
word2vec에 이어 가장 널리 사용되고 이름이 많이 알려진 GloVe에 대한 논문 GloVe: Global Vectors for Word Representation를 읽고 리뷰해보았습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Overview
Semantic vector space model은 단어를 실수 벡터로 표현합니다. 이렇게 만든 벡터는 정보 검색, 질문 답변과 같은 다양한 태스크에 사용됩니다. 대부분의 단어 벡터는 두 단어 벡터 사이의 거리나 벡터가 이루는 각도를 바탕으로 intrinsic quality를 측정합니다. 이는 벡터가 의미있는 언어학적 정보나 단어의 의미론적 성질을 잘 포착했는지에 대한 지표를 의미합니다. 반대로 extrinsic quality는 단어 벡터가 통사론적 성질을 포착한 정도입니다.
그런데 당시 새롭게 제안된 word2vec은 벡터 간의 거리나 각도가 아닌 벡터의 선형 연산을 통한 단어 유추에 기반하여 intrinsic quality를 측정합니다. 예를 들어 king - queen = main - woman과 같은 등식으로 벡터가 학습한 언어 정보를 해석합니다.
단어 벡터를 학습하는 모델은 두 종류로 나눌 수 있습니다. 첫 번째는 latent semantic analysis(LSA)와 같이 global matrix factorization 기법을 사용하는 모델입니다. 두 번째는 word2vec의 skip-gram과 같은 local context window를 사용하는 모델 입니다. 그런데 LSA와 같은 기법은 co-occurrence와 같은 통계적인 정보를 잘 활용하지만 단어 유추 태스크를 제대로 수행하지 못하는 문제가 있습니다. 마찬가지로 skip-gram은 단어 유추는 잘 할지 몰라도 말뭉치에 대한 통계를 제대로 활용하지 못합니다.
이 논문은 단어의 의미에 대한 linear directions을 생성하는 데 필요한 모델이 갖는 속성을 분석하고 global log-bilinear regression 모델을 제안합니다. 이 모델은 global word-word co-occurrence를 학습하고 이 통계를 효과적으로 활용하는 weighted least squares 모델입니다. 이 모델은 단어 유추 태스크에서 높은 정확도를 달성하였고, NER과 같이 통사론적 이해를 평가하는 태스크에서도 우수한 성능을 보였습니다.
여기서 linear directions은 word2vec과 같이 선형 연산을 통해 의미를 학습하는 속성을 의미합니다. 그리고 저자가 특별히 global이라는 표현을 사용한 것은 word2vec은 같은 문장 내에서 정해진 context window 이내의 단어와의 연관성을 바탕으로 단어 벡터를 학습하는데, GloVe는 말뭉치 내 모든 데이터에 대한 동시 발생 횟수를 바탕으로 단어 벡터를 학습하기 때문입니다. 이에 대해서는 이후에 자세히 다루겠습니다.
2. Related Work
Matric Factorization Methods
저차원의 단어 표현을 생성하기 위한 행렬 분해 기법은 LSA에 뿌리를 두고 있습니다. 이러한 기법은 말뭉치의 통계적 정보를 포함하는 거대한 행렬을 분해하는 low-rank approxiation을 사용합니다. 이때 행렬이 포함하는 정보는 태스크에 따라 다릅니다. LSA에서 행렬은 단어-문서 쌍으로 이루어집니다. 즉, 행은 어떤 단어에 대응하고 열은 말뭉치 내의 각 문서에 대응합니다. 반면에 Hyperspace Analogue to Language(HAL)의 행렬은 단어-단어 쌍으로 이루어지며, 행과 열이 모두 어떤 단어에 대응하며 각 요소는 어떤 단어가 문서에 나타날 때 또 다른 단어가 함께 나타나는 횟수를 의미합니다.
그런데 HAL은 가장 자주 등장하는 단어가 유사도 측정에 불균형하게 영향을 미친다는 것입니다. 예를 들어 말뭉치 내에서 the와 and는 특별히 의미적 연관성을 가지지 않음에도 자주 함께 등장한다는 이유로 유사도에 큰 영향을 미칠 것입니다. 그래서 HAL의 단점을 극복하기 위해 COALS와 같은 기법이 제안되었습니다. 이 기법은 co-occurrence matrix를 엔트로피 또는 상관관계에 기반하여 정규화합니다. 또한 positive pointwise mutual information(PPMI)나 Hellinger PCA와 같이 이런 접근법을 사용한 다양한 연구가 이루어졌습니다.
Shallow Window-Based Methods
단어 표현을 학습하는 또 다른 방법은 local context window 내의 단어를 예측하는 것입니다. Bengio는 2003년 언어 모델링을 위해 설계된 단순한 신경망 아키텍처의 일부로 단어 벡터를 학습하는 방법을 제안하였습니다. 2008년 Collobert는 다운스트림 태스크와 단어 벡터 학습 과정을 분리하였습니다. 이를 바탕으로 2011년 선행 시퀀스 뿐만 아니라 전체 컨텍스트를 바탕으로 단어 벡터를 학습하는 방법이 연구되었습니다.
이후 전체 문맥을 학습하는 방식의 신경망 모델에 대한 의문이 제기되었고, 2013년 CBOW나 skip-gram과 같이 단어 벡터 사이의 내적을 활용하는 단일 레이어 아키텍처가 제안되었습니다. Mnih는 vLBL이나 ivLBL와 같이 closely-related vector log-bilinear model을 제안하였습니다. 여기서 bilinear model은 두 개의 벡터 변수에 대하여 각각 독립적으로 선형성을 갖는 모델입니다. 2014년 Levy는 PPMI 지표에 기반한 단어 임베딩을 제안하였습니다.
Skip gram과 ivLBL 모델은 단어가 주어졌을 때 단어가 나타난 문맥을 예측하고, CBOW와 vLBL 모델은 반대로 문맥이 주어졌을 때 단어를 예측합니다. 유추 태스크에서의 평가를 통해 이러한 모델은 단어 벡터의 언어학적 패턴을 선형적인 관계로 학습할 수 있다는 것이 밝혀졌습니다.
행렬 분해 기법과 다르게 shallow window에 기반한 기법은 co-occurrence statistics를 활용할 수 없다는 단점이 있습니다. 대신 이러한 모델은 전체 문맥을 컨텍스트 윈도우를 따라 스캔하는데, 이러한 방법은 데이터에서 같은 단어쌍이 반복된다는 정보의 이점을 활용하지 못합니다.
3. The GloVe Model
단어 등장 빈도에 대한 통계는 비지도 학습을 하는 모델이 주로 사용할 수 있는 정보입니다. 이 방식은 흔히 사용되지만 이러한 통계가 어떻게 단어의 의미를 만드는지, 그리고 벡터 표현이 그것을 어떻게 학습하는지에 대해서는 알려지지 않았습니다. 저자는 이러한 의문에 답하기 위해 전체 말뭉치의 통계를 통해 학습하는 모델인 Global Vectors, GloVe라는 단어 표현을 제안하였습니다.
먼저 word-word co-occurrence counts에 대한 행렬을 X라고 정의하고, 각각의 요소 Xij는 단어 i가 등장하는 문맥에서 단어 j가 나타나는 횟수를 의미합니다. 이를 확장하여 Xi=∑kXik 라고 정의하면 단어 i가 나타난 문맥에서 어떤 단어가 나타나는 횟수를 의미합니다. 그러면 Pij=P(j|i)=Xij/Xi 는 단어 i가 나타난 문맥에서 단어 j가 나타날 확률입니다.
어떤 주제에 대한 두 단어 i와 j를 생각해보겠습니다. 여기서는 열역학적 위상이라는 개념에 관심이 있다고 가정하고, i=ice, j=steam 이라고 하겠습니다. 단어들의 관계는 그들 각각이 어떤 단어 k와 동시등장 확률(co-occurrence probability)의 비율을 통해 알 수 있습니다. k=solid 와 같이 Ice와는 관련이 있지만 steam과는 관련이 없는 단어 k에 대해서 Pik/Pjk 의 값이 클 것이라고 생각할 수 있습니다. 마찬가지로 k가 이번에는 steam과 관련이 있는 k=gas 라면, 이 비율은 작아질 것입니다. 마지막으로 k가 water이나 fashion과 같이 두 단어 모두와 관련이 있거나, 두 단어 모두와 무관하다면 이 비율은 1에 가까울 것입니다. 다음 표는 큰 말뭉치에서 각각의 확률을 계산한 것인데, 예상한 것과 같은 결과가 나왔음을 알 수 있습니다.
위 실험은 동시등장 확률의 비율이 단어 벡터를 학습하는 데 적절하다는 것을 보여줍니다. 비율 Pik/Pjk 가 세 단어 i, j, k에 의존하기 때문에 모델은 일반적으로 다음과 같은 형태를 띌 것입니다.
w∈Rd는 단어 벡터이며 ˜w∈Rd는 separate context 단어 벡터인데 이에 대해서는 뒷부분에서 다룹니다. 수식의 우변은 말뭉치에서 추출할 수 있고, F는 현재는 정의되지 않은 어떤 파라미터에 의존합니다. 가능한 F는 다양하지만 몇 가지 조건에 의해 결정될 수 있습니다. 먼저 F가 단어 베겉 공간에서 Pik/Pjk를 나타내는 정보를 인코딩하기를 원합니다. 벡터 공간은 본질적으로 선형적이기 때문에, 벡터의 차이를 이용하는 것이 자연스러운 선택입니다. 이를 바탕으로 F를 다음과 같이 나타낼 수 있습니다.
수식 (2)에서 F의 인수는 벡터인데 우변은 스칼라입니다. F가 신경망과 같이 정교하게 파라미터화된 함수일 수도 있지만 이런 방식은 우리가 포착하려고 하는 선형 구조를 복잡하게 만듭니다. 이를 피하기 위해서 먼저 두 인수의 점곱을 취하여, 벡터가 예상치 않게 뒤섞이는 것을 방지합니다. 벡터곱(cross product)와 다르게 점곱은 벡터의 각 요소에 대한 정보를 독립적으로 보존한 채 연산이 수행되기 때문에, 벡터가 뒤섞이지 않는다는 표현이 사용되었습니다.
동시 발생 행렬에서 단어와 context word의 구분은 임의로 결정되며 자유롭게 교환될 수 있습니다. 이 작업은 일관되게 이루어져야 하므로 w↔˜w 뿐만 아니라 X↔XT도 교환되어야 합니다. 그런데 수식 (3)은 이런 표기법을 따르지 않습니다. 두 단계를 거쳐서 이 대칭성을 복원할 수 있는데, 먼저 F가 (R,+)과 (R>0,×)에 대하여 homomorphism을 갖추어야 합니다.
이는 두 구조 사이의 모든 연산 및 관계를 보존하는 함수를 의미합니다. 예를 들어서 어떤 공간에서 다른 공간으로 두 원소를 사상한다고 할 때, 두 원소 간의 연산을 수행한 후 투영한 결과와 먼저 투영한 후 같은 연산을 수행한 결과가 같으면 homomorphic하다고 합니다. (R,+)는 덧셈 연산을 수행할 수 있는 실수로 된 군(group)을 의미하고 (R>0,×)은 양의 실수에 대해 곱셈을 수행할 수 있는 군을 의미합니다. 즉 F(a+b)=F(a)×F(b)를 만족해야 합니다.
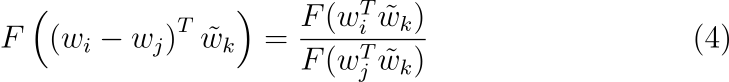
수식 (4)의 좌변은 additive group, 우변은 multiplicative group을 나타냅니다. 수식 (4)와 우변과 수식 (3)의 우변을 통해 다음과 같은 수식을 쓸 수 있습니다.
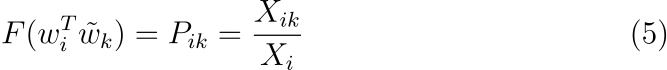
수식 (4)를 만족하는 해는 F=exp이며 양변에 로그를 취하여 다음과 같이 나타낼 수 있습니다.
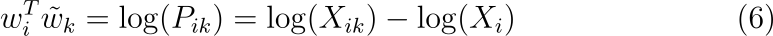
수식 (6)은 우변에 log(Xi)가 없으면 change symmetry를 만족합니다. 그런데 이 항은 k와는 독립적이므로 wi에 대한 bias bi에 포함시킬 수 있습니다. 그러면 ˜wk에 대한 bias ˜bk를 추가하여 다음과 같이 대칭성을 복원할 수 있습니다.
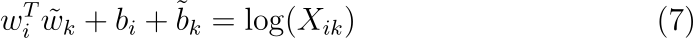
수식 (7)은 수식 (1)을 단순화한 형태이지만 인수가 0일 경우 로그가 발산한다는 문제를 갖고 있습니다. 따라서 additive shift를 추가하여, log(Xik)→log(1+Xik)가 되게 하여 X의 sparsity는 유지한 채 발산을 피할 수 있습니다. 동시 발생 행렬의 로그를 분해한다는 아이디어는 LSA와 밀접한 연관이 있으며 이 모델을 실험의 베이스라인으로 사용합니다. 이 모델의 단점은 co-occurrence를 똑같이 평가한다는 것입니다. 문제는 rare co-occurrences는 노이즈를 유발하고 자주 등장하는 경우보다 많은 정보를 포함하지 못합니다. 그런데 X의 75%에서 95% 정도의 원소는 값이 0입니다.
저자는 이 문제를 해결하기 위해 새로운 weighted least squares regression model을 제안합니다. 수식 (7)을 least squares 문제로 치환하고 가중치 함수 f(Xij)를 도입하면 모델은 다음과 같이 표현됩니다. Least squares problem은 MSE와 같이 차이의 제곱을 최소화하는 문제입니다. 수식에서 V는 어휘 사전의 크기입니다.
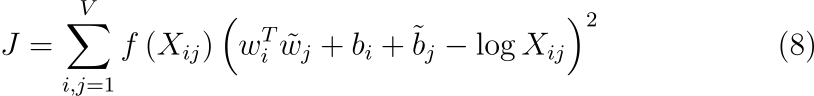
가중치 함수(weighting function)는 다음과 같은 성질을 따라야 합니다.
1. f(0)=0. f가 연속 함수이면 x→0 일 때 lim가 유한한 값에 수렴할 수 있도록 빠르게 0에 수렴해야 합니다. 그렇지 않으면 제곱항에 의해 rare co-occurrence의 값이 커질 수 있습니다.
2. f(x)는 rare co-occurrence의 가중치가 과도하게 커지지 않도록 감소함수가 아니어야 합니다.
3. f(x)는 빈도가 높은 co-occurrence의 가중치가 과도하게 커지지 않도록 큰 x 값에 대하여 비교적 작은 값을 가져아 합니다.
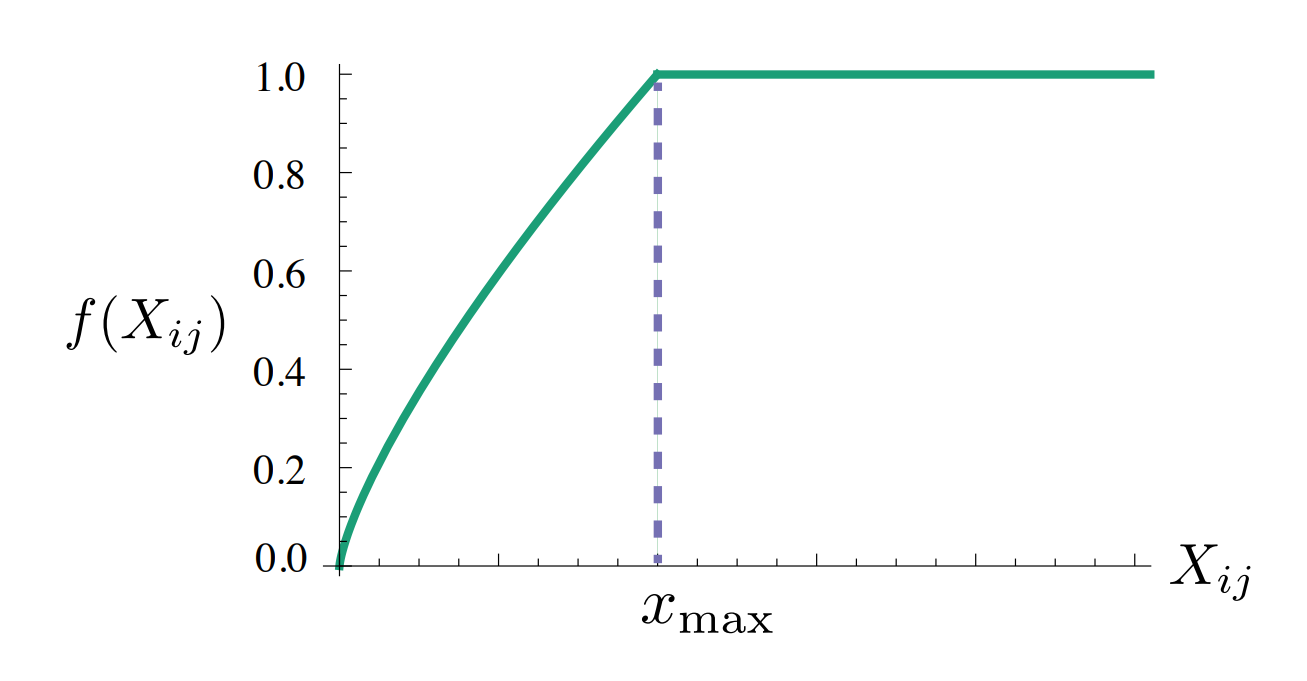
이러한 성질을 만족하는 함수는 다양하겠지만, 저자는 다음과 같은 함수를 사용하였습니다.
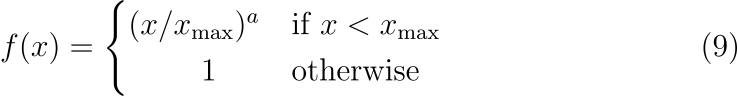
경계(cutoff)가 모델 성능에 미치는 영향이 약했고, 실험에서는 x_{\max}=100 으로 고정하였습니다. 또한 \alpha=1 인 선형함수보다 \alpha=3/4 일 경우 모델이 더 나은 성능을 보여 이 값을 사용하였습니다.
3.1 Relationship to Other Models
단어 벡터를 학습하는 모든 비지도 학습 기법은 occurrence statistics에 기반하기 때문에, 이 모델들 간의 공통점이 있을 것입니다. 그럼에도 불구하고 skip-gram이나 ivLVL과 같은 모델은 이런 규칙을 따르지 않습니다. 따라서 이런 모델들이 논문의 모델과 어떻게 연관되어 있는지를 알아보기 위한 연구가 수행되었습니다.
Skip-gram 또는 ivLBL 기법의 시작점은 단어 i에 대한 문맥에서 단어 j가 나타나는 확률을 Q_{ij}로 모델링 하는 것입니다. 여기서 Q_{ij}는 소프트맥스 함수라고 가정합니다.
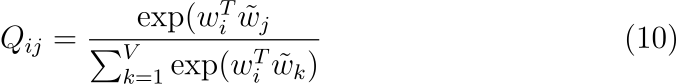
이 모델이 context window를 스캔하며 로그 확률을 최대화한다는 사실 이외의 다른 부분은 우리 목표와는 무관합니다. 학습은 on-line, stochastic하게 진행되지만 목적 함수는 다음과 같이 쓰일 수 있습니다.
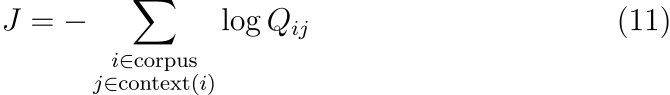
각 항에 대한 소프트맥스의 normalization factor를 측정하는 것은 비용이 많이 듭니다. 따라서 효율적인 학습을 위해서 skip-gram과 ivLBL 모델은 Q_{ij}에 대한 근사를 도입합니다. 하지만 수식 (11)은 먼저 i와 j가 같은 값을 갖는 항을 묶으면 더 효율적으로 계산할 수 있습니다. 동시 발생 행렬 X는 동류향에 대한 행렬이기 때문에 이와 같은 변형이 가능합니다.
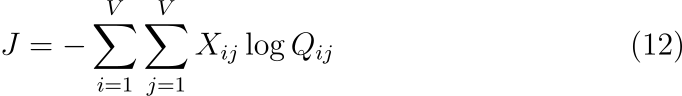
X_i=\sum_k X_{ik}이고 P_{ij}=X_{ij}/X_i 이기 때문에 J를 다음과 같이 쓸 수 있습니다.
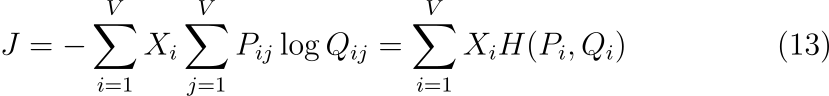
H(P_i, Q_i)는 각각의 확률 분포 P_i, Q_i 에 대한 크로스 엔트로피입니다. Cross-entropy error의 가중합이라는 점에서 이 목표 함수는 수식 (8)의 weighted least squares objectvie와 유사합니다. 그런데 위 수식은 단어 벡터를 학습하기 위한 모델로 사용되기에는 부적절한 속성을 갖습니다.
먼저 크로스 엔트로피는 확률 분포의 거리를 측정하는 여러 가지 방법 중 하나일 뿐이며 확률 분포의 long tail이 종종 일어날 것 같지 않은 사건에 과도하게 가중치를 할당하는 문제가 있습니다. 게다가 이 측정치에 bound를 설정하기 위해서는 Q가 적절하게 정규화되어야 합니다. 이는 연산 병목을 유발할 수 있습니다. 따라서 Q와 P의 normalization factor가 제거된 least squares objective를 사용하는 것이 더 적절합니다.
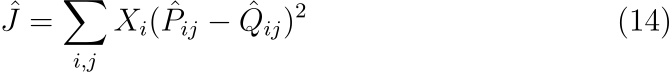
수식에서 \hat P_{ij}=X_{ij}이며, \hat Q_{ij}=\exp(w_i^T\tilde w_j)이고, 이들은 정규화되지 않은 분포입니다. 여기서 X_{ij}가 최적화를 어렵게 할 정도로 큰 값을 가질 때가 있다는 문제가 또 발생합니다. 이에 대한 효과적인 해결책은 두 확률 분포에 로그를 취하는 것입니다.
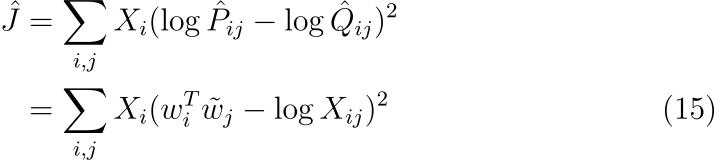
마지막으로 skip-gram이나 ivLBL 모델에서 내부적으로 결정된 weighting factor X_i가 최적의 값이라는 보장이 없다는 문제가 있습니다. 실제로 Mikolov는 데이터를 필터링하여 자주 등장하는 단어에 대한 가중치 계수의 값을 줄임으로써 성능을 향상시킬 수 있다는 사실을 발견하였습니다. 이를 염두에 두고 context word에 따라 유동적으로 사용할 수 있는 일반적인 가중치 함수를 도입하였습니다.
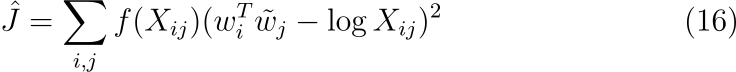
그리고 이 수식은 수식 (8)의 비용 함수와 동일합니다. 따라서 논문의 모델과의 연관성이 입증되었습니다.
3.2 Complexity of the model
수식 (8)과 weighting function f(X)에서 볼 수 있듯이 연산 복잡도는 모델의 0이 아닌 원소의 개수에 의해 결정됩니다. 이 값은 행렬의 모든 원소의 개수보다는 항상 작기 때문에 모델 복잡도는 \mathcal O(|V|^2)를 넘지 않습니다. 언뜻 보면 이는 연산량이 말뭉치의 크기 |C|에 비례하는 shallow window에 기반한 방법보다 성능이 개선된 듯 보입니다. 하지만 일반적으로 어휘 사전의 크기가 수백 또는 수천에 달한다는 것을 감안하면 |V|^2는 수천억이 될 수 있고, 이는 말뭉치의 크기보다 훨씬 큽니다. 따라서 0아 이난 요소에 대한 경계를 다르게 설정할 필요가 있습니다.
한 가지 방법으로 X_{ij}를 단어 쌍이 자주 등장하는 순위 r_{ij}에 대한 power-law function으로 모델링할 수 있습니다.

말뭉치 내의 모든 단어의 개수는 동시 발생 행렬 X의 모든 원소의 합에 비례합니다.
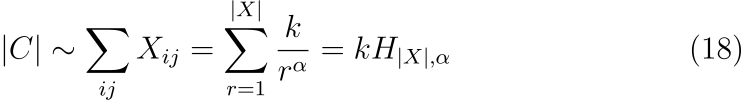
여기서 총합은 generalized harmonic number H_{n,m} 의 항으로 작성되었습니다. 이 합의 위끝(upper bound)인 |X|는 동시 발생 횟수에 대한 제일 낮은 등수(maximum frequency rank)인데 이 값은 이는 행렬에서 0이 아닌 원소의 개수와 일치합니다. 이 값은 또한 수식 (17)에서 r의 최댓값과도 같습니다. 즉 X_{i,j} \ge 1이고, 수식 (18)에서 위끝을 1이라고 하면 |X|=k^{1/\alpha}입니다. 그러면 수식 (18)을 다음과 같이 쓸 수 있습니다.

여기서 |X|와 |C|가 큰 값을 가질 때, 어떤 관련이 있는지를 알고 싶습니다. 따라서 큰 |X|에 대해서 수식의 우변을 확장할 수 있습니다. 이를 위해서 논문에서는 expansion of generalized harmonic numbers를 사용하였습니다.
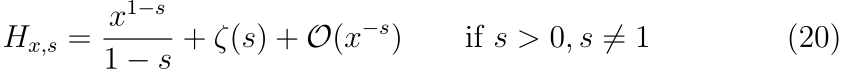
이를 수식 (19)에 대입하면 다음과 같이 정리됩니다.
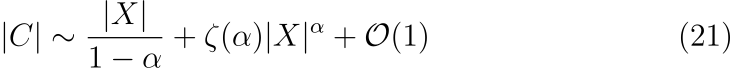
위 수식에서 \zeta(s)는 리만 제타 함수입니다. X가 크다라는 경계에서는 수식 (21)의 우변에 있는 두 항 중 하나만 연관되며, 이 항은 \alpha의 값에 따라 결정됩니다.
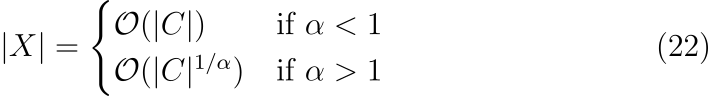
논문에서 사용된 말뭉치에서는 X_{ij}가 수식 (17)에서 \alpha=1.25일 때 잘 모델링된다는 것을 확인하였습니다. 여기서는 |X|=\mathcal O(|C|^{0.8})입니다. 따라서 모델의 복잡도는 최악의 경우인 \mathcal O(V^2)에 비해 훨씬 더 낫다는 것을 결론에 도달합니다.
4. Experiments
4.1 Evaluation methods
GloVe 모델의 성능은 단어 유추, 유사도 측정, 개체명 인식 세 가지 태스크로 평가되었습니다.
Word analogies
단어 유추는 word2vec에서도 설명되었듯이 “a가 b일때 c는 무엇입니까?” 라는 물음에 답하는 태스크입니다. 데이터셋은 19,544개의 문제로 구성되었고 w_d를 찾기 위해 w_b-w_a+w_c와 코사인 유사도가 가장 높은 단어 벡터를 선택합니다.
Word similarity
GloVe 모델은 단어 유추 태스크에 초점이 맞추어져 있지만 단어 유사도 테스트도 수행되었습니다. 사용된 데이터셋은 WordSim-353, MC, RG, SCWS, RW 입니다.
Named Entity Recognition
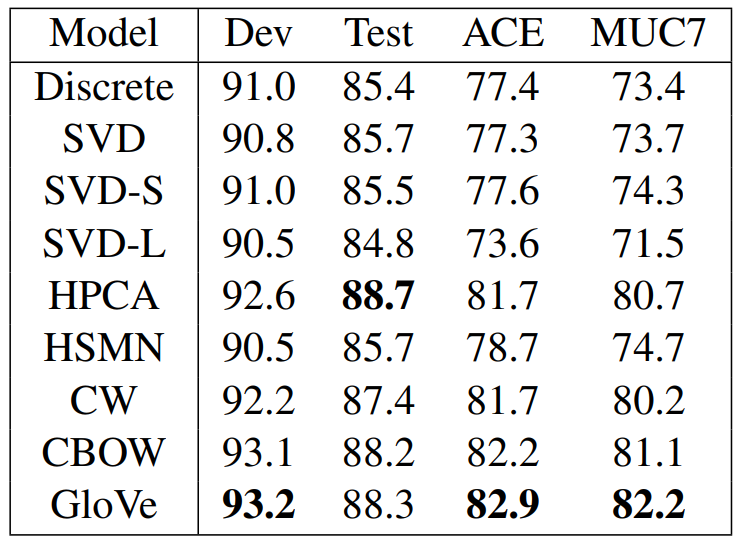
개체명 인식 태스크를 위한 CoNLL-2003 영어 벤치마크 데이터셋이 사용되었습니다. 이 데이터셋은 로이터 뉴스 기사를 사용하여 생성되었으며 사람, 장소, 기관, 기타로 레이블링이 되어있습니다. 모델 하습에는 CoNLL-test, ACE Phase2, ACE-2003, MUC7 Formal Run test가 사용되었고, BIO2 방식으로 태깅되었습니다. CoNLL 데이터셋에서 생성된 discrete feature와 GloVe 모델로 생성한 continuous feature를 Conditional Random Field(CRF) 학습을 위한 입력으로 사용되었습니다.
4.2 Corpora and training details
모델은 5개의 말뭉치로 학습되었습니다. 각각 10억 토큰으로 구성된 2010 Wikipedia, 16억 토큰의 2014 Wikipedia, 43억 토큰의 Gigaword 5, 60억 토큰의 Gigaword5+ Wikipedia2014의 조합과 420억 토큰의 Common Crawl입니다. Standford 토크나이저를 사용하여 토크나이징과 소문자 정규화가 수행되었고, vocabulary는 40만 개의 가장 많이 등장하는 어휘로 구성되었습니다.
동시 발생 행렬 X를 구성하기 위해서는 컨텍스트 윈도우의 크기를 정해야 하고 왼쪽 컨텍스트와 오른쪽 컨텐스트를 구분할지도 결정해야 합니다. 논문에선 decreasing weighting function을 사용하여, 거리가 d 만큼 떨어져 있는 단어쌍은 1/d 만큼 카운트되도록 하였습니다. 이는 가까이 위치한 단어일수록 더 많은 관련성이 있다는 전제를 바탕으로 합니다.
모든 실험에서 x_{\max}=100이고, \alpha=3/4가 사용되었습니다. 모델은 AdaGrad, 최초 학습률을 0.05를 사용하였고, X에서 0이 아닌 원소를 stochastic sampling하여 훈련되었습니다. 300 차원보다 작은 벡터는 50 iteration만큼 학습이 수행되었고, 그 외의 경우 100 iteration만큼 학습이 수행되었습니다. 컨텍스트의 크기는 왼쪽과 오른쪽 모두 열 개의 단어를 사용하였습니다.
모델은 두 종류의 단어 벡터인 W와 \tilde W를 생성하였습니다. X가 대칭(symmetric)이면 W와 \tilde W는 동일하며 차이는 임의 초기화(random initialization)의 결과로만 발생합니다. 반면에 특정 유형의 신경망은 여러 인스턴스를 훈련하고 결과를 종합하는 것이 과대적합과 노이즈를 방지하고 성능을 향상할 수 있습니다. 이에 유념하여 W+\tilde W를 단어 벡터로 사용하였습니다. 이를 통해 성능이 약간 향상되었습니다.
저자는 공개된 여러 모델과 \texttt{word2vec}툴을 사용하여 생성한 결과와 SVD를 사용한 몇 가지 베이스라인을 사용하여 성능을 비교하였습니다. \texttt{word2vec}을 사용하여 skip-gram(SG^\dagger)과 continuous bag-of-words(CBOW^\dagger)를 60억 토큰 말뭉치를 사용하여 훈련하였습니다. Negative sample은 10개를 사용하였습니다.
SVD 베이스라인에서 사용하기 위해, 가장 많이 사용된 10만 개의 단어에 대한 정보만을 갖는 truncated matrix, X_\text{trunc}를 생성하였습니다. 이 행렬이 singular vector는 SVD 베이스라인을 구성합니다. 또한 \sqrt{X_\text{trunc}}의 SVD를 취하는 SVD-S와 \log(1+X_\text{trunc})의 SVD를 취한 SVD-L을 사용하였습니다. 이 두 기법은 X의 값이 큰 범위에서 값을 압축하는 데 도움이 됩니다.
4.3 Results
단어 유추 태스크의 결과는 다음과 같습니다. GloVe가 가장 뛰어난 성능을 보였으며, 저자가 \texttt{word2vec}를 사용한 결과가 이전에 발표된 결과보다 조금 더 좋았습니다. 이는 다른 학습 말뭉치가 사용되었고, negative sampling이 hierarchical softmax보다 더 나은 성능을 보이기 때문이라고 추측됩니다. 또한 SVD-L의 예시에서 볼 수 있듯이 학습 데이터가 커질수록 항상 성능이 증가하는 것은 아님을 확인할 수 있습니다.
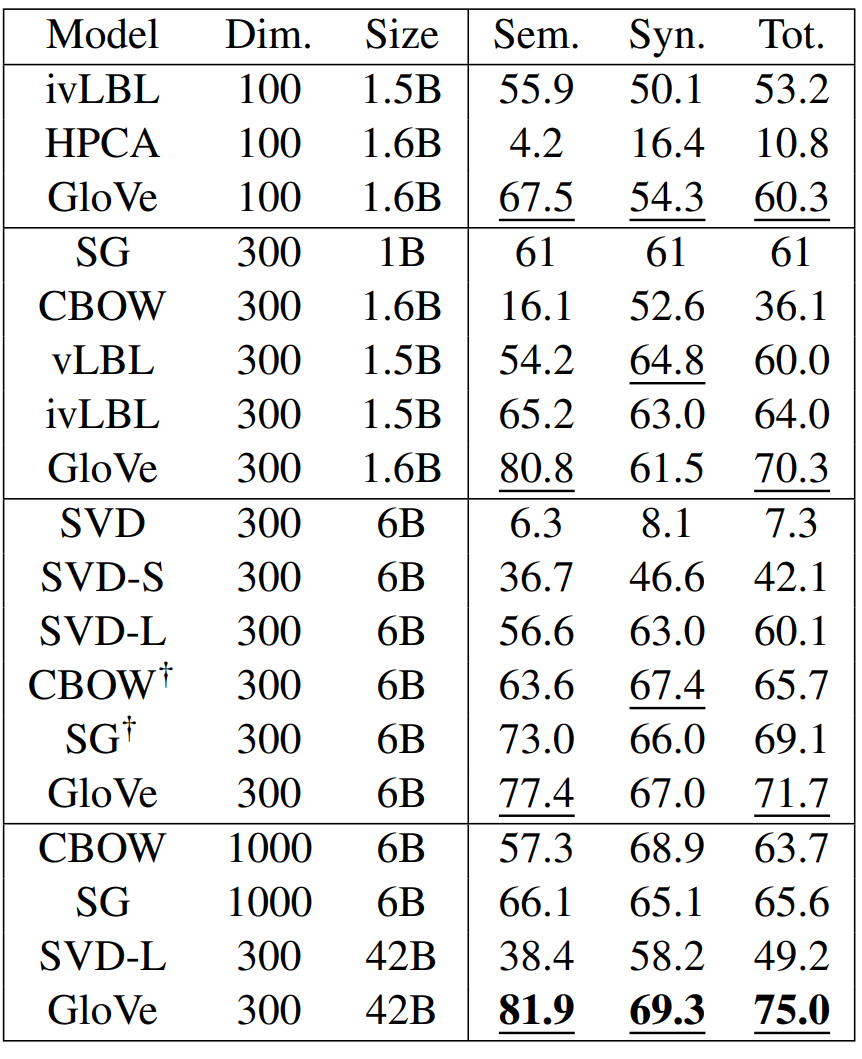
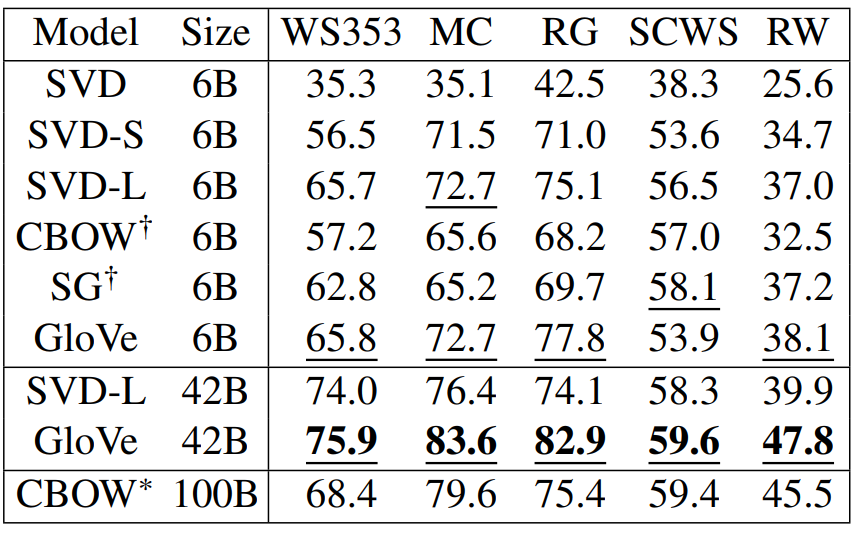
다음 표는 다섯 개의 유사도 평가 태스크에 대한 결과입니다. 유사도 점수는 단어 벡터의 각 특성(feature)을 정규화한 후 코사인 유사도를 계산한 결과입니다. 측정 지표로는 Spearman’s rank correlation coefficient가 사용되었습니다.
다음은 NER 태스크의 결과입니다. Discrete 레이블이 붙은 모델은 단어 벡터를 추가하지 않고, Standard NER 모델에서 유래한 discrete feature만을 사용한 모델입니다. 이 결과를 통해 GloVe 모델이 다운스트림 태스크에서도 유용하게 사용될 수 있다는 것을 알 수 있습니다.
Model Analysis
4.4 Vector Length and Context Size
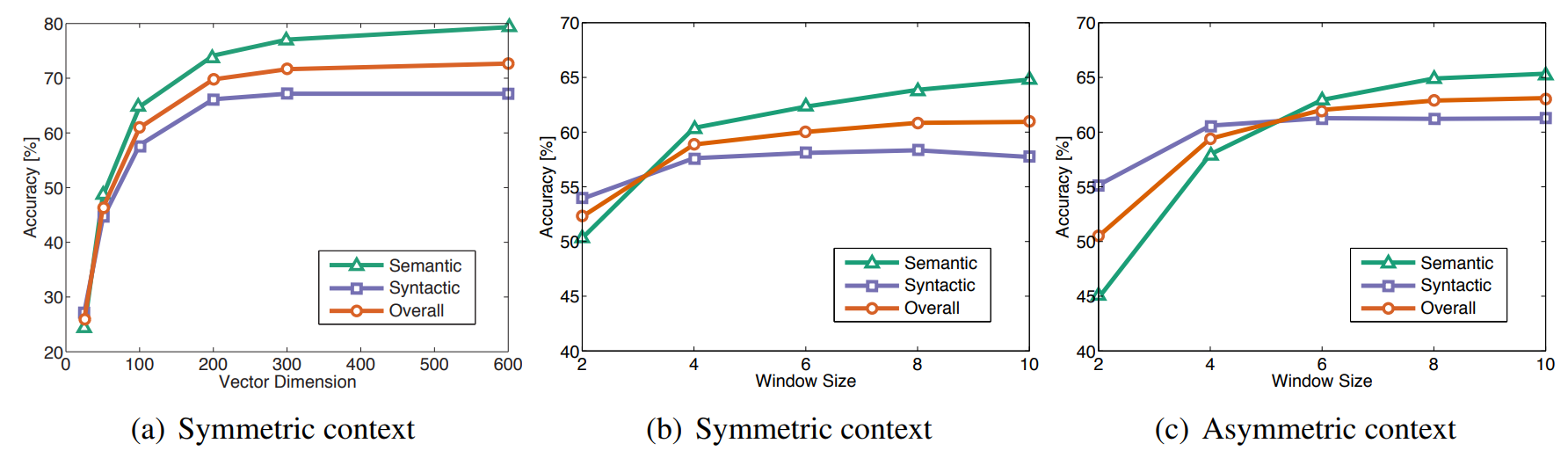
다음 그림은 벡터 길이와 컨텍스트 윈도우의 크기를 다르게 실험한 결과입니다. 왼쪽과 오른쪽의 컨텍스트 크기가 같을 경우 symmetric, 왼쪽 컨텍스트만 사용할 경우 asymmetric입니다. (a)에서 벡터의 차원이 200보다 클 경우 성능이 감소함을 알 수 있고, (b)와 (c)에서 윈도우 크기에 따른 성능을 확인할 수 있습니다.
Syntactic 태스크에서는 작고 asymmetric한 컨텍스트 윈도우가 좋은 성능을 보였습니다. 이는 통사론적 정보가 단어 순서에 영향을 많이 받고 인접한 단어에 많이 포함되어있다는 직관과 일치합니다. 반면 semantic 태스크에서는 큰 윈도우가 더 좋은 성능을 보였습니다.
4.5 Corpus Size
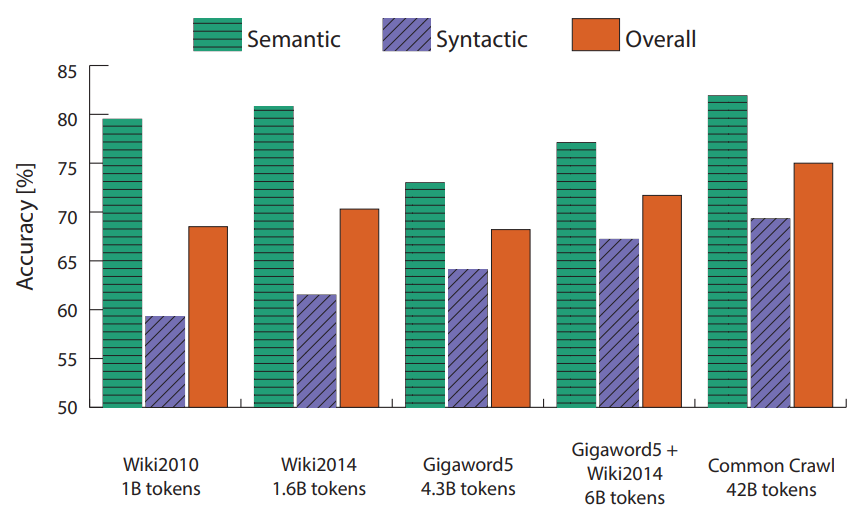
다음 그림을 통해 학습 데이터의 크기에 따른 성능을 확인할 수 있습니다. Syntactic 태스크는 이 영향을 많이 받는 편이지만, semantic 태스크는 꼭 그렇지만은 않습니다. 또한 Wikipedia 데이터의 특성이 성능에 영향을 미쳤을 가능성도 있습니다.
4.6 Run-time
전체 실행 시간은 X와 모델에 영향을 받습니다. 동시 발생 행렬 X는 또한 컨텍스트 윈도우, 어휘 사전, 데이터셋의 크기 등 여러 요인에 영향을 받습니다. 다음은 각 모델에 대한 학습 곡선입니다.
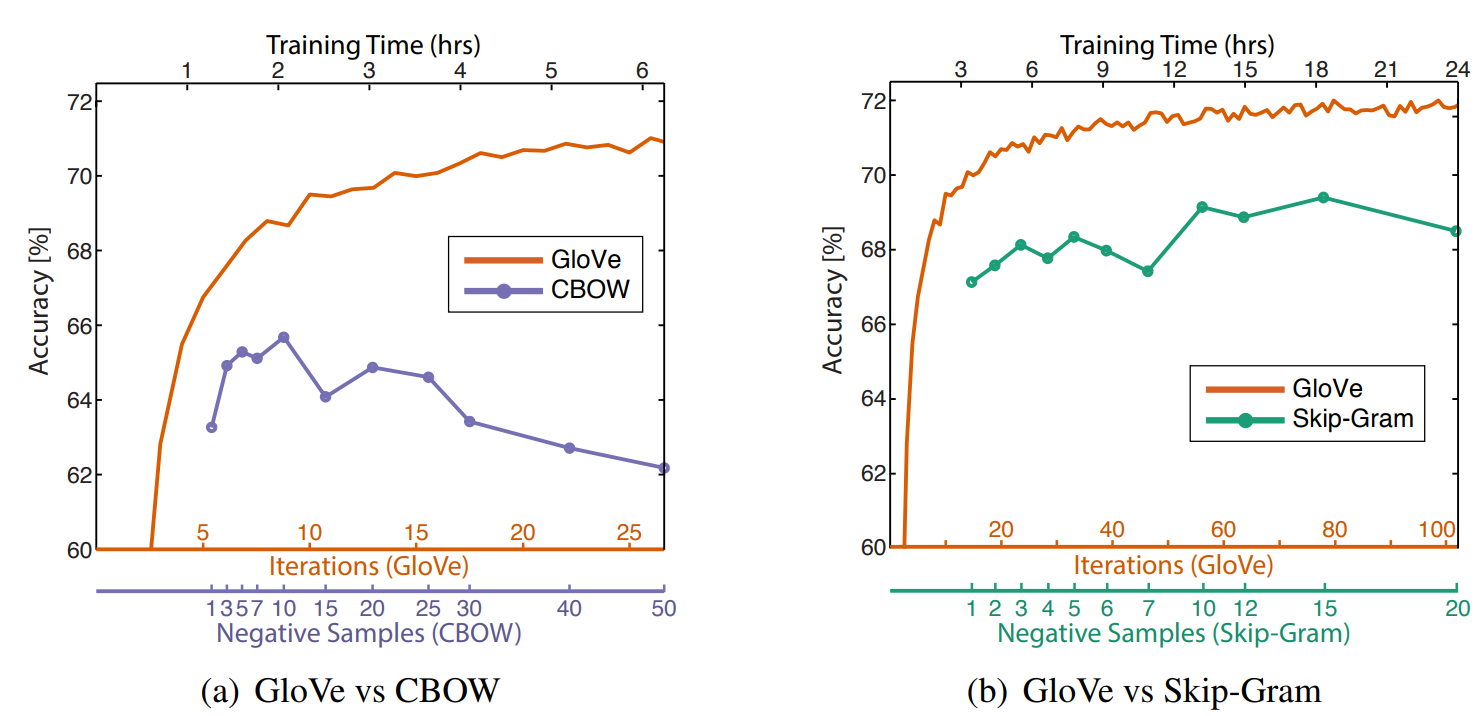
4.7 Comparison with word2vec
GloVe는 training iteration이 모델 학습과 연관된 파라미터이며 word2vec은 학습 에포크가 중요합니다. 그런데 공개된 word2vec 모델은 1 에포크 학습을 위해서만 설계되었기 때문에 저자는 negative sample을 추가하여 여러 에포크를 학습한 것과 같은 효과가 나타나도록 하였습니다. 실험 결과는 위 그림의 우측에서 확인할 수 있습니다. GloVe가 모든 실험에서 word2vec보다 뛰어난 성능을 보임을 알 수 있습니다.
5. Conclusion
당시 동시 발생 횟수에 기반한 방법과 예측에 기반한 방법 중 어떤 것이 단어 벡터를 학습하는 데 더욱 효과적인지에 대한 의문이 제기되었습니다. 이 논문에서는 두 기법이 본질적으로 다르지 않다는 것을 입증합니다. 논문에서는 단어의 등장 횟수에 기반한 방법을 설계하면서 동시에 lig-bilinear prediction-based 기법에서 흔히 나타나는 선형 특성을 갖는 모델을 구축하였습니다. GloVe는 새로운 global log-bilinear 회귀 모델로 단어 유추, 유사도 측정, 개체명 인식 태스크에서 다른 모델보다 뛰어난 성능을 보여주었습니다.
6. Reflection
이 논문은 특히 수식이 많고 고급 수학 개념이 많이 등장해서 길이에 비해 읽는 시간이 정말 많이 들었던 것 같습니다. 그마저도 리만 제타 함수 등 일부 개념에 대해서는 구체적으로 알아보진 못했습니다. 전체적인 수식의 흐름이 어떻게 진행되는지 위주로 homomorphism이라든지, 군, bilinear 등에 대한 개념을 따로 공부했습니다. 수식이 워낙 많고 머신러닝 기저에 깔린 원론적인 부분을 수학적으로 해석한 게 그래도 재미있기도 하고 저자의 통찰이 놀랍다는 생각이 들었습니다. 혹시 저자 중 수학을 전공한 분이 있는지 찾아봤지만 특별히 그런것 같진 않았습니다. 그냥 기본적으로 머신러닝이라는 분야가 통계와 수학에 영향을 많이 받았기 때문에 기초를 이루는 개념들에 수학이 많이 사용된 것 같습니다. word2vec과 다르게 어떤 단어 벡터를 학습하는 완전히 새로운 기법이라기보다는, 기존의 모델들을 재해석하고 수학적인 개념을 통해 확장했다는 느낌이 들었습니다. 덕분에 논문을 읽으며 임베딩에 대한 전반적인 개념을 점검해 볼 수 있었습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] Word Translation Without Parallel Data (1) (0) | 2023.11.04 |
|---|---|
| [논문리뷰] Enriching Word Vectors with Subword Information (1) | 2023.10.29 |
| [논문리뷰] Attention Is All You Need (1) | 2023.10.24 |
| [논문리뷰] Linguistic Regularities in Continuous Space Word Representations (0) | 2023.10.20 |
| [논문리뷰] Distributed Representations of Words and Phrases and their Compositionality (1) | 2023.10.19 |




댓글