딥러닝 분야의 핵심 논문 중 하나인 Attention Is All You Need는 트랜스포머(Transformer)라는 새로운 아키텍처를 제안합니다. 자연어 처리의 많은 문제는 어떤 문장을 입력으로 받아 그에 대한 출력을 문장으로 내놓는 형태로 정의됩니다. 예를 들어 질문 답변, 요약, 번역 등의 태스크는 각각 질문, 전체 문서, 원어로 된 문장을 입력으로 받아 답변, 요약문, 번역어로 된 문장을 출력으로 합니다. 기술적인 표현으로는 입력과 출력이 모두 시퀀스로 나타나는 sequence-to-sequence 모델이라고 부릅니다. 논문에서는 이런 모델을 시퀀스 변환 모델(sequence transduction model)이라고 하며, 당시 사용되는 대부분의 시퀀스 변환 모델은 인코더-디코더 아키텍처를 갖는다고 말합니다.
인코더-디코더 아키텍처
Sequence to Sequence Learning with Neural Networks 논문에서 인코더-디코더 아키텍처가 제안된 이후 대부분의 seq2seq 모델은 이 구조를 따랐습니다. 이 아키텍처에서 인코더는 LSTM과 같이 시퀀스를 처리할 수 있는 신경망을 활용하여 입력 시퀀스의 정보를 잘 표현하는 벡터를 만듭니다. 디코더는 인코더가 만든 벡터를 바탕으로 출력 시퀀스를 생성합니다. 이 때 출력 시퀀스의 각 토큰은 순서대로 한 번에 하나씩 생성됩니다.
번역 태스크로 예를 들면, 먼저 인코더가 원본 문장을 잘 표현하는 어떤 벡터를 생성합니다. 디코더는 이 벡터를 받아 번역 문장을 생성하기 시작합니다. 처음에는 인코더에서 전달받은 벡터 외에 가진 정보가 없기 때문에 이 벡터만을 사용하여 첫 번째 단어를 생성합니다. 그 후에는 이 전에 자신이 생성한 각 단어와 인코더의 벡터를 함께 참고하여 번역을 진행하게 됩니다.
논문에서는 다음과 같은 그림으로 설명되는데, 문장 “A B C”를 입력받아 문장 “W X Y Z”를 출력하는 상황을 생각하면 됩니다. 그림에서 사각형은 모델을 의미하는데, 여니 모델이 연결되어 있는 게 아니라, 같은 모델을 시간 축에 따라 펼쳐놓은 것입니다. 여기서 수평 화살표는 현재까지 주어진 정보를 잘 압축하여 표현한 벡터(hidden state)가 주어지는 상황이며, 수직 화살표는 각 단계에서 단어의 벡터가 모델에 주어지는 것을 의미합니다.

어텐션 메커니즘
그런데 인코더-디코더 아키텍처는 치명적인 문제점이 있습니다. 앞서 언급했듯 각각의 요소에 사용되는 신경망이 RNN을 기반으로 하는데, RNN은 시퀀스의 길이가 길어지면 처음에 입력받은 정보에 대해서 점점 잊게 된다는 것입니다. 이 문제는 RNN이 입력 시퀀스를 고정된 벡터에 매핑하기 때문에 발생합니다. 아무리 긴 문장이라도 사전에 지정한 길이의 벡터에 전부 담으려고 하다보면, 문장의 뒤로 갈수록 앞의 내용을 어느 정도 포기하게 될 것입니다. 사람에 비유하면 아주 긴 정보를 들은 후 정리하면, 자신이 들은 내용에 대한 전반적인 내용을 기억하긴 하지만, 초반 부에 들었던 정보에 대한 기억은 많이 흐릿해졌을 것입니다.
이런 문제를 해결하기 위해서 어텐션(attention) 메커니즘이 등장했습니다. 어텐션 메커니즘은 Neural Machine Translation by Jointly Learning to Align and Translate에서 최초로 제안되었습니다. 참고로 이 논문에서 명시적으로 attention mechanism이라는 표현이 사용되지는 않는데, 여기서 제안된 개념을 일반적으로 최초의 어텐션 메커니즘이라고 생각합니다. 어텐션 메커니즘은 시퀀스를 하나의 고정된 길이의 벡터에 매핑하는 것이 아니라, 시퀀스의 각 토큰이 자기 자신에 대한 정보를 갖도록 합니다.
이를 논문에서는 다음과 같은 그림으로 표현합니다. 아래 그림은 디코더에서 발생하는 상황인데, 출력 문장에서 t번째 단어를 생성할 때, 입력 문장의 모든 단어 벡터가 갖는 정보, 현재까지 생성된 단어들에 대한 정보를 바탕으로 한다는 것입니다.
예를 들어, “the cat sat on the mat”라는 문장이 있다면, 각 단어는 문장 내의 다른 단어들과의 관계를 잘 표현하는 벡터를 갖습니다. 논문에서는 이 벡터를 인코더 은닉 상태(encoder hidden state)라고 하고, 디코더의 은닉 상태와 구분하기 위하여 annotation이라는 표현을 사용합니다. 이 벡터는 단어 자체의 벡터, 즉 단어 임베딩(word embedding)과는 구분됩니다. 즉, 각 단어는 문맥과 관계없이 내재적인 의미를 표현하는 단어 벡터와 주어진 문장 내에서 다른 단어와의 관계를 표현하는 annotation 벡터를 갖습니다.
여기서 “sat”이라는 단어에 주목하여 annotation 벡터가 어떻게 만들어지는지를 보겠습니다. 최초의 어텐션 메커니즘은 양방향 LSTM을 사용하였습니다. 일반적인 RNN은 순방향 모델입니다. 즉, 시퀀스를 순서대로 읽습니다. 양방향 LSTM은 순방향과 역방향을 모두 사용하는 LSTM인데, 역방향 LSTM은 시퀀스를 마지막 단어부터 거꾸로 읽습니다. 따라서 “sat”을 기준으로 순방향 LSTM은 첫 단어인 “The”부터 단어를 읽어나가 “sat”까지의 정보가 담긴 벡터 →hsat를 만듭니다. 그림에서는 편의상 첨자로 단어의 인덱스를 사용하였습니다. 마찬가지로 역방향 LSTM은 마지막 단어인 “mat”부터 단어를 읽어 “sat”까지의 정보가 담긴 벡터 ←hsat를 만듭니다. 최총적인 annotation 벡터는 이 두 벡터를 연결(concatenate)하여 사용합니다.
이처럼 문장 전체에 대한 정보를 하나의 고정된 길이의 벡터에 억지로 압축하는 게 아니라, 각 단어가 자신만의 정보를 갖게 하는 방식을 통해 RNN의 장기 의존성 문제(Long term dependency)와 정보 병목 현상을 해소할 수 있었습니다. 그런데 이 전통적인 어텐션 메커니즘도 여전히 RNN을 기반으로 한다는 문제가 있습니다.
트랜스포머의 어텐션 메커니즘
반면 트랜스포머는 RNN과 CNN을 전혀 사용하지 않고 오로지 어텐션 메커니즘만을 사용하여 단어 간의 관계를 표현합니다. 특히 논문의 Introduction에 global dependency라는 표현이 쓰였는데, RNN을 전혀 사용하지 않기 때문에 장기 의존성의 제약에서 자유로워지게 됩니다.
기존의 어텐션 메커니즘의 함수는 RNN을 통해 만든 벡터를 매개변수로 하였습니다. 트랜스포머는 RNN을 전혀 사용하지 않았기 때문에, 다른 어텐션 함수를 사용합니다. 특별히 트랜스포머에서 사용된 어텐션의 종류를 셀프 어텐션(self attention) 또는 intra-attention이라고 하는데, 이는 문장 내의 서로 다른 위치에 있는 토큰 간의 관계를 학습하는 메커니즘입니다.
논문에서는 셀프 어텐션을 조금 변형한 스케일드 점곱 어텐션(Scaled Dot-Product Attention)을 사용하며, 다음과 같이 공식화하였습니다.
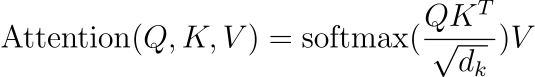
이 함수는 Q, K, V를 입력으로 받아 어텐션 점수(attention score)를 계산합니다. Q, K, V는 각각 쿼리(Query), 키(Key), 값(Value)라고 하는데 각각에 대한 개념은 조금 이따가 알아보겠습니다. 실제로 어텐션 점수가 어떻게 계산되는지 우변을 먼저 보겠습니다.
우선 Query와 Key의 내적을 계산합니다. 벡터의 내적은 유사도를 의미합니다. 결국 각 Query와 Key의 유사도를 계산한다는 것입니다. 그 후 scaling factor로 나누어줍니다. Scaling factor의 의미에 대해서는 Attention Is All You Need 논문 리뷰에서 자세히 다루었으니 그곳을 참고해주세요. 그 다음에 소프트맥스를 취하여, 앞에서 계산한 값을 정규화합니다. 그리고 최종적으로 이 값에 Value를 곱합니다.
수식 자체는 어렵지 않지만, 과연 Query, Key, Value 각각이 무엇을 의미하는지는 직관적으로 알기 어렵습니다. 앞에서 언급한 기존의 어텐션 메커니즘과 비교하면 왜 세 개의 벡터가 사용되는지가 의아합니다. 예를 들어 문장 내의 어떤 단어와, 같은 문장에서 다른 단어들과의 유사도를 통해 단어의 의미를 파악한다면 Query와 Key만 있어도 가능할 것 같입니다. (Key 대신 Value가 될 수도 있을 것입니다.) 트랜스포머의 Query, Key, Value는 이 논문에서 새롭게 제안된 개념인 데 반해, 각각의 의미가 명확하게 설명되어 있지는 않은데, 이에 대해서 자세히 알아보겠습니다.
Query, Key, Value?
먼저 각각을 정의해보겠습니다. Query는 직역하면 질문입니다. 즉 query는 어떤 단어에 대해 이해하기 위해서는 문장 내에 어떤 단어들에 주목해야 하는지를 묻습니다. key는 질문에 답하기 위해 각 단어에 어느 정도 주목해야 하는지를 답합니다. Value는 query-key 쌍을 통해 질문에 대해 적절히 답변할 수 있는 단어를 찾았을 때, 실제로 관련된 정보를 제공합니다. 다시 말하면, query가 현재 선택된 단어를 이해하기 위해서는 문장 내에서 어떤 단어에 주목해야 하는지를 묻습니다. 그러면 key가 각각의 단어를 대표하여 자기 자신이 선택된 단어를 이해하기 위해서 얼마나 중요한 역할을 하는지를 답합니다. 마지막으로 value는 실제로 둘의 관계를 이해하기 위한 정보를 제공합니다.
각각의 역할은 어느 정도 알겠으니, 어떻게 만들어졌는지를 짚고 넘어가겠습니다. 트랜스포머 아키텍처에서 단어 벡터 X와, Query(Q), Key(K), Value(V)는 모두 임의로 초기화된 후, 학습을 통해 값이 갱신됩니다. 참고로 트랜스포머의 임베딩 또한 word2vec이나 GloVe와 같은 정적 임베딩 대신 선형 레이어를 사용하여 학습됩니다.
엄밀히 말하면, 위의 설명은 틀렸습니다. Query, key, value는 각 단어에 대응하는데, 모든 단어에 대한 query, key, value를 전부 학습하는 것은 효율적이지 않습니다. 그래서 실제로는 단어 벡터 X와 함께, query, key, value의 가중치 WQ, WK, WV가 학습됩니다. 그러면 각 단어에 대한 query, key, value는 단어 벡터에 각각을 곱하여 Q=XWQ, K=XWK, V=XWV로 나타납니다.
앞의 설명에서는 query, key, value의 개념을 정의하고 각각의 역할을 알아봤는데, 알고보니 각 벡터는 각각에 대응하는 가중치 행렬에 의존한다는 것을 알게 되었습니다. 특히 이 가중치는 모든 단어에 대해서 공유되기 때문에 각 단어에 대해서 특별한 무언가를 의미한다고 생각할 수 없습니다. 그렇다면 이 가중치는 무엇을 학습할까요?
먼저 query의 가중치 행렬 WQ는 잘 질문하는 방법을 학습합니다. 즉, 선택한 단어를 잘 이해하기 위해서는 어떤 단어에 주목해야 하는지에 대한 질문을 구성하는 역할을 합니다. 같은 맥락에서 WK는 잘 대답하는 방법을 학습합니다. 어떤 단어와 관계가 있냐는 질문을 받았을 때, 실제로 자신이 그렇다는 것을 답변하는 방법을 익혀야 합니다. 마지막으로 WV는 query와 key 사이의 관계를 잘 표현하는 방법을 학습합니다. Query와 key 벡터의 유사도를 계산하여 그들이 연관되었다는 사실은 알았는데, 실제로 어떤 근거에서 관련이 있는지를 표현하는 방법이 필요할 것입니다.
Query, Key, Value의 비유
앞서 설명한 여섯 가지 개념을 조금 더 쉽게 이해하기 위해 비유를 들어보겠습니다. 먼저 여러분이 어떤 게임에 참여한 상황을 예로 들겠습니다. 게임 참가자들은 같은 방에 모여 있으며, 옷에는 이름표가 붙어 있습니다. 각각 어떤 전문적인 지식에 대한 질문을 담은 종이와 함께 또 다른 질문에 대한 답변을 갖고 있습니다. 여러분은 다른 참가자들의 도움을 받아 정답을 찾아야 합니다.
여기서 방은 같은 시퀀스 또는 문장을, 각 참가자는 문쟁 내의 토큰 또는 단어를 의미할 것입니다. 그리고 이름표는 key에 해당하고, 갖고 있는 정보는 value에 해당합니다. 여러분은 정답을 찾아야 할 질문도 가지고 있는데, 이는 query에 해당합니다.
반면에 여러분이 이 게임의 호스트이며, 각 참가자가 게임을 잘 진행할 수 있도록 설계를 한다고 생각해보겠습니다. 여기서 여러분은 모델 또는 시스템을 나타내고, 게임은 모델이 해결해야 하는 태스크입니다. 먼저 여러분은 참가자가 게임에 원활하게 참여할 수 있게 질문을 잘 구성하는 방법을 안내해야 할 것입니다. 또한, 각 참가자에게 배부한 이름표는 그들이 가진 정보에 대한 힌트를 가지고 있어야 합니다. 그리고 실제로 각 참가자가 가진 정보는 질문에 대한 답을 적절히 포함하고 있어야 합니다. 앞에서 연달아 언급한 개념이 바로 각 가중치 행렬 WQ, WK, WV에 해당합니다.
이처럼 query, key, value 각각의 역할을 정의하면 어텐션 메커니즘에 세 가지 종류의 벡터가 사용된 이유를 이해할 수 있고, 트랜스포머의 어텐션 메커니즘이 어떤 기능을 하는지를 잘 이해할 수 있습니다. 논문의 수식은 어렵지 않은 편이지만, 이를 구성하는 각각의 요소에 대해서는 더 깊은 탐구가 필요한데, 나름의 정의와 비유를 통해 설명해보았습니다. 물론 query, key, value의 개념을 한 번에 이해하기가 정말 쉽지 않고, 이를 설명한 다양한 글에서도 정말 한 번에 이해하기 쉽다라는 느낌이 든 적은 거의 없었던 것 같습니다. 아마 본문의 비유 또한 그럴 수도 있는데, 조금 더 명확한 이해를 위해서 여러 사람들의 해석과 설명을 차근차근 읽다보면 도움이 많이 될 것 같습니다.
'ML, DL Basic' 카테고리의 다른 글
| GPT 이해하기, GPT-2까지 (0) | 2023.11.07 |
|---|---|
| 딥러닝 논문을 읽는 방법 (0) | 2023.11.03 |
| Hierarchical Softmax 자세히 알아보기 (0) | 2023.10.20 |
| 딥러닝의 역사 알아보기 (2) | 2023.10.18 |
| 다양한 성능 평가 지표와 F1 점수 (1) | 2023.10.12 |




댓글