
이전에 리뷰한 논문 Efficient Estimation of Word Representations in Vector Space의 후속 논문인 Distributed Representations of Words and Phrases and their Compositionality를 읽고 리뷰해보았습니다. 이 논문은 이전에 리뷰한 논문에서 Skip-gram 모델에 집중하여 이 성능과 연산 효율성을 크게 개선하는 방법을 담고 있습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Overview
저자는 이전 논문에서 Skip-gram 모델과 대규모의 텍스트 데이터에서 높은 품질의 단어의 벡터 표현을 학습할 수 있는 효율적인 방법을 제안하였습니다. 신경망 아키텍처를 사용하여 단어 벡터를 학습하는 이전 연구와는 다르게, Skip-gram 모델은 밀집 행렬 곱셈을 필요로 하지 않습니다. 이는 학습 효율을 극대화하여 1000억개의 단어를 최적화된 단일 기기에서 하루 만에 학습이 이루어지도록 할 정도입니다.
신경망을 사용하여 단어의 표현을 학습한다는 것은 이 벡터 표현이 다양한 언어적 규칙성을 인코딩한다는 점에서 매우 흥미롭습니다. 놀라운 것은 많은 패턴이 선형 연산으로 표현될 수 있다는 것입니다. 예를 들어서 vec(”Madrid”) - vec(”Spain”) + vec(”France”)의 결과는 어떤 다른 단어보다 vec(”Paris”)와 가까운 벡터가 됩니다.
이 논문에서는 원본 Skip-gram 모델을 확장한 몇 가지 기법을 제안합니다. 학습 과정에서 자주 등장하는 단어를 subsampling하여 2배에서 최대 10배까지 속도를 빠르게 하고, 자주 등장하지 않는 단어의 정확도를 향상하였습니다. 또한 Noise Contrastive Estimation(NCE)의 간단한 변형을 사용하여 학습을 빠르게 하고 벡터 표현의 품질을 향상시켰습니다. 이는 이전 논문에서 사용한 hierarchical softmax보다 덜 복잡한 방법입니다.
단어 표현은 단순히 각 단어의 조합이 아닌 관용구(idiomatic phrase)를 표현하는 능력이 부족합니다. 예를 들어 Boston Globe는 Boston과 Globe의 의미를 단순히 조합한 것이 아니라 신문의 이름입니다. 따라서 전체 구절을 사용한 벡터는 Skip-gram의 표현력을 더 풍부하게 할 것입니다.
단어 기반에서 구 기반 모델로의 확장은 비교적 간단합니다. 먼저 데이터에 기반한 접근법을 통해 많은 수의 구절을 탐지합니다. Phrase 벡터의 품질을 평가하기 위하여 저자는 단어와 구절을 모두 포함하는 유추 태스크를 개발하였습니다. 예를 들어 테스트 세트에는 Montreal : Montreal Canadiens = Toronto : Toronto Maple Leafs와 같은 문제가 포함됩니다. 여기서 Montreal Canadiens와 Toronto Maple Leafs는 각 지역의 아이스하키 팀입니다.
마지막으로 저자는 Skip-gram 모델의 흥미로운 특징을 발견하였습니다. 간단한 벡터 덧셈을 통해 의미있는 결과를 만들 수 있다는 것인데, 예를 들어 vec(”Russia”) + vec(”river”)는 vec(”Volga River”)라는 결과를 출력합니다. 볼가 강은 러시아 서부에 위치하는 강으로, 유럽에서 가장 긴 강입니다. 이런ccompositionality는 단어 벡터 표현의 기초적인 수학 연산을 통해 언어에 담긴 미묘한 의미를 이해할 수 있음을 의미합니다.
그림은 각 나라와 수도에 대한 1000 차원의 Skip-gram 벡터를 2차원으로 PCA를 수행한 것입니다. 이를 통해 모델이 수도가 어떤 의미인지 지도 학습하지 않았음에도 암시적으로 그들의 관계와 개념을 학습하였음을 알 수 있습니다.
2. The Skip-gram Model
Skip-gram 모델의 훈련 목표는 문장이나 문서 내에서 주변 단어를 예측하는 데 도움이 되는 단어 표현을 얻는 것입니다. 기술적으로는 학습 단어의 시퀀스 w1,w2,w3,…,wT가 주어졌을 때, Skip-gram 모델의 목표는 평균 로그 확률을 최대화하는 것입니다.
식에서 c는 학습 컨텍스트의 크기를 의미하며 중심 단어 wt에 대한 함수로 생각할 수 있습니다. c가 크면 더 많은 학습 샘플을 생성할 수 있고 정확도도 높아지지만, 훈련 시간도 길어집니다. 기본 Skip-gram 공식에서 p(wt+j|wt)는 소프트맥스 함수를 사용하여 다음과 같이 정의됩니다.
vw와 v′w은 각각 w의 입력과 출력 벡터 표현이며, W는 어휘사전(vocabulary)의 크기입니다. 이 공식은 ∇logp(wO|wI)의 연산 비용이 일반적으로 그 값이 105에서 107 정도로 큰 W에 비례하기 때문에 실용적이지 않습니다. 위 식을 간단히 해석하면 입력 단어 wI가 주어졌을 때 어휘 사전 내의 모든 단어 ∑Ww=1v′w가 출력이 될 수 있는데, 그 중 wO가 출력될 확률을 계산한다는 것입니다. 그리고 실제로 주변 단어를 예측하는 데 도움이 될 경우 그 확률을 최대하하는 방향으로 학습이 이루어질 것입니다.
2.1 Hierarchical softmax
Full softmax의 연산 효율을 고려하여 근사한 것이 hierarchical softmax입니다. 장점은 확률 분포를 얻기 위하여 신경망에서 W개의 출력 노드 대신 약 log2(W)개의 노드만을 고려하면 된다는 것입니다.
Hierarchical softmax는 W개의 단어를 잎으로 하고, 각 노드에 대하여 자식 노드에 대한 상대적 확률을 명시적으로 표현하는 이진 트리 표현을 사용합니다. 이는 각 단어가 할당될 확률에 대한 random walk를 의미합니다.
엄밀하게는 각 단어 w는 트리의 루트에서 적절한 경로를 따라 도달할 수 있습니다. n(w,j)를 루트에서 w로 가는 경로의 j번째 노드라고 하고, L(w)를 이 경로의 길이라고 하겠습니다. 그러면 n(w,1)=root이고 n(w,L(w))=w입니다. 그리고 모든 내부 노드 n에 대하여 ch(n)을 n의 임의의 자식 노드라고 하고 [[x]]는 x가 참일 경우 1, 그 외의 경우 -1이라고 하겠습니다. 그러면 hierarchical softmax는 p(wO|wI)를 다음과 같이 정의할 수 있습니다.
식에서 σ(x)=1/(1+exp(−x))입니다. ∑Ww=1p(w|wI)=1 임을 확인할 수 있습니다. 이는 logp(wO|wI)와 ∇logp(wO|wI)의 연산 비용이 L(wO)에 비례함을 의미하며, logW보다 평균적으로 크지 않습니다. 또한 각 단어 w에 두 개의 표현인 vw와 v′w을 할당하는 Skip-gram의 표준적인 소프트맥스 공식과 다르게, hierarchical softmax는 각 단어 w에 대하여 하나의 표현 vw를 갖고 이진 트리에서 내부 노드 n에 하나의 표현 v′n을 할당합니다.
Hierarchical softmax가 사용하는 트리 구조는 성능에 상당한 영향을 미칩니다. Mnih와 Hinton은 다른 연구에서 다양한 트리 구조를 사용하며 학습 시간과 모델 정확도에 미치는 영향을 분석하였습니다. 이 논문에서는 binary Huffman tree를 사용하여 자주 등장하는 단어에 짧은 코드를 할당하여 학습이 빨라지게 하였습니다.
2.2 Negative Sampling
Hierarchical softmax의 대안은 Noise Contrastive Estimation(NCE)입니다. NCE는 좋은 모델은 로지스틱 회귀를 통해 데이터와 노이즈를 구분할 수 있다고 가정합니다. 이는 hinge loss와도 비슷합니다. NCE는 소프트맥스의 로그 확률을 근사적으로 최대화할 수 있음이 알려져있지만, Skip-gram 모델은 높은 품질의 벡터 표현을 학습하는 데만 관심이 있기 때문에 벡터 표현이 품질을 유지하기만 한다면 NCE를 단순하게 만들 수 있습니다. 저자는 Negative sampling(NEG)의 다음과 같이 정의하여, Skip-gram의 훈련 목표에서 모든 logP(wO|wI)항을 대체하는 데 사용하였습니다.
따라서 각 데이터 샘플에 대한 k개의 negative sample이 존재할 때, 로지스틱 회귀를 사용하여 각 타겟 단어 wO를 노이즈 분포 Pn(w)에서 추출한 것과 비교하는 게 태스크를 수행하게 됩니다. 실험을 통해 작은 학습 데이터셋에 대하여 k의 값이 5에서 20 정도가 적절하고, 대규모 데이터셋에서는 k의 값이 2에서 5 정도가 적절함을 확인하였습니다. Negative sampling과 NCE의 차이점은 NCE는 샘플과 노이즈 분포에 대한 확률이 모두 필요하지만, Negative sampling은 샘플만이 필요하다는 것입니다. 또한 NCE는 소프트맥스의 로그 확률을 근사적으로 최대화하지만 이 태스크에서는 이런 특징이 필요하지 않습니다.
여기서 NCE가 소프트맥스의 로그 확률을 최대화하는 성질이 왜 불필요한지에 대한 의문이 생길 수 있습니다. Skip-gram의 훈련 목표는 입력 단어 wI가 주어졌을 때 문맥에 맞는 단어가 출력 단어 wO가 되는 확률을 최대화하는 것입니다. 처음에는 로그 확률을 최대화하는 것이 불필요하다는 것이 이해가 가지 않았습니다. 그런데 앞서 언급했듯이 논문에서는 “벡터 표현의 품질을 유지할 수만 있다면 NCE를 단순하게 만들 수 있다”고 하였습니다. 이것이 바로 Negative sampling의 핵심입니다. 소프트맥스의 로그 확률 최대화는 결국 어휘 사전에 존재하는 모든 단어 중 문맥을 고려했을 때 실제로 관련이 있는 단어에 대한 확률을 높이는 데 관심이 있습니다. 바꿔 말하면, 문맥상 관련이 있는 단어와 그렇지 않은 단어를 구분하고자 합니다. 그리고 이것이 바로 Negative sampling의 목표입니다. 각 샘플에 대하여 관련이 없는 샘플을 임의로 추가하여, 관련이 있는 단어만을 구별하며 학습하게 하는 것입니다. 물론 NCE나 hierarchical softmax가 더 엄밀하게 학습할 수 있지만, Negative sampling을 사용하면 비슷한 목표를 조금 더 효율적으로 이룰 수 있습니다. 다시 논문의 내용을 이어서 설명하겠습니다.
NCE와 NEG는 모두 노이즈 분포 Pn(w)을 파라미터로 갖습니다. 저자는 실험을 통해 Pn(w)을 선택하였는데, NCE와 NEG 모두에서 unigram 분포를 3/4 제곱한 U(w)3/4/Z가 unigram과 균일 분포를 혼합한 것보다 조금 더 성능이 뛰어남을 발견하였습니다.
2.3 Subsampling of Frequent Words
대규모 데이터에서 매우 흔하게 등장하는 단어들은 수 억번씩 나타나기도 합니다. 예를 들면 in, the, a가 그렇습니다. 이런 단어들은 드물게 나타나는 단어에 비해 문장에 대해 적은 정보를 제공합니다. 예를 들어 Skip-gram 모델은 France와 the가 함께 나타(co-occurence)나는 경우보다 France와 Paris가 함께 나타나는 경우에 더 많은 것을 학습할 것입니다. 반대로, 흔히 나타나는 단어의 벡터 표현은 수백만 개의 샘플을 학습해도 크게 바뀌지 않을 것입니다.
자주 등장하는 단어와 희귀한 단어의 불균형을 해소하기 위해서 저자는 간단한 subsampling 방법을 사용하였습니다. 학습 데이터셋의 각 단어 wi를 다음과 같은 확률에 따라 제거하기로 하였습니다.
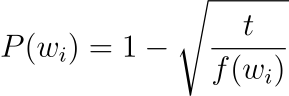
식에서 f(wi)는 단어 wi가 등장하는 빈도이며 t는 임곗값입니다. 실험에서는 t의 값으로 10−5를 사용하였습니다. 이 방법을 통해 각 단어의 등장 빈도 순위는 유지하면서 빈도가 t보다 큰 단어를 제거하여 서브샘플링할 수 있습니다.
예를 들어 어떤 단어 wa가 문장 내에서 10% 확률로 등장한다고 했을 때 P(wa)=0.99입니다. 또 다른 단어 wb가 문장 내에서 0.01% 확률로 등장한다고 할 때 P(wb)≈0.6837입니다. 따라서 자주 임곗값 이상의 빈도를 갖는 단어의 등장 빈도가 클수록 어휘 사전에서 제거될 확률이 높아집니다.
저자는 이 서브샘플링 공식이 휴리스틱하게 결정되었다고 하였지만, 실제로 좋은 성능을 보인다고 밝혔습니다. 다음과 같이 이를 통해 학습을 가속화하고 희귀 단어에 대한 정확도도 크게 향상할 수 있었습니다.
3. Empirical Results
저자는 유추 태스크를 통해 Hierarchical Softmax(HS), Noise Contrastive Estimation, Negative Sampling, subsampling을 평가하였습니다. 예를 들어 Germany : Berlin = France : ? 라는 데이터가 주어지면 vec(”Berlin) - vec(”Germany) + vec(”France”)와 가장 가까운 vec(x)를 찾는 것입니다. 만약 그 벡터가 Paris에 대한 벡터라면 정답으로 간주합니다. 태스크는 quick : quickly = slow : slowly와 같이 구문에 대한 이해와 앞의 예시와 같이 의미에 대한 이해를 모두 평가합니다.
단순히 Skip-gram 모델의 선형성 때문에 이와 같은 선형 연산을 통한 유추가 가능하다는 생각이 들 수 있습니다. 하지만 저자는 이전 연구를 통해 비선형성을 갖는 순환 신경망을 통해 학습한 벡터 또한 이런 태스크의 성능을 크게 향상됨을 밝혔습니다.
4. Learning Phrases
앞에서 언급했듯 많은 구절은 단순히 각 단어의 의미를 조합한 것이 아닌 새로운 의미를 갖습니다. 구에 대한 벡터를 학습하기 위해 저자는 먼저 자주 함께 등장하는 단어들을 찾았습니다. 예를 들어 New York Times와 Toronto Maple Leafs는 학습 데이터에서 하나의 고유한 토큰으로 대체되었습니다. 이 방법으로 어휘 사전의 크기를 너무 많이 증가하게 하지 않는 선에서 많은 합리적인 구를 형성할 수 있었습니다. 물론 이론적으로 모든 n-gram을 사용하여 Skip-gram을 훈련할 수 있지만 이는 메모리를 과도하게 요구할 것입니다. 텍스트에서 구를 식별하는 다양한 기법이 있지만, 저자는 다음과 같이 간단한 데이터에 기반한 접근법을 사용하였습니다.
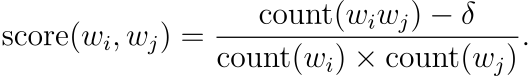
δ는 할인 계수(discount coefficient)로 사용되어 빈도가 매우 낮은 단어로 구성된 구가 너무 많이 형성되지 않도록 하였습니다. 임곗값을 넘는 점수를 갖는 bigram은 phrase로 사용되었습니다. 임곗값을 줄이면서 2-4번 정도 이 과정을 수행하여 여러 단어를 포함하는 구가 형성되도록 하였습니다. 다음은 그 예시입니다.
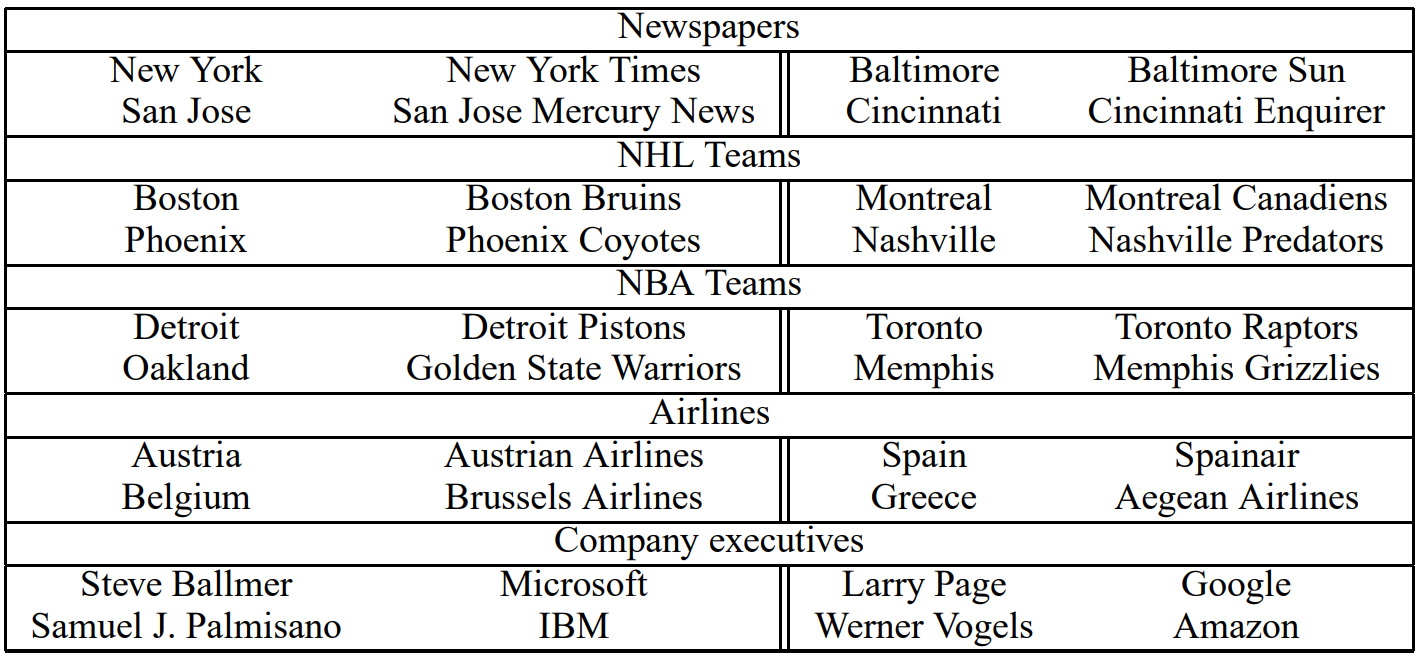
4.1 Phrase Skip-Gram Results
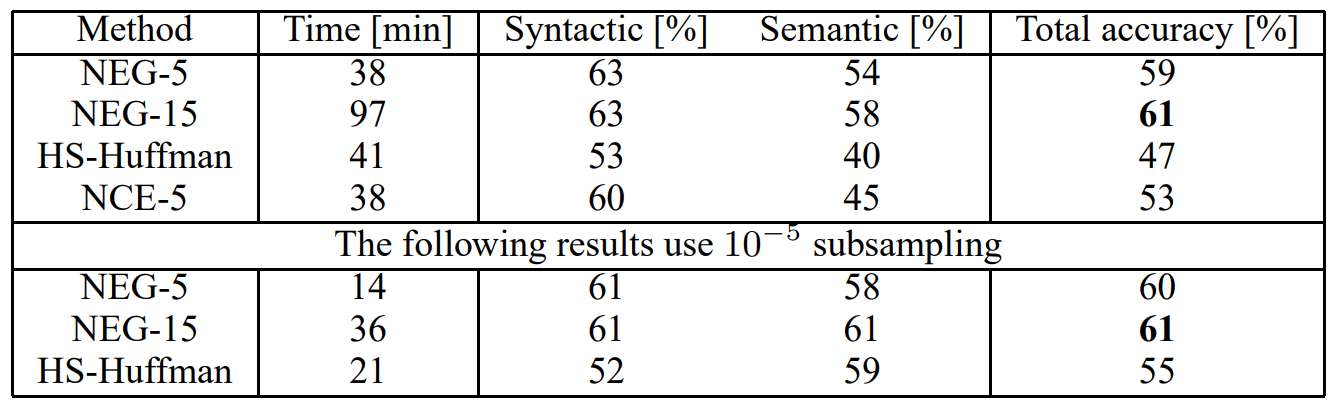
다음은 앞에서 언급한 내용들을 통해 실험을 수행한 결과입니다. Negative Sampling은 k=5일 때 꽤 괜찮은 정확도를 보이지만 k=15일 때 훨씬 더 좋은 성능을 보였습니다. 놀라운 것은 Hierarchical Softmax를 단독으로 사용하면 성능이 낮아지지만, subsampling과 함께 사용하면 가장 뛰어난 성능을 보였습니다. 이를 통해 subsampling이 학습을 빠르게 할 뿐만 아니라 정확도도 향상시킨다는 것을 알 수 있습니다.

Phrase analogy task의 정확도를 최대화하기 위하여 저자는 학습 데이터의 양을 330억 개의 단어까지 늘렸습니다. Hierarchical softmax, 1000 차원, 문장 전체를 context로 사용하였습니다. 이는 모델의 정확도를 72%까지 끌어올렸습니다. 학습 데이터로 60억 개의 단어만 사용했을 때는 66%까지 정확도가 떨어졌는데, 이는 학습 데이터의 양의 중요성을 보여줍니다.
다음은 서로 다른 모델에서 한 phrase의 neareset neighbors를 계산한 결과입니다.이전 실험에서와 같이 HS와 subsampling을 함께 사용한 것이 가장 좋은 성능을 보입니다.

5. Additive Composionality
저자는 Skip-gram 모델이 학습한 단어와 구의 표현은 벡터의 대수적 연산으로 유추 문제를 푸는 것이 가능하다는 사실을 입증하였습니다. 흥미롭게도 저자는 Skip-gram 모델이 또 다른 형태의 선형적인 구조를 갖고, 벡터의 각 원소를 합하여 의미있는 결과를 얻을 수 있다는 것을 발견하였습니다. 그 예시는 다음과 같습니다.

이러한 additive property는 훈련 목표를 통해 설명될 수 있습니다. 단어 벡터는 소프트맥스의 비선형성에 대한 입력과 선형 관계에 있습니다. 단어 벡터는 문장 내에서 주변 단어를 예측하도록 훈련되는데, 벡터는 단어가 등장하는 문맥의 확률 분포를 나타냅니다. 이 값은 출력에서 계산된 확률과 logarithmically하게 연관되어 있으므로 두 단어 벡터의 합은 두 context distribution의 곱과 연관됩니다. 여기서 곱은 AND 연산과 같이 작용하여 두 단어 벡터에서 모두 높은 확률이 할당된 단어는 결과적으로 높은 확률을 갖고, 다른 단어들은 낮은 확률을 갖습니다. 따라서 Volga River는 같은 문장에서 Russian, River과 자주 함께 등장하며, 두 단어의 벡터를 합하면 Volga River과 가까운 벡터가 계산될 것입니다.
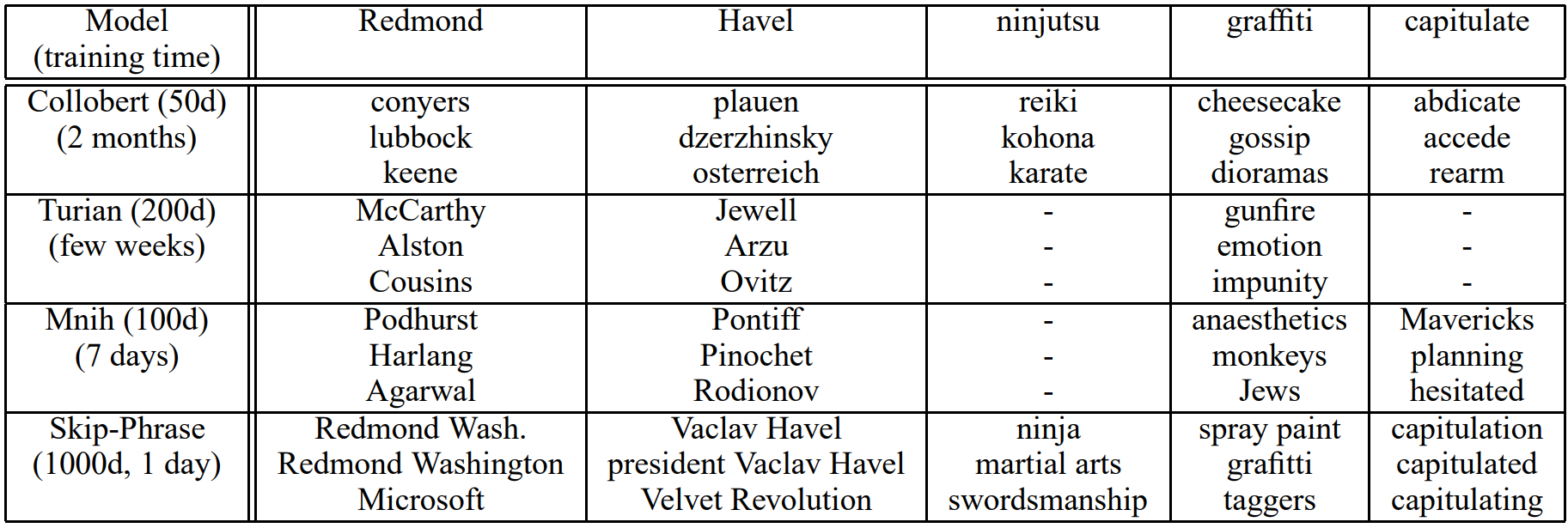
6. Comparison to Published Word Representations
신경망에 기반한 단어 벡터에 대한 연구는 이전에도 여럿 이루어졌습니다. 저자는 그 중 잘 알려진 모델들과 비교 실험을 수행하였고, Skip-gram이 다른 모델보다 큰 차이로 뛰어난 성능을 보임을 확인하였습니다. 다음은 각 모델에서 흔히 등장하지 않는 단어에 대한 최근접 이웃(nearest neighbors)를 계산한 결과입니다. Skip-gram 모델은 300억 개의 단어를 통해 훈련되었는데 이는 다른 모델의 학습 데이터의 규모에 비해 두 배에서 세 배 정도 많은 양입니다. 저자는 아마 이 결과가 학습 데이터의 양과 관련이 있을 수도 있다고 하였습니다. 그런데 Skip-gram 모델은 학습 데이터의 크기가 훨씬 큰데도 불구하고 시간 복잡도는 다른 모델에 비하면 매우 작다는 사실을 덧붙였습니다.
7. Conclusion
이 논문에서는 Skip-gram 모델을 사용한 단어와 구절의 분산 표현을 학습하는 방법과 그 표현이 정밀한 유추 태스크를 수행할 수 있는 선형성을 가짐을 보였습니다. 여기서 제안된 기법은 CBOW 모델에도 적용될 수 있습니다.
저자는 연산 효율적인 모델 아키텍처를 사용하여 성공적으로 거대한 규모의 학습 데이터를 학습하였습니다. 그리고 그 덕분에 단어 벡터의 품질이 상당히 향상되었고, 특히 희귀 단어에 대해서 더욱 성능이 좋아졌습니다. 또한 서브샘플링을 통해 학습 효율 뿐만 아니라 희귀 단어에 대한 정확도도 향상할 수 있었습니다. Negative sampling 알고리즘도 또 다른 주요한 기여 중 하나입니다.
이처럼 다양한 기법을 통해 학습된 Skip-gram 모델의 단어 벡터는 선형 연산을 통해 다양한 태스크를 수행할 수 있는 능력을 갖추고 있습니다. 단순한 대수적 연산을 통해 유추 문제를 해결하고, 벡터 덧셈을 통해 단어 사이의 암시적인 관계를 이해하고 있음을 보입니다.
8. Further Thinking
저자는 다양한 기법을 새롭게 제안하여 word2vec의 한 학습 방식인 Skip-gram의 성능을 개선하였습니다. 지난 논문에서 확인했듯이 전반적인 성능이 CBOW에 비해 Skip-gram이 더 좋았기 때문에 이를 바탕으로 논리를 확장한 것이라고 생각됩니다. 이 논문에서는 Phrase representation이나 subsampling과 같이 벡터 표현의 품질 자체를 개선하는 새로운 방법이 여럿 제안되었습니다. 나아가 학습 과정에서 연산 효율을 극대화하기 위한 다양한 방법도 제시되었습니다. 그 과정에서 알고리즘에 대한 배경지식이나 깊은 이해를 많이 요구해서 논문에서 제안하는 내용 자체는 어렵지 않았지만, 그 밑에 깔린 개념을 이해하는 것이 상당히 어려웠습니다. 그래도 hierarchical softmax가 어떤 원리로 작동하는 것인지에 대해서 이전보다 조금 더 명확하게 이해한 것 같아서 만족스러웠습니다. 이전에 언급했듯 과거 논문의 경우 특히 연산 효율을 고려하는 내용이 자주 나타나는데, 아마 하드웨어 성능의 한계를 현재보다 더 많이 겪었기 때문이 아닐까 하는 생각이 듭니다. 딥러닝 관련한 논문을 읽으면서도 알고리즘이나 자료구조 등 CS 전반에 걸친 지식을 확장할 수 있는 좋은 계기가 된 것 같습니다. Hierarchical softmax에 대해서는 이해한 내용을 구체적으로 정리해서 별도의 글로 정리할 생각입니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] Attention Is All You Need (1) | 2023.10.24 |
|---|---|
| [논문리뷰] Linguistic Regularities in Continuous Space Word Representations (0) | 2023.10.20 |
| [논문리뷰] Efficient Estimation of Word Representations in Vector Space (1) | 2023.10.17 |
| [논문리뷰] A Neural Probabilistic Language Model [2] (1) | 2023.10.14 |
| [논문리뷰] A Neural Probabilistic Language Model [1] (1) | 2023.10.13 |




댓글