인공지능이 사회의 모든 측면을 변화시키는 지금 시대에 딥러닝은 기술 혁신의 한 축으로 자리 잡고 있습니다. 그에 따라 관련 기술과 개념을 학습하기 위한 노력도 많이 이루어지고, 이를 위한 컨텐츠도 꾸준히 생성되고 있습니다. 수많은 양질의 도서나 튜토리얼에 손쉽게 접근할 수 있지만, 딥러닝을 공부할 때는 특히 논문 읽기의 중요성이 많이 강조되곤 합니다. 단순히 사전 학습된 모델과 공개된 데이터셋을 가져와서 모델을 구현하고 문제를 해결하는 데 그친다면, 원론적인 개념에 접근할 필요성을 느끼지 못할 수도 있습니다. 하지만 널리 사용되는 딥러닝 개념의 기저에 깔린 알고리즘과 여러 기법들이 등장할 수 밖에 없었던 이유에 대해 깊이 있게 탐색하고 싶다면 학술 논문을 필수적으로 접하게 됩니다.
그런데 학술 논문은 단순히 대부분의 경우 영어로 쓰여있다는 것 외에도 그 형식과 내용이 생소해서 진입 장벽이 결코 낮다고 볼 수가 없습니다. 그렇다면 처음 논문 읽기를 시작할 때, 어떤 방식으로 접근하면 좋을 지 한번 정리해보았습니다. 물론 저도 많은 논문을 읽었다고 말하기엔 아직 한참 부족하지만, 그래도 최근 꾸준히 논문을 읽으며 경험적으로 알게 된 내용에 대해서 나누고 입문하는 분들께 도움이 되었으면 하는 마음에 이 글을 작성하게 되었습니다. 잘못된 내용이나 보충하면 좋을 부분이 있다면 말씀해주셨으면 합니다.
논문을 읽어야 하는 이유
먼저 진부한 이야기이지만, 논문 읽기가 왜 중요한지에 대해서 먼저 점검해보겠습니다. 당연하게도 관련 도서나 강의 같은 2차 자료는 주로 핵심적인 내용만을 빠르게 전달하는 데 집중하기 때문에 논문의 모든 내용을 담지 못합니다. 딥러닝은 디테일이 매우 중요한 분야인데, 논문에서는 사용된 방법론을 꼼꼼하게 설명하고 실험 설계, 알고리즘, 데이터셋에 대한 정보를 있는 그대로 제공합니다. 이를 통해 제안된 기법이 성공할 수 있었던 이유에 대해서 깊이 있게 탐색할 수 있고, 단순화된 설명에서는 놓치기 쉬운 귀중한 인사이트를 얻을 수 있습니다. 또한 논문에는 제안된 방법이 등장하게 된 배경을 자세히 소개하는데, 이를 통해 관련 분야가 어떤 과정을 거쳐서 발전할 수 있었는지를 알 수 있게 됩니다. 이 부분에 대해서는 조금 뒤에 자세히 설명하겠습니다.
논문을 찾는 방법
논문을 읽기에 앞서 논문에 접근하는 방법부터 간단히 알아보겠습니다.
가장 쉬운 방법은 당연히 논문의 제목을 그대로 검색하는 것입니다. 예를 들어 트랜스포머 아키텍처가 제안된 논문 ‘Attention Is All You Need’를 구글에 검색해보겠습니다. 다음과 같은 화면이 나올텐데, 일반적으로는 arXiv를 통해서 논문에 접근하게 됩니다. 논문이 제안된 컨퍼런스나 Google Scholar를 사용하는 방법도 있겠지만, arXiv 위주로 설명하겠습니다.

클릭해서 들어가면 다음과 같은 페이지를 볼 수 있습니다. 여기서 논문의 제목과 저자, 초록을 확인할 수 있는데 전부 논문에 나와있는 내용이라 미리 읽어도 되고 그렇지 않아도 괜찮습니다. 우측의 Access Paper 섹션에서 Download PDF를 클릭하여 원본 파일을 다운로드 받을 수 있습니다.
다음과 같은 화면을 보게 될 텐데, 웹 브라우저에서 PDF를 열 수 있다면 이와 같은 화면이 나올 것이고 아니면 파일로 다운로드 받은 후에 열면 다음과 같이 논문의 내용을 확인할 수 있습니다.
참고로 주소창에서 arxiv를 ar5iv로 변경하면 다음과 같이 논문의 내용 전체를 웹 페이지 형태로 열람이 가능합니다. 이 기능이 완전하진 않고, 일부 논문의 경우 지원이 되지 않거나, arXiv에 등록되지 않은 문서의 경우 사용할 수 없지만, 그래도 꽤 유용한 팁입니다.
다시 설명하자면 arxiv.org/abs/1706.03762에서 arxiv의 x를 5로 바꾸면, ar5iv.labs.arxiv.org/html/1706.03762로 리디렉션되며 다음과 같은 페이지가 나타납니다.
웹페이지로 논문을 열람하게 될 경우의 장점은 웹 브라우저에서 사용하는 익스텐션을 그대로 사용할 수 있다는 점입니다. 예를 들어서 DeepL extension을 사용한다고 하면, PDF의 경우 드래그 후 번역이 불가능하지만, 웹 페이지에서는 다음과 같이 드래그를 통한 번역이 가능합니다. 물론 학술 논문의 경우 특정 도메인에서만 사용하는 용어가 많아 번역이 부정확한 경우가 대부분이지만, 종종 유용하게 사용될 때가 있습니다.

논문의 정확한 제목을 모를 때는 ‘Transformer paper’와 같이 키워드를 사용해 검색하면 꽤 높은 정확도로 관련 논문에 접근할 수 있습니다. 그리고 특정 논문을 정해놓지 않고, 관련 분야의 주요 논문을 읽고 싶을 때는 ‘Must read papers in (keyword)’로 검색하면 일반적으로 중요하게 생각되는 논문에 대해서 정리한 글이나 GitHub 레포지토리가 많이 검색됩니다.
논문의 각 파트를 읽는 방법
이제 본격적으로 논문을 어떻게 읽어야 하는지에 대해서 알아보겠습니다. 물론 논문 읽기에 정답은 없겠지만, 여기서 언급하는 내용은 일반적인 가이드라인입니다. 그리고 가급적 지양했으면 하는 방법도 말씀드리겠습니다.
먼저 논문의 구조를 알아보며 각 부분에서 얻어가야 할 내용을 정리하겠습니다. 일반적으로 논문의 첫 페이지는 다음과 같이 제목, 저자, Abstract를 포함한 구조를 갖습니다. 구성에 따라 이 논문과 같이 1단으로 된 경우도 있고, 2단으로 된 경우도 있는데 여기서는 트랜스포머 논문을 기준으로 설명하겠습니다.

Title
먼저 빨간 상자로 표시한 제목입니다. 이 논문의 경우 제목이 많은 내용을 담진 않지만, 많은 경우 논문의 제목은 전체를 한 마디로 요약하는 핵심적인 역할을 합니다. 이 논문의 경우 ‘Attention이 필요한 전부이다!’라고 외치며 어텐션 메커니즘의 중요성에 대해서 강조하고 있습니다. 또 다른 예시로 이전에 리뷰한 논문인 PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization에서는 abstactive summary 태스크를 위한 새로운 사전 학습 방법론을 제시하였는데 Extracted Gap-sentences를 활용한 것이겠구나하고 제목을 통해 논문의 내용을 어느정도 유추할 수 있습니다.
Author
다음은 주황색 상자로 표시한 저자입니다. 일반적으로 간과하기 쉬운 부분인데, 특정 주제에 대해서 깊이 있게 알고 싶다면 한 번쯤 눈여겨봐야 할 부분입니다. 보통 연구자는 한 분야에 대한 깊은 이해를 가지고 논문을 작성하며, 이는 개인이 아니라 하나의 연구실 또는 기업 단위로 이루어집니다. 따라서 논문의 저자나 그가 소속된 곳은 딥러닝 아키텍처에 관련된 연구를 이전에도 계속해서 수행하였고, 앞으로도 수행할 가능성이 매우 높습니다. 그렇기 때문에 이 주제에 대해서 깊이 있게 공부하고 싶다면 저자나 연구 기관을 관심 있게 살펴보고 그들이 수행한 또 다른 연구에 대해 알아보면 도움이 됩니다.
Abstract
그 다음은 노란색 상자로 표시한 Abstarct, 초록 부분입니다. 이 부분은 사실상 논문 전체에서 가장 공들여 작성된 부분이라고 생각해도 무방할 것 같습니다. 실제로 초록만 잘 써도 논문에 대한 평가가 달라진다라는 이야기를 종종 들을 정도로 이 부분은 중요합니다. 여기는 논문에 담겨야 하는 모든 내용이 요약되어 있습니다. 즉, 논문 전체를 읽지 않더라도 해당 논문의 내용을 파악할 수 있도록 도와주는 부분입니다. 따라서 처음 논문을 접하게 되면, 논문에 대한 이해를 돕기 위해서라도 매우 꼼꼼히 읽어야 합니다. 물론 논문 전체를 꼼꼼히 읽고 리뷰하겠다라는 생각이라면 그리 중요하지 않을 수도 있습니다. 하지만 향후 수많은 논문을 접하게 될 텐데 모든 논문을 읽을 여건이 되지 않을 때, 초록만 제대로 읽어도 이 논문이 내게 필요한지 아닌지를 빠르게 판단할 수 있게 됩니다.
이후의 내용은 실질적으로 논문의 연구 내용이 담긴 부분입니다. 논문이 제출된 기관에 따라서 양식이 다를 순 있지만, 전체적인 틀은 비슷합니다.
Introduction
이 부분은 최근 연구 동향과 논문에서 다루는 태스크에 대한 설명, 그리고 논문의 연구에 대한 간략한 소개를 담고 있습니다. 같은 주제에 대한 논문을 여러 개 읽다보면 비슷한 내용이 반복적으로 등장하게 됩니다. 그래서 종종 특정 분야나 태스크를 자주 접하는 경우에는 건너뛰게 되는데, 논문을 처음 읽는 상황을 가정하면 이 논문이 쓰인 계기, 그리고 이런 방법론이 등장할 수밖에 없는 배경에 대해서 이해하는 데 필수적인 부분입니다.
Related Works
Related Works 또는 Background는 해당 논문과 관련이 있는 연구를 소개하는 부분입니다. 이 연구에서 직접적으로 참고하고 있는 논문들을 세부 분야별로 정리하고, 기존 연구에서 어떤 contribution이 이루어졌는지, 그리고 그와 관련해서 어떤 한계가 존재하는지를 소개합니다. Introduction과 마찬가지로 특정 태스크에 익숙할 경우 반복적인 내용 때문에 건너뛰게 되는 부분이지만, 처음 접하는 상황에서는 논문에서 다루는 배경지식을 전반적으로 다루기 때문에 중요한 부분입니다.
Proposed Methods
논문에서 제안하는 모델 아키텍처와 방법론을 자세하게 설명하는 부분입니다. 사실상 논문의 핵심이라고 볼 수 있으며, 가장 자세히 살펴보고 이해해야 하는 부분입니다. 보통 새로운 연구에 대한 이해를 돕기 위한 그림이 포함되어 있으며, 실제로 제안된 방법론이 어떻게 작동하는지를 수식을 통해 설명합니다. 이 파트는 논문을 읽는 목적에 관계없이 반드시 읽어야 하는 부분이라고 볼 수 있습니다.
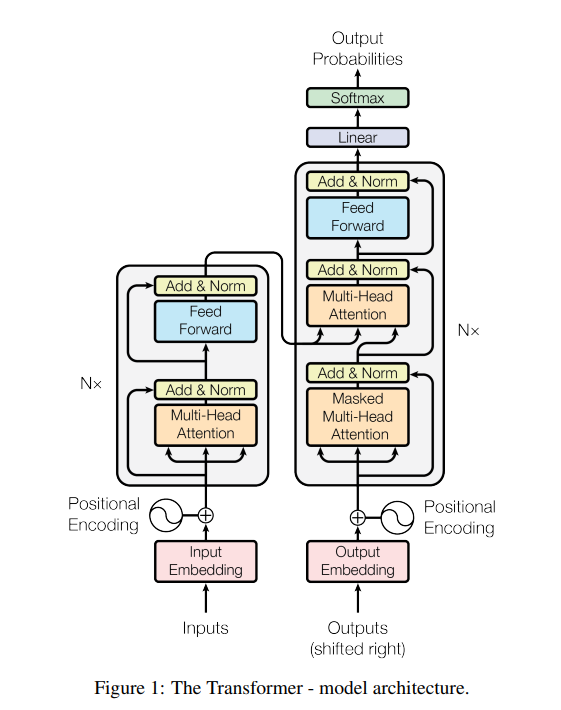

참고로 이 부분의 제목은 논문마다 다른데, 일반적으로 논문에서 제안하는 방법론을 그대로 제목으로 사용되고, Related works 뒤에 바로 위치하는 경우가 많습니다.
Experiments
여기서는 논문에서 제안한 방법론의 성능을 입증하기 위해 수행한 실험을 설계한 과정을 소개합니다. 먼저 어떤 태스크에 어떤 데이터셋을 사용하여 실험을 수행하였는지, 그리고 어떤 측정 지표를 사용하여 검증하였는지를 소개합니다.
그리고 논문에서 제안한 방법론을 사용한 모델을 설계한 방법과, 이와 비교하기 위해 사용한 베이스라인 모델들을 자세히 설명합니다. 추가로 각 모델의 하이퍼파라미터는 어떻게 설정되었는지와, 사용된 하드웨어와 함께 학습 시간이나 연산 비용이 어느 정도인지를 구체적으로 명시해둡니다.
Results
Experiments에서 설계한 실험의 결과를 정리한 부분입니다. 여기서 핵심은 수치에만 집중하는 게 아니라 해당 결과가 어떻게 도출되었는지에 집중해야 합니다. 예를 들어 사용된 데이터셋의 크기는 어떠한지, 모델의 파라미터 수와 훈련 시간, 연산 복잡도는 어떠한지를 눈여겨봐야 합니다.
물론 널리 알려진 주요 논문들의 경우 이 모든 요소를 고려해도 일반적으로 좋은 성능을 내는 경우가 많지만, 일부 연구의 경우 특정한 상황에서만 높은 성능을 보이는 경우가 있기 때문에 이 부분을 잘 파악해야 합니다. 예를 들어서 새로운 방법론에 대해 제안한 논문에서, 베이스라인 모델에 비해서 훨씬 더 큰 데이터셋을 사용하여 학습한 후 성능이 개선되었다고 한다면, 논문에서 제안한 모델의 성능에 대해 신뢰하기 어려울 수 있습니다. 또한 비슷한 데이터로 학습되었다고 하더라도 제안된 모델의 파라미터 수나 훈련 시간이 기존에 비해 과도하게 많아진다면 이 또한 효용을 의심할 수밖에 없습니다.
또한 이 부분에는 결과에 대한 저자의 해석이 담겨있기 때문에, 왜 그런 결과가 나왔는지를 이해하는 데 도움이 됩니다. 성능이 개선되었다면 어떤 이유 때문인지, 반대로 성능이 향상되지 않은 원인이 무엇인지에 대한 저자의 생각이 담겨있어, 많은 인사이트를 얻을 수 있는 부분입니다.
Conclusion
논문과 실험에 대한 결론이 담긴 부분입니다. 사실 상 Abstract와 Conclusion에서는 비슷한 내용을 다루기 때문에 처음 논문을 읽을 때는 이 두 부분을 읽으면 빠르게 논문의 전체적인 내용을 파악할 수 있습니다. 한 가지 다른 점은 보통 결론 부분에서는 논문의 연구 내용의 한계를 저자가 스스로 지적하고 향후 연구할 방향에 대해서 언급하는 경우가 많이 있기 때문에, 앞으로의 연구가 어떻게 이루어질지에 대해서 알 수 있습니다.
References
이 부분을 읽는다고 하기에는 조금 부적절하지만, 논문 중간에 구체적으로 설명되지 않은 배경지식이 있을 때 관련 논문을 참고하면 도움이 될 때가 많습니다. 예를 들어 트랜스포머 논문에서 residual connection이 언급되긴 하지만, 이것이 구체적으로 어떤 개념인지는 설명하지 않습니다. 이에 대해서 자세히 알아보고 싶을 때는 관련 논문을 참고하면 논문의 내용을 더 깊이 이해할 수 있게 됩니다.
당연히 레퍼런스 논문을 모두 읽어야 하는 것은 아닙니다. 논문 하나를 읽을 때마다 이렇게 한다면 시간이 너무 오래 걸리기 때문에, 배경지식만을 공부하고자 할 경우 abstract나 method 부분만을 빠르게 읽는 것이 하나의 방법이 될 것입니다.


Appendix
일반적으로 이 부분은 자세히 읽지 않는 경우가 많습니다. 여기까지 꼼꼼히 읽어야 한다는 것은 아니지만, 만약 논문에서 수행한 실험에 대해 매우 구체적으로 알고싶을 경우에 추가적인 정보를 얻는 데 도움이 되는 부분입니다. 여기에서는 보통 사용한 데이터셋에 대해서 자세히 다루거나, 논문의 수식이 도출된 과정을 설명하거나, 논문의 모델에서 사용한 하이퍼파라미터를 그렇게 결정한 이유에 대해서 자세히 설명하는 경우가 많습니다.
참고로 최근에 많이 발표되는 LLM 논문에서는 새롭게 제안한 LLM이 수행한 여러 태스크의 결과를 소개하는 내용을 주로 포함합니다.
논문을 읽을 때 도움이 되는 팁
논문을 처음 읽을 때 도움이 되는 몇가지 팁을 소개하겠습니다. 앞서 언급했듯이 논문의 핵심 내용을 빠르게 파악하고 싶을 때는 Abstract와 Conclusion만을 먼저 읽는 것도 좋은 방법입니다. 그리고 논문에서 실제로 제안하는 내용이 무엇인지를 알아보기 위해서 Proposed Methods를 자세히 읽어보면 됩니다. 논문을 잘 이해하기 위해서는 능동적으로 이 논문이 등장하게 된 이유와 이 논문이 관련 태스크에 기여한 내용을 파악하면 좋습니다. 또한 저자가 설계한 모델이나 수행한 실험에 대해서 의문을 던지고 이를 해소하는 방법으로 논문을 읽다보면 더욱 도움이 되는 것 같습니다.
예를 들어서 Neural Machine Translation by Jointly Learning to Align and Translate에서 제안한 어텐션 메커니즘은 분명 인코더의 정보 병목 현상을 해소하긴 하지만, 양방향 LSTM은 여전히 RNN의 본질적인 문제인 long-term dependency를 해결하지 못한다는 문제를 갖는다고 생각했습니다. 그래서 이런 문제를 해결하고 global dependency를 학습할 수 있는 Transformer 아키텍처가 제안되었다고 해석하였습니다. 이런 흐름으로 논문을 읽고 자신이 가진 배경지식과 연관짓다 보면 전반적인 연구의 흐름에 대해서 이해하는 즐거움을 얻을 수 있다고 생각합니다.
논문 구현 코드를 참고하기
추가로 논문을 읽고 실제 구현해보고 싶다면 논문에 명시된 GitHub 레포지토리를 통해 원본 코드를 참고할 수 있습니다. 또는 paperswithcode, lambl.ai 등을 참고하여 공식 구현 코드 뿐만 아니라 다른 사람들이 논문을 참고하여 구현한 코드를 확인할 수도 있습니다.
결국 읽는 목적에 따라 논문을 어떻게 읽어야 하느냐도 달라지겠지만, 일반적으로는 Abstract, Conclusion, Proposed Methods는 주의깊게 읽는 게 좋은 것 같습니다. 논문 전체의 내용을 꼼꼼히 읽고 이해하려는 목적이라면 오히려 Abstract의 중요성이 덜 강조될 수도 있습니다. 논문에서 제안한 개념이 등장한 배경을 이해하려면 Introduction이나 Related work가 강조될 것이고, 논문에서 사용한 기법을 내 프로젝트나 모델에 직접 적용하려는 목적이라면 Experiments나 Results 부분이 더욱 강조될 것입니다. 이처럼 논문은 읽는 목적에 따라 가중치가 달라지겠지만, 보통 관련 개념을 공부하려면 언급했듯이 Background를 다루는 부분들에 조금 더 집중하게 되는 것 같습니다.
논문 읽기는 분명 진입 장벽이 높고, 기술적으로 난해한 내용을 포함했다는 문제 외에 단순히 영어로 작성되었다는 이유만으로도 분명 꺼려지는 일입니다. 그래도 논문을 읽다 보면 관련 개념을 정말 깊이 있게 이해할 수 있고, 뛰어난 연구자들은 어떤 시각으로 문제에 접근하였는지에 대한 인사이트를 얻을 수 있는 좋은 경험이라고 생각합니다. 부수적인 효과이지만, 논문을 읽는 과정에서 영어 실력도 많이 향상될 수 있다는 점에서도 꽤 가치있는 일이라고 생각합니다. 영어를 위한 영어 공부보다, 이런 식으로 관심 있는 주제에 대해서 공부하는 겸 영어 실력도 늘릴 수 있다보니 개인적으로는 특히 도움이 많이 되었다고 생각합니다.
'ML, DL Basic' 카테고리의 다른 글
| GPT 이해하기, GPT-2까지 (0) | 2023.11.07 |
|---|---|
| Attention과 Query, Key, Value (1) | 2023.10.26 |
| Hierarchical Softmax 자세히 알아보기 (0) | 2023.10.20 |
| 딥러닝의 역사 알아보기 (2) | 2023.10.18 |
| 다양한 성능 평가 지표와 F1 점수 (1) | 2023.10.12 |




댓글