. 심지어 이 방법은 영어-러시아어(en-ru)와 영어-중국어(en-zh)와 같이 공통된 알파벳을 사용하지 않는 단어 간의 번역에서도 상당히 준수한 성능을 보입니다. 게다가 이 결과는 CSLS를 사용하면 한층 더 나아졌습니다.
Refinement: closing the gap with supervised approaches
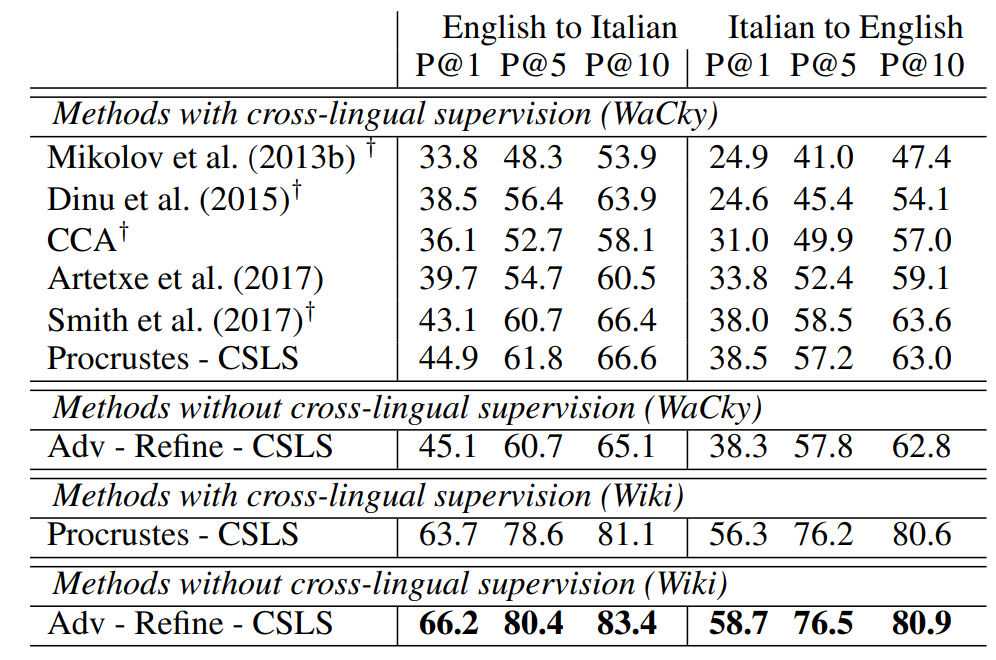
적대적 학습 후에 refinement step을 거치며 구축된 synthetic bilingual vocabulary는 이 실험의 결과를 한층 더 개선하며 supervised baseline과의 격차를 유의미하게 좁혔습니다. 표를 다시 보면 영어-이탈리어어(en-it) 실험 결과에서는 심지어 비지도 학습법을 사용한 모델이 supervised basline보다 더 뛰어난 성능을 보였습니다.
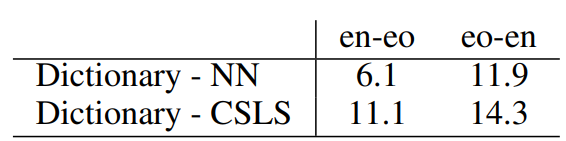
Application to a low-resource language pair and to machine translation
논문에서 제안한 방법은 데이터가 많지 않은 언어에 특이 유용합니다. 실제로 영어-에스페란토어 적용해본 결과 지도 학습을 사용했을 때의 정확도인 29.3%에 크게 뒤지지 않는 28.2%의 정확도를 달성할 수 있었습니다. 반대로 에스파렌토어-영어 태스크에서는 25.6%의 정확도로 지도 학습을 사용했을 때보다 1.3% 만큼 성능이 좋았습니다. 참고로 이 실험에서는 온라인 사전을 사용했기 때문에 다의어를 반영하지 못해서 실험 정확도가 다른 언어에 비해 특히 낮다는 것을 고려해야 합니다.
이를 통해 구축한 사전이 기계 번역 태스크에 어떤 영향을 미치는지 알아보기 위한 실험을 진행하였습니다. 실험의 측정 지표로는 BLEU 점수가 사용되었습니다.
5. Related Work
Parallel corpora를 사용하지 않는 bilingual lexicon induction에 대한 연구의 꽤 긴 역사를 갖고 있습니다. 1995년 Rapp의 연구는 이 논문의 연구와 비슷하지만 분산 표현을 사용하지 않고 이산 표현인 TF-IDF 벡터를 사용한다는 차이점이 있습니다. 이후 통계적 유사도를 바탕으로 사전을 구축하는 여러 연구가 수행되었습니다. 하지만 이들은 모두 seed bilingual lexicon을 필요로 한다는 한계가 있습니다.
단어 임베딩이 등장하면서 이런 접근법은 aligning vocabulary에서 aligning embedding space의 문제로 전환되었습니다. Cross-lingual word embedding은 원본 단어의 최근접 이웃을 계산하는 방법으로 bilingual lexicon을 구축할 수 있게 합니다. 그리고 앞에서 언급했듯 orthogonality constraint를 추가하고 Procrustes approach를 사용하며 이 연구는 계속해서 개선되었습니다.
이 과정에서 Cross-lingual 단어 임베딩 공간의 hubness problem을 해결하기 위한 연구도 수행되었습니다. 이 논문에서 제안한 CSLS와 유사하게 inverted-softmax를 사용하는 방법이 하나의 예시입니다.
앞선 연구는 모두 bilingual lexicon을 필요로 한다는 한계가 있는데, 2017년 Smith는 identical character string을 사용하여 지도 학습을 거의 사용하지 않고 사전을 구축하는 방법을 제안하였습니다. 하지만 여전히 일부 지도학습된 단어쌍이 필요할 뿐만 아니라 공통된 알파벳을 갖지 않은 단어 사이에서는 사용할 수 없다는 한계가 있었습니다.
2017년 Zhang은 지도학습을 전혀 사용하지 않고 적대적 학습을 사용하여 monolingual word vector space를 align하는 연구를 수행하였습니다. 하지만 이 연구는 논문의 내용과는 여러 면에서 다릅니다. 먼저 모델을 선택하기 위한 기준이 달랐는데, 해당 연구에서는 모델 성능과 판별자의 정확도 사이의 연관성이 크지 않았습니다. 그리고 Zhang의 연구는 단일 실험을 통해 모델을 선택하기 때문에 하이퍼파라미터 튜닝이 불가능합니다. 그런데 최적의 하이퍼파라미터는 사용하는 언어마다 다를 수 있기 때문에 이러한 특징은 치명적인 한계로 작용합니다.
6. Conclusion
이 논문에서는 어떠한 cross-lingual supervison도 사용하지 않고 단어의 임베딩 공간을 align하는 방법을 최초로 제안하였습니다. 그리고 이는 통해 사전 학습을 사용하는 기존의 여러 기법보다 뛰어난 성능을 보입니다. 연구에서는 적대적 훈련을 사용하여 source와 target space 간의 선형 매핑을 초기화하여 synthetic parallel vocabulary를 구축하였습니다. 이를 통해 기존의 지도 학습에서 사용한 Procrustean optimization을 적용할 수 있었습니다. 이 논문의 핵심 연구는 검증 지표로 사용할 수 있는 간단한 criterion을 제안했다는 것과 hubness problem을 완화하는 유사도 측정 지표인 CSLS를 제안하였다는 것입니다. 이 결과 높은 품질의 사전을 구축할 수 있었고, 스페인어-영어 번역 태스크에서는 83.3%의 정확도를 달성하였습니다. 게다가 논문의 방법론은 에스페란토어와 같이 데이터가 많지 않은 언어에서도 사용될 수 있다는 이점이 있습니다.
7. Reflection
이 논문은 문서의 길이에 비해 읽고 정리하는 데 특히 시간이 오래 걸린 것 같습니다. 요구하는 수학적 개념이 굉장히 많았고, GAN에 대한 개념도 어느정도 이해해야 해서 논문을 읽는 중간 중간에 계속해서 검색을 하고 문서를 읽어보며 이해하려고 노력한 것 같습니다. 머신러닝에서 SVD 개념이 나오기는 하지만, 수식까지 이해하고 있지는 않았기 때문에 Procrustes problem이나 이에서 파생된 여러 수식을 이해하는 게 특히 쉽지 않았던 것 같습니다. 이 외에도 논문에 선형대수학 개념이 다수 포함되어 있었습니다. 또한 언급했듯이 GAN의 개념과 판별자와 생성자의 손실 함수에 대한 이해가 요구되어서 때문에 이 부분에 대해서도 추가적인 공부가 필요했던 것 같습니다. 아직까지도 모든 내용을 완벽하게 이해했다고 하기엔 어렵고, 읽는 내내 내용을 따라가고 정리하는 게 쉽진 않았지만, 그래도 포기하지 않고 완주했다는 것만으로 상당히 만족스러웠습니다.
이 논문을 읽게 된 계기는 아마 paperswithcode에서 단어 임베딩이나 기계 번역에 대한 논문 목록을 보다가 흥미로운 제목에 이끌려서였던 것 같습니다. 번역 태스크를 parallel data가 없이 수행할 수 있다는 게 믿기지 않기도 하고 그 자체만으로도 놀라워서 관심을 가지게 되었습니다. 애초에 GAN의 개념이 그렇기도 하지만, 논문에서 제안하는 방법도 굉장히 창의적입니다. 물론 GAN과 Mikolov가 발견한 언어 임베딩이 갖는 선형성에 의해 이루어질 수 있는 연구이긴 했지만, 이를 바탕으로 도출한 저자의 인사이트가 놀라웠습니다. 창의적인 생각을 실제로 구현하는 과정은 정말 복잡한 수식을 동원해야 하기 때문에 읽는 입장에서는 저자의 생각을 따라가기가 특히 어려웠던 것 같습니다. 이 방법이 지금도 실제로 많이 사용되는지에 대해서는 따로 알아봐야 할 것 같지만, 만약 그렇다면 논문에서 언급했듯 데이터가 많지 않은 도메인의 언어에 대해서도 사전을 구축하고 번역을 수행할 수 있다는 점이 굉장히 의미있는 연구라고 생각됩니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (1) | 2023.11.20 |
|---|---|
| [논문리뷰] Training language models to follow instructions with human feedback (0) | 2023.11.10 |
| [논문리뷰] Word Translation Without Parallel Data (1) (0) | 2023.11.04 |
| [논문리뷰] Enriching Word Vectors with Subword Information (1) | 2023.10.29 |
| [논문리뷰] GloVe: Global Vectors for Word Representation (1) | 2023.10.27 |




댓글