
word2vec를 제안한 저자 Toms Mikolov가 임베딩 벡터가 갖는 언어적 규칙성에 대하여 분석한 논문 Linguistic Regularities in Continuous Space Word Representations를 읽고 리뷰하였습니다. 이번 논문에서는 특별히 새로운 기법이 제안되었다기보다는 저자를 비롯한 여러 연구자들이 기존에 생성한 Static embedding vector를 통해 발견한 임베딩 벡터의 언어적 특징을 깊게 연구한 내용입니다. 내용이 어렵지 않고 논문의 길이도 길지 않아 오랜만에 정말 편하게 읽은 것 같습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Introduction
신경망 기반 언어 모델은 단어를 고차원의 실수 벡터 표현으로 매핑합니다. 이런 분산 표현은 n-gram 언어 모델과 같은 전통적인 기법에서는 볼 수 없는 수준의 일반화 능력을 갖습니다. n-gram 모델은 단어가 원핫 벡터와 같이 이산적인 분포를 띄며 서로 간의 내재적인 관계를 갖지 않지만, 연속 공간에 존재하는 단어 벡터는 유사한 단어는 서로 유사한 벡터를 갖습니다.
신경망 언어 모델을 학습하면 모델 뿐만 아니라 학습한 단어 표현까지도 얻을 수 있습니다. 이러한 벡터는 다른 모델이나 태스크에서 사용할 수 있습니다. 이 논문에서 저자는 학습된 단어 표현이 의미론적, 구조론적 규칙성을 간단한 방식을 통해 잘 포착함을 발견하였습니다. 구체적으로는 단어 벡터간의 constant vector offset의 형태로 규칙성이 관찰되었습니다. 예를 들어, 어떤 단어 i의 벡터를 xi라고 할 때, xapple−xapples≈xcar−xcars와 같은 관계가 성립함을 발견하였습니다. 더 놀라운 것은 이런 방식으로 다양한 의미적 관계를 표현할 수도 있다는 것입니다.
2. Related Work
단어의 분산 표현은 Hinton(1986), Pollack(1990), Elman(1991), Deerwester(1990)이 각각이 발표한 논문에서 연구될 정도로 짧지 않은 역사를 갖고 있습니다. 시간이 지나서 신경망 언어 모델이 제안되어 이전 단어가 주어졌을 때 다음 단어의 확률을 예측하는 태스크를 수행하였습니다. 이런 모델은 처음에는 피드포워드 신경망을 사용하여 연구되었고, 나중에는 순환 신경망을 사용하게 되었습니다. 이런 연구에서 모델은 훌륭하게 다음 단어를 예측하지만, 연산 측면에서 더욱 효율적인 모델이 필요합니다. 이 문제는 Morin과 Bengio에 의해 hiearchical prediction을 사용하여 다뤄졌습니다.
3. Recurrent Neural Network Model
논문에서 사용된 단어 표현은 위의 그림과 같이 순환 신경망을 사용한 언어 모델에서 학습한 것입니다. 이 아키텍처는 입력 레이어, 순환 연결(recurrent connection)을 갖는 히든 레이어와 각각에 대응하는 가중치 행렬로 이루어집니다. 입력 벡터 w(t)는 1-of-N 코딩을 사용하여 인코딩된 시간 t에서의 입력 단어입니다. 1-of-N 코딩은 쉽게 원핫 벡터로 이해할 수도 있고, 어휘 사전(vocabulary)의 인덱스로 매핑했다고 이해해도 괜찮을 것 같습니다. 출력 레이어 y(t)는 단어들의 확률 분포를 출력합니다. 히든 레이어 s(t)는 sentence history의 표현을 저장합니다. 입력 벡터 w(t)와 출력 벡터 y(t)의 크기는 어휘 사전의 크기와 같습니다. 히든 레이어와 출력 레이어의 값은 다음과 같이 계산됩니다.
여기서 f(z)와 g(zm)은 다음과 같이 정의됩니다, 수식을 보면 순서대로 시그모이드, 소프트맥스 함수임을 알 수 있습니다.
여기서 w(t)는 원핫벡터이기 때문에, 단어의 표현은 U의 열을 통해 얻을 수 있고, 각 열은 하나의 단어에 대응됩니다. RNN은 로그 가능도를 최대화하는 것을 목표로 역전파를 통해 훈련됩니다. 모델 자체는 통사론, 형태론, 의미론에 대한 지식이 전혀 없습니다. 그런데 순수하게 사전적 의미만을 학습하는 모델(purely liexical model)을 훈련하는 것만으로 단어 벡터가 의미와 구문에 대한 속성을 갖게 됩니다.
4. Measuring Linguistic Regularity
4.1 A Syntactic Test Set
학습된 표현에 내재된 통사론적 규칙성을 이해하기 위해서 저자는 “a와 b의 관계는 c와 ___의 관계와 같다”의 형식을 갖는 유추 문제로 테스트 세트로 구성하였습니다. 테스트 세트에는 원급/비교급/최상급 형용사, 일반 명사의 단수와 복수 형태, 소유격과 소유격이 아닌 형태와 기본형, 과거형, 3인칭 동사에 대한 유추가 포함됩니다. 저자는 신문의 텍스트와 Penn Treebank POS tags 데이터셋의 267M 개의 단어를 사용하였습니다. 그리고 가장 많이 등장하는 비교급 형용사(JJR), 복수 명사(NNS), 동사의 기본형(VB)를 각각 100개씩 선택하였습니다. 그리고 100개의 단어를 임의의 5개의 단어와 매칭하여 유추 문제를 생성하였습니다. 전체 테스트 세트는 8000개이며, 그 예시는 다음과 같습니다.
4.2 A Semantic Test Set
저자는 또한 SemEval-2012 Task2, 관계 유사도 측정 데이터를 사용하여 RNNLM 단어 벡터가 의미론적 정보를 어느 정도까지 이해하는지 측정하였습니다. 테스트 세트는은79개의 단어 관계를 포함하며, 10개는 학습에 69개는 테스트에 사용되었습니다. 모델은 clothing:shirt와 같은 단어 쌍이 주어지면 타겟 단어 dish:bowl의 관계가 주어진 단어쌍의 관계와 얼마나 유사한지를 예측합니다.
5. The Vector Offset Method
앞에서 보았듯이, 의미론적 태스크와 통사론적 태스크는 모두 유추 문제의 형태를 띕니다. 저자는 코사인 유사도에 기반한 단순한 vector offset method이 이 문제를 푸는 데 놀라울 정도로 효과적임을 발견하였습니다. 이 방법에서, 단어 간의 관계를 벡터 오프셋으로 가정하고 임베딩 공간에서 같은 관계성을 띄는 모든 단어쌍은 같은 상수 오프셋과 연관되어 있습니다. 다음 그림을 보면 조금 더 이해가 쉬울 것입니다.
이 모델은 d가 알려지지 않았을 때, a:b=c:d와 같은 유추 문제를 풀기 위해서 임베딩 벡터 xa,xb,xc를 구하고 y=xb−xa+xc를 계산합니다. y는 단어의 연속 공간에서의 표현이며 우리가 정답으로 기대하는 벡터입니다. 물론 정확히 그 위치에 단어가 존재하지는 않기 때문에 저자는 y와 다음 수식의 결과가 가장 높은 코사인 유사도를 갖는 임베딩 벡터를 탐색하였습니다.
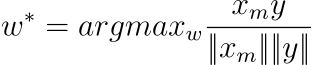
Semantic test set에서와 같이 d가 주어졌을 때 단순히 cos(xa−xa+xc,xd)를 계산합니다.
6. Experimental Results
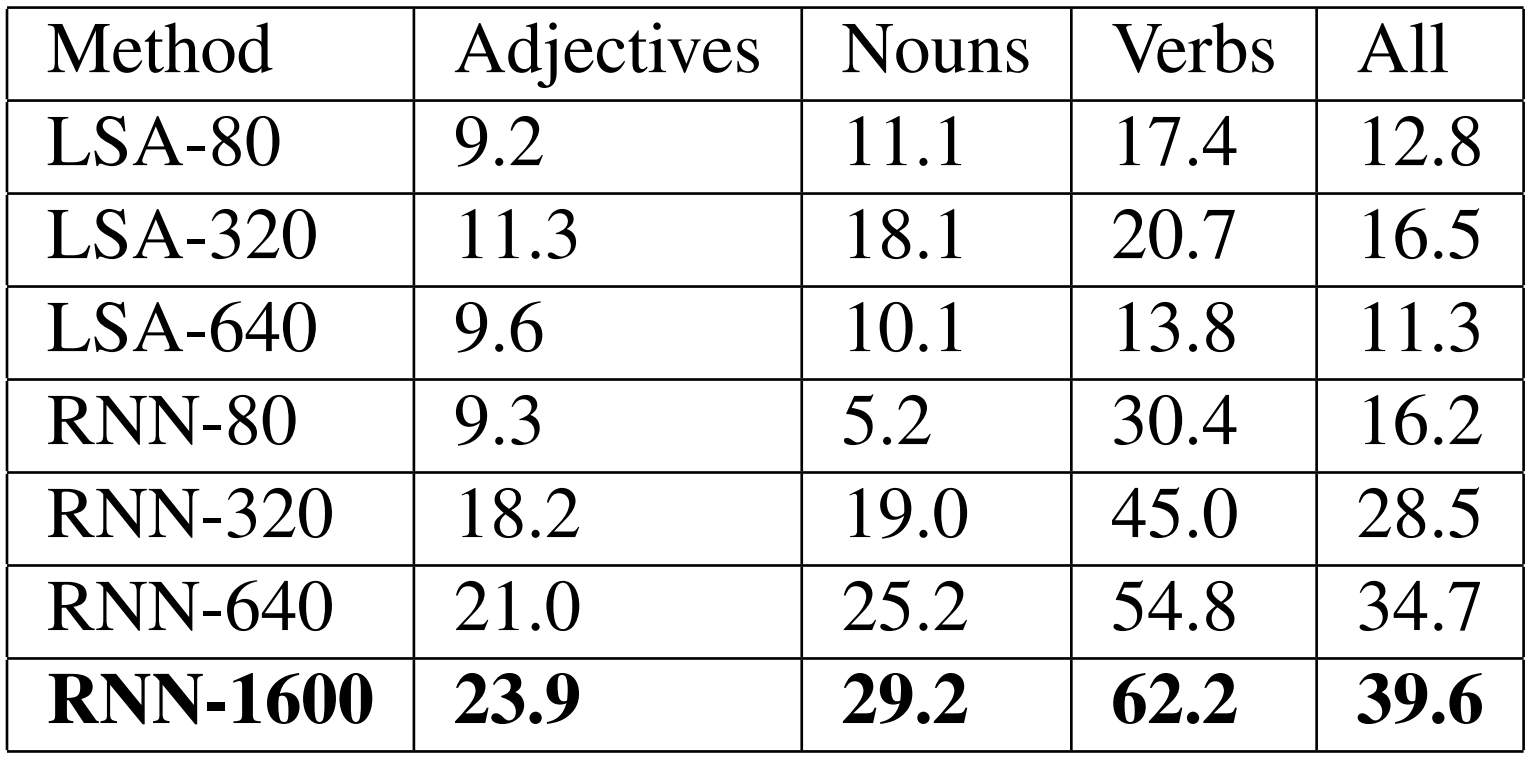
Vector offset method를 평가하기 위해 저자는 RNN toolkit으로 생성한 벡터를 사용하였습니다. 각각 80, 320, 640 차원의 벡터가 생성되었으며, 여러 시스템을 조합하여 총 차원이 1600인 벡터도 생성되었습니다. 각 시스템은 Broadcast News 데이터셋의 320M 단어로 학습되었고 어휘 사전의 크기는 82k입니다. 다음 표는 RNNLM과 LSA 벡터에 대한 테스트 결과입니다. RNN 벡터가 의미론적 규칙성을 훨씬 더 잘 이해한다는 것을 알 수 있습니다.
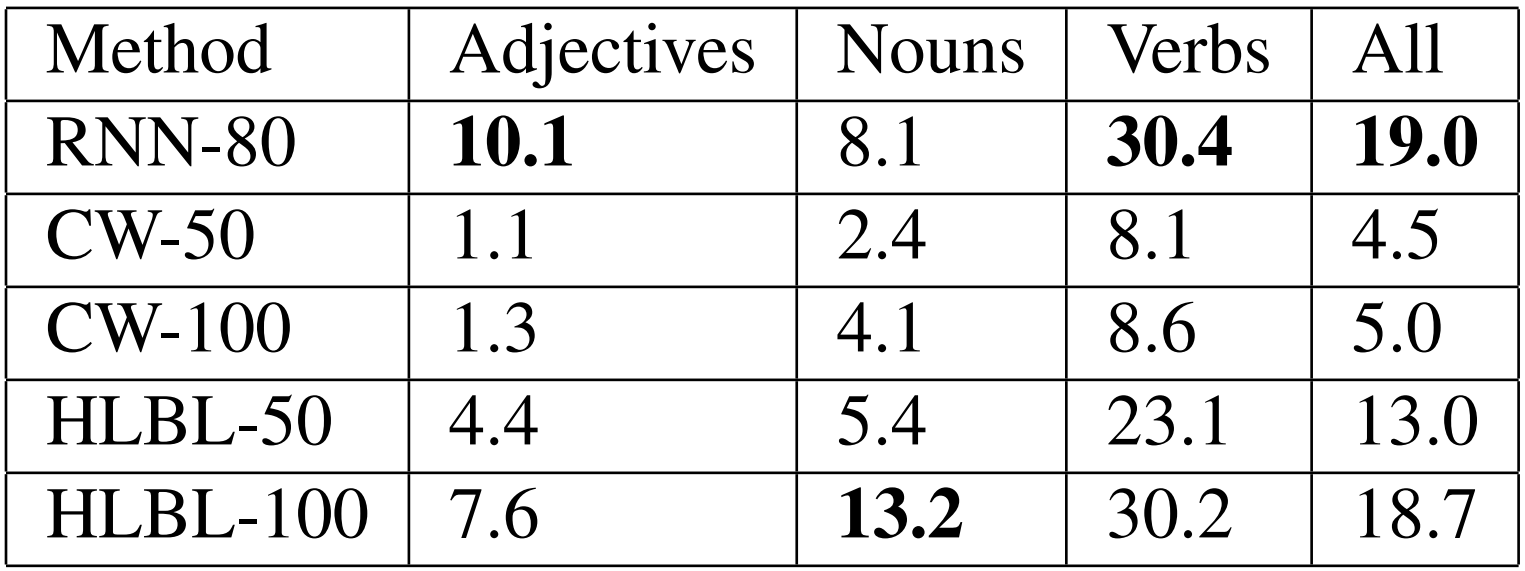
다음 표에서는 RNN 벡터와 Collobert, Weston, Mnih와 Hinton의 방법에 기반한 벡터를 비교하였습니다. 각 데이터셋에서는 서로 다른 단어가 나타나기 때문에 저자는 어휘 사전의 교집합에 대하여 계산하였습니다. 이를 통해 36k의 크기를 갖는 어휘 사전과 6632개의 테스트 세트가 생성되었습니다.
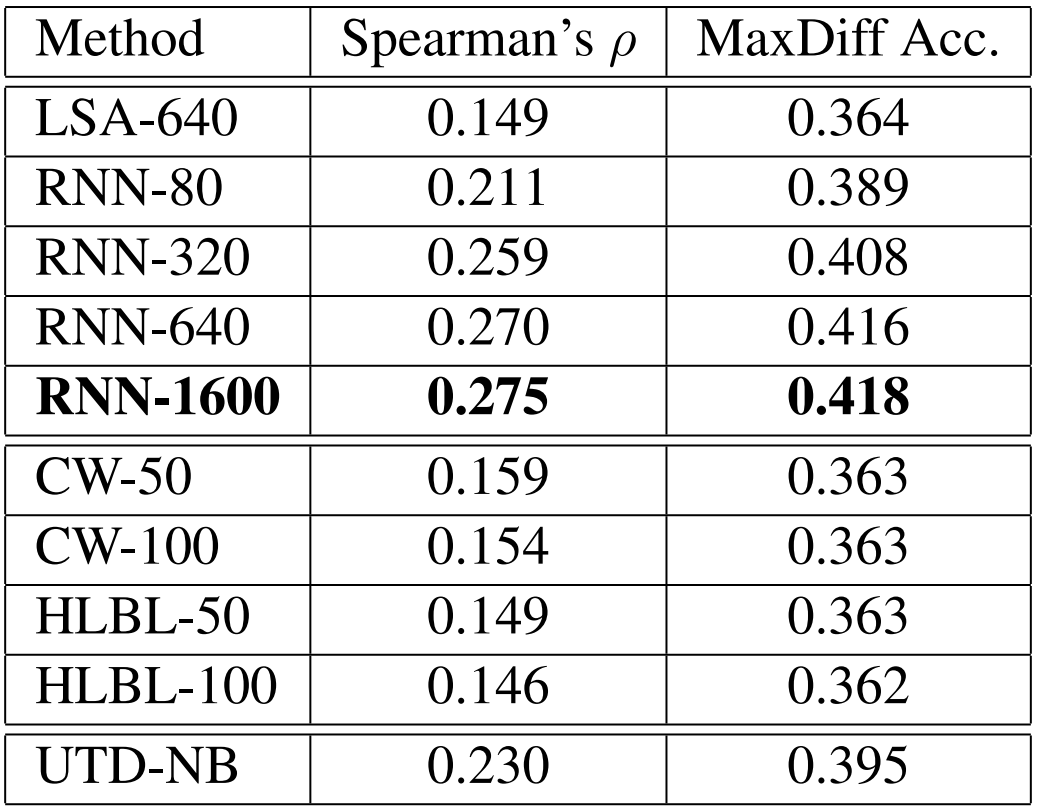
저자는 semantic test set에도 비슷한 실험을 수행하였습니다. 이 태스크에서는 두 가지 지표를 사용하였는데, 각각 Spearman’s rank correlation ρ와 MaxDiff accuracy입니다. 두 경우에서 모두 값이 높을수록 좋습니다. 다음 표에서 syntactic test와 마찬가지로 RNN에 기반한 표현이 더 뛰어난 성능을 보이는 것을 알 수 있습니다.
7. Conclusion
이 논문에서 저자는 연속 공간의 단어 표현의 언어적 규칙성을 확안하기 위해서 일반적으로 사용될 수 있는 vector offset method를 제안하였습니다. 또한 RNNLM을 통해 학습된 단어 표현이 이런 규칙성을 특히 잘 포착한다는 것을 발견하였습니다. 통사론 이해를 평가하는 데이터셋을 제안하며, 저자가 사용한 단어 벡터가 40%의 정답률을 보임을 밝혔습니다. 나아가 SemEval 2012 태스크를 통해 semantic generalization을 평가하고 기존의 SOTA 모델보다 성능이 우수함을 입증하였습니다.
8. Further Thinking
논문에서 제일 흥미로웠던 점은 단어 임베딩을 공부할 때 가장 유명한 공식이자 그림 중 하나인 "King - Man + Woman = Queen"이 바로 여기서 등장했다는 것입니다. 보통 NLP에서 임베딩을 처음 공부할 때 대표적인 정적 임베딩인 word2vec부터 학습하게 됩니다. 그리고 이 때 위 예시가 자주 언급되기 때문에, 막연하게도 이 내용이 당연히 word2vec 논문에서 등장할 것이라고 생각했습니다. 그런데 그와 관련된 논문을 두 개나 읽으면서도 이 그림이 나오지 않는 게 의아했는데, 알고보니까 그 이전에 임베딩에 대해 연구한 논문에 등장한 내용이었습니다. 실제로 이 논문이 word2vec보다 먼저 제안되었는지는 정확히 모르겠지만, 세 논문에서 다루는 내용이나 레퍼런스를 보았을 때 아마 이 논문이 먼저 발표되었다고 생각하고 있습니다. 아무튼 여기서 vector offset method라는 방법을 통해 정적 임베딩의 규칙성을 처음 분석했다는 것이 논문의 포인트인 것 같습니다. 이를 통해 저자는 word2vec이라는 새로운 기법을 발전시킬 수도 있었고, 단어 임베딩 연구를 더욱 확장할 수 있었던 것 같습니다. 간단한 논문을 통해 저자의 생각과 함께 많은 것을 느낄 수 있었습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] GloVe: Global Vectors for Word Representation (1) | 2023.10.27 |
|---|---|
| [논문리뷰] Attention Is All You Need (1) | 2023.10.24 |
| [논문리뷰] Distributed Representations of Words and Phrases and their Compositionality (1) | 2023.10.19 |
| [논문리뷰] Efficient Estimation of Word Representations in Vector Space (1) | 2023.10.17 |
| [논문리뷰] A Neural Probabilistic Language Model [2] (1) | 2023.10.14 |




댓글