BLEU 점수는 무엇일까?
BLEU Score는 기계번역 태스크에서 참조 문장과 기계가 생성한 번역문을 비교하여 번역의 품질을 평가하는데 주로 사용되는 지표로 흔히 알려져 있습니다. 좀 더 일반적으로는 생성된 텍스트를 평가하는데 널리 사용되는 지표 중 하나입니다. 번역, 요약, 질의응답 등 특정 태스크에 국한되지 않고 인공지능 모델이 생성한 텍스트를 평가하는 방식이라고 생각하면 될 것 같습니다.
BLEU 의 등장
BLEU는 BiLingual Evaluation Understudy의 줄임말입니다. 각 단어를 직역하면 '이중 언어 평가 대역' 입니다. 2002년에 BLEU를 제안한 논문(BLEU: a Method for Automatic Evaluation of Machine Translation) 초록의 마지막 줄에는 다음과 같은 문장이 쓰여 있습니다.
We present this method as an automated understudy to skilled human judges, which substitutes for them when there is a need for quick or frequent evaluations.
의미는 결국 숙련된 인간 평가자를 대체할 수 있는 평가 방식을 제안한다는 내용입니다. BLEU 지표의 이름과 제안된 논문을 보면 원래는 기계 번역 품질을 평가하기 위한 지표라는 것을 알 수 있습니다.
BLEU 점수를 계산하는 방법
BLEU 점수는 정밀도를 기반으로 하지만, 단순히 정밀도 공식을 그대로 사용하지는 않습니다. 예를 들어서 아래와 같은 참조 텍스트와 생성 텍스트가 있다고 가정하고 정밀도를 계산해보겠습니다. 참조 텍스트는 데이터셋의 정답(label)을 의미하고, 생성 텍스트는 인공지능 모델이 번역 작업을 거쳐 생성한 텍스트를 의미합니다. 여기서 정밀도는 생성 텍스트의 각 단어에 대해서 계산한다고 생각하겠습니다.
참조 텍스트 the cat is on the mat
생성 텍스트 the the the the the the

정밀도 공식을 그냥 적용하면 값이 1이 됩니다. 이렇게 참조 텍스트에 있는 단어 중 하나가 계속해서 반복되기만 해도 번역 점수가 만점이 나와버리는 문제가 있기 때문에, 정밀도 공식을 조금 변형해서 사용합니다. 두 번째 수식과 같이 참조 텍스트에 등장하는 횟수만큼만 카운트하고 정밀도를 계산합니다. 그러면 정밀도가 2/6로 계산됩니다.
이 개념을 확장하여, 단어 하나가 아니라 n-그램에 대해서도 확인할 수 있습니다. 아래는 n-그램에 대해 확장한 수식입니다. snt는 생성 텍스트이며 snt′ 참조 텍스트입니다. clip은 앞에서 언급했듯이 n-그램의 등장 횟수를 참조 텍스트에서 등장한 횟수만큼만 카운트한다는 의미입니다.
이제 이 식을 말뭉치 C에 있는 모든 문장에 대해서 확장하면 아래와 같은 모습이 됩니다.
식이 복잡해 보이지만, 핵심은 변형된 정밀도 공식을 사용하여 단어별로 참조 텍스트에서의 등장 여부를 확인한다는 것입니다. 이를 한 번 확장하여, 단어가 아닌 n개의 연속된 단어(또는 토큰)에 대한 계산 공식을 만든 것입니다. 그리고 한 번 더 확장하여, 이를 학습 데이터에 있는 모든 문장에 대하여 계산하겠다는 의미입니다.
정밀도만 고려할 경우 발생하는 문제
그런데 이 공식에서는 정밀도만을 고려할 뿐, 재현율은 고려하지 않기 때문에 발생하는 한 가지 문제가 있습니다. 짧지만 정밀하게 생성된 시퀀스가 긴 문장보다 유리하다는 문제입니다. "짧지만 정밀한 시퀀스"가 어떤 의미인지 예시를 통해 알아보겠습니다.
참조 텍스트 the cat is on the mat
생성 텍스트 cat
위 예시에서 생성 텍스트의 정밀도를 계산하면 그 결과는 1입니다. 생성 텍스트의 유일한 단어인 cat이 참조 텍스트에도 등장하기 때문입니다. 이 예시와 같이 정밀도만을 고려하게 되면 이런 문제가 발생합니다. 그래서 도입한 것이 브레비티 페널티(Brevity Penalty, BP)입니다. BP는 다음과 같이 계산하는데, 식만 봐서는 값이 어떻게 변하는지를 알기 어렵습니다.
아래는 생성된 텍스트(candidate, c)와 참조 텍스트(reference, r)에 대하여 r과 c 값의 변화에 따라, BP의 변화를 확인할 수 있는 파이썬 코드입니다. 만약 numpy, matplotlib, ipywidgets 라이브러리가 설치되어있지 않을 경우 첫 줄을 먼저 실행하시면 됩니다.
!pip install numpy matplotlib ipywidgets import numpy as np import matplotlib.pyplot as plt from ipywidgets import interactive def brevity_penalty(c, r): BP = 1 if c > r else np.exp(1 - r / c) c_values = np.linspace(0.1, 2 * max(c, r), 400) BP_values = np.where(c_values > r, 1, np.exp(1 - r / c_values)) plt.figure(figsize=(10, 6), dpi=100) plt.plot(c_values, BP_values, label='Brevity Penalty curve', color='blue') plt.axhline(y=1, color='gray', linestyle='--', lw=0.5) plt.axvline(x=r, color='red', linestyle='--', label=f'Reference Length (r) = {r}') plt.axvline(x=c, color='green', linestyle='--', label=f'Candidate Length (c) = {c}') plt.scatter(c, BP, color='black', s=70, zorder=5) plt.xlabel('Candidate Length') plt.ylabel('Brevity Penalty (BP)') plt.title('Brevity Penalty as function of Candidate Length') plt.legend() plt.grid(True) plt.ylim([0, 1.1]) plt.show() interactive_plot = interactive(brevity_penalty, c=(1, 100), r=(1, 100)) output = interactive_plot.children[-1] interactive_plot
코드를 실행하면 아래와 같이 c와 r 값을 바꾸면서 그 결과를 확인할 수 있는 interactive plot이 생성됩니다. r의 값은 고정한 채로 c의 값이 변할 때, 생성 텍스트의 길이(c)가 작을 수록 BP의 값도 작아지는 것을 확인할 수 있습니다. 반면에 생성 텍스트의 길이가 참조 텍스트의 길이와 같거나 더 길면, BP의 값은 1로 고정됩니다. 곧 확인하겠지만, BP는 위에서 계산한 정밀도에 곱할 값이기 때문에 그 값이 작을 경우 최종적인 BLEU 점수가 낮아지게 됩니다.
재현율을 고려하지 않는 이유
짧지만 정밀한 시퀀스가 무엇인지, 왜 생성 텍스트의 길이까지 고려해야 하는지를 확인해보았습니다. 그러면 왜 재현율을 도입하지 않을까요? 여러 개의 참조 문장이 있을 경우, 즉 정답이 여러 개일 경우, 여러 개의 문장에 있는 단어를 모두 사용하는 번역에 높은 점수가 부여될 수 있기 때문입니다. 글로만 봐서는 이해하기 어려우니, 이번에도 예시로 이해해보겠습니다.
원문 Good Morning
참조 텍스트
1. 안녕하세요!
2. 좋은 아침이에요!
3. 아침이 밝았어요!
생성 텍스트
안녕하세요! 좋은 아침이 밝았어요!
그리 좋은 예시는 아닐 수 있지만, 일단은 이어서 설명하겠습니다. Good Morning이라는 문장을 번역해야 하고, 위와 같이 세 가지 번역이 가능하다고 가정하겠습니다. 그런데 만약 모델이 예시처럼 "안녕하세요! 좋은 아침이 밝았어요!"라는 텍스트를 생성했다고 하겠습니다. 이 경우 어떤 정답과도 일치하지 않고, 의미를 보았을 때도 어딘가 어색합니다. 그런데 재현율을 고려할 경우, 여러 참조 텍스트에 있는 단어를 무작정 많이 사용하기만 했는데도 점수가 높아지게 됩니다. 그래서 재현율을 고려하는 F1 점수 등을 사용하지 않는 것입니다.
BLEU 점수의 한계
앞에서 고려한 모든 내용을 다 합치면 식이 다음과 같이 완성됩니다.
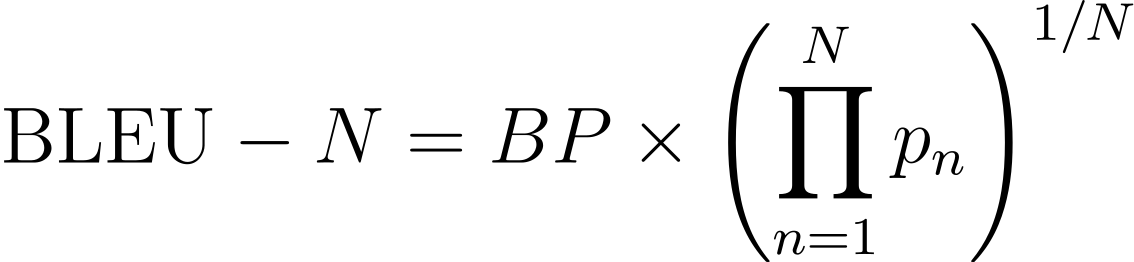
그런데 BLEU 점수에는 많은 문제가 있습니다. 아래 내용은 Rachael Tatman님의 블로그 포스트를 한글로 옮긴 것입니다. 원문에서는 BLEU가 어떻게 고안되었는지를 예시와 함께 매우 구체적으로 설명합니다. 그리고 덧붙여 BLEU의 네 가지 한계를 지적합니다. 하나씩 알아보겠습니다.
첫 번째는 의미를 고려하지 않는다는 것입니다.
참조 텍스트
I ate the apple.
생성 텍스트
1. I consumed the apple.
2. I ate an apple.
3. I ate the potato.
예시를 보면 첫 번째와 두 번째 문장은 완벽하진 않지만, 의미적으로 큰 문제는 없습니다. 반면 세 번째 문장은 완전히 다른 의미를 갖는데, BLEU 점수를 계산하면 모두 같은 점수를 받습니다. 이렇게 BLEU 점수는 정밀도를 기반으로 하기 때문에 문장의 의미는 고려하지 않는다는 문제가 있습니다.
두 번째는 문장 구조를 고려하지 않는다는 문제입니다.
참조 텍스트
1. Orejuela appeared calm as he was led to the American plane which will take him to Miami, Florida.
2. Orejuela appeared calm while being escorted to the plane that would take him to Miami, Florida.
3. Orejuela appeared calm as he was being led to the American plane that was to carry him to Miami in Florida.
4. Orejuela seemed quite calm as he was being led to the American plane that would take him to Miami in Florida.
생성 텍스트
1. Appeared calm when he was taken to the American plane, which will to Miami, Florida.
2. which will he was, when taken appeared calm to the American plane to Miami, Florida.
네 개의 참조 번역이 있고 아래와 같이 두 가지 번역이 생성되었다고 가정합니다. 첫 번째 번역도 사실 완벽하진 않습니다. 이름도 누락되었고, will 뒤에 와야 할 동사도 없습니다. 그러나 어느 정도 의미는 통합니다. 반면에 두 번째 번역은 문장 자체가 너무 뒤죽박죽이라 의미조차 알기가 어렵습니다. 그런데 실제로 BLEU 점수를 계산해보면 같은 점수를 받습니다.
세 번째는 형태학적으로 풍부한 언어를 잘 처리하지 못한다는 것입니다.
글에서 쓴 예시는 페루에서 사용되는 시피보어라고 합니다.
영어
Her village is large.
페루의 시피보어
Jawen jemara ani iki.
Jawen jemaronki ani iki.
시피보어 번역에서 jemar로 시작하는 단어의 어미를 확인해보면 조금씩 다른 것을 확인할 수 있습니다. 이는 화자가 발화에 얼마나 확신이 있는지에 따라 다르게 사용한다고 합니다. 위 문장은 실제로 가본 적이 있을 때, 그리고 아래 문장은 다른 사람에게서 들었을 때 사용한다고 합니다. 의미만을 두고 보면 원문의 의미를 둘 다 완벽하게 전달하는데, 두 단어가 형태학적으로 공존할 수 없기 때문에 참조 번역과 다른 하나는 BLEU 점수에서 손해를 보게 됩니다.
마지막은 BLEU 점수가 사람의 판단과는 잘 맞지 않는다고 합니다. 원문에서는 심지어 단순히 F1 점수를 계산한 게 오히려 Human Evaluation과 더 큰 상관관계를 보이기도 한다고 합니다. 이렇듯 BLEU 점수는 여전히 몇 가지 한계와 문제점을 갖습니다.
그래서 Rachael Tatman님은 글을 마무리하면서 BLEU 점수는 널리 사용하는 지표지만, 텍스트를 평가하는 데 있어 BLEU 점수가 갖는 한계를 이해하고 사용하는 것이 중요하다고 하였습니다. 실제로 데이터를 평가하는 지표를 사용할 때, 각 지표가 갖는 특징과 장단점을 이해하고, 자신의 데이터와 태스크를 정확하게 평가할 수 있는 새로운 지표를 개발하는 것도 매우 중요합니다.
Python 코드로 BLEU 점수를 계산하는 방법
# 이전 코드 from datasets import load_metric bleu_metric = load_metric("sacrebleu") # 바뀐 코드 from evaluate import load bleu_metric_new = load("sacrebleu")
코드를 실행하기 위해서는 datasets, evaluate 라이브러리를 설치해야 합니다. 처음 두 줄의 코드는 기존에 사용하던 지표를 불러오는 방식입니다. 현재는 해당 코드를 실행할 경우, 에러가 발생하진 않지만 deprecation warning이 발생합니다. 이를 해결하기 위해서는 아래 코드를 실행하면 경고가 출력되지 않습니다. 참고로 여기서는 BLEU 대신 sacreBLEU를 사용하는데 BLEU 점수를 계산하기 전, 토큰화가 별도로 수행되어야 하는 문제점을 갖고 있는데, 이러한 문제점을 해결한 것이 바로 sacreBLEU입니다. (TMI로, sacreBLEU는 프랑스어로 짜증나는 상황에 사용하는 비속어라고 합니다.)
토큰화를 내재화한 sacreBLEU
BLEU가 제안된 논문에는 토큰화에 대한 내용이 없습니다. 논문에서는 n-그램 정밀도를 기반으로 기계번역의 품질 측정을 자동화하는 지표를 개발하는 데 중점을 두었습니다. 추측이지만, 아마 당시에는 토큰화에 대한 개념은 존재하였으나, 일반적인 토큰화 기법이 정립되지 않았기 때문이라고 생각합니다. 현재 널리 사용하는 BPE는 2015년, sentencepiece는 2018년에 발표되었습니다. 더불어 기계번역의 종류에는 현재 일반적으로 사용되는 신경망 기계 번역(Neural Machine Translation, NMT)외에도 통계기반 기계 번역(Statistical Machine Translation, SMT)이 있습니다. 논문이 발표된 시기가 2002년임을 고려하면 당시의 기계 번역은 SMT가 더 일반적이었을 것이라고 생각됩니다. 이러한 점을 고려해보았을 때, 논문에서 왜 토큰화를 고려하지 않았는지를 알 수 있을 것 같습니다.
결국 BLEU 점수는, 토큰화를 전제로 하지 않았기 때문에 현재와 같이 신경망 기계번역 결과를 평가하기 위해서는 사용자가 직접 토큰화를 수행해야 합니다. 문제는 사용자가 어떤 토크나이저를 사용하느냐에 따라서 BLEU 점수가 크게 달라진다는 것입니다. BLEU 점수를 계산하는 방법 자체도 고정된 게 아니라, 몇 가지 파라미터에 의해서 튜닝이 가능합니다. 대표적으로는 n-그램의 n입니다. 일반적으로는 4를 사용하지만, 다른 숫자도 얼마든지 가능하긴 합니다. 다음에 살펴볼 smooth value도 하나의 예시입니다. 이렇듯 BLEU 점수는 파라미터에 따라 달라질 수 있습니다. 그래서 sacreBLEU 논문에서는 parameterized methods라는 표현을 사용합니다. sacreBLEU가 제안된 논문(A Call for Clarity in Reporting BLEU Scores)에는 BLEU 점수의 문제점과 그 이유를 구체적인 예시와 통계를 근거로 설명합니다. 아래는 저자가 토큰화 기법에 따라 BLEU 점수가 얼마나 달라질 수 있는지를 정리한 표입니다.
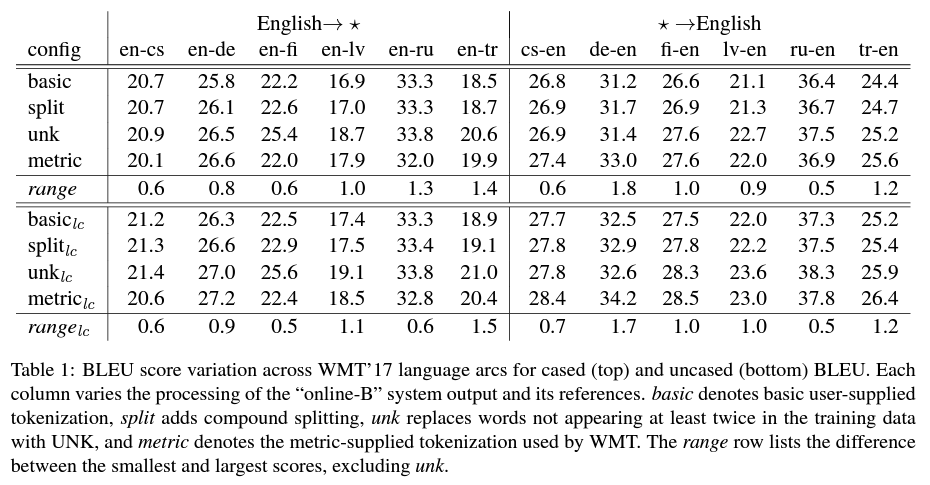
파라미터를 튜닝한 방식, 토크나이저가 unknown 토큰을 처리하는 방식에 따라 BLEU 점수가 크게 부풀려질 수도 있다고 지적합니다. 이러한 이유로 서로 다른 실험의 BLEU 점수를 비교하는 게 공정하지 않다고 지적하며, sacreBLEU는 토크나이저의 표준을 정해두어 계산된 BLEU 점수에 더욱 신뢰성을 가질 수 있게 합니다.
돌아와서
다시 이어서 파이썬 코드로 BLEU 점수를 계산하는 방법을 알아보겠습니다.
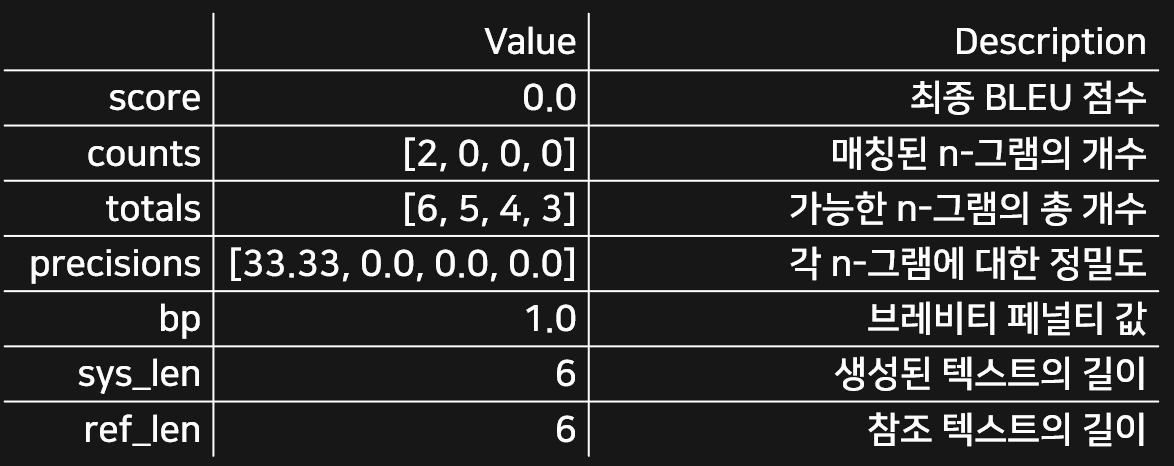
descriptions = { "score": "최종 BLEU 점수", "counts": "매칭된 n-그램의 개수", "totals": "가능한 n-그램의 총 개수", "precisions": "각 n-그램에 대한 정밀도", "bp": "브레비티 페널티 값", "sys_len": "생성된 텍스트의 길이", "ref_len": "참조 텍스트의 길이" } bleu_metric.add( prediction="the the the the the the", reference=["the cat is on the mat"]) results = bleu_metric.compute(smooth_method="floor", smooth_value=0) results["precisions"] = [np.round(p, 2) for p in results["precisions"]] df = pd.DataFrame.from_dict(results, orient="index", columns=["Value"]) df["Description"] = df.index.map(descriptions) # Map keys to descriptions df
코드를 실행하면 다음과 같은 데이터프레임이 출력됩니다. 리스트로 된 값은 n-그램의 n을 1부터 4까지 각각 계산한 결과입니다. 코드에서 BLEU 점수를 계산할 때 smooth_value라는 파라미터가 있습니다. 여기서는 코드 계산 결과와 위에서 설명한 공식의 결과가 같도록 일부러 이 값을 0으로 하였습니다.
smooth_value란?
smooth value는 최종 점수가 0점이 되지 않도록 보정하는 값입니다. 기하평균을 계산할 때, 특정 n-그램 정밀도가 0일 경우 최종적으로 BLEU 점수가 0점이 되어버리는 문제를 해결하기 위하여 추가합니다. 계산하는 방법은 단순합니다. 아래와 같이 정밀도 공식에서 분자에 smooth value를 더해주기만 하면 됩니다.
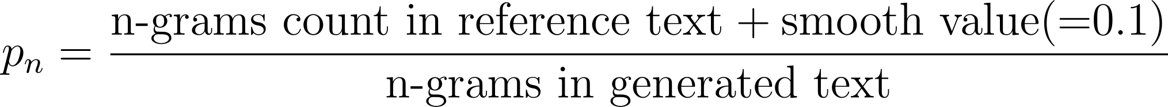
그러면 smooth value가 0.1일 때 결과가 어떻게 되는지 코드를 통해 확인해보겠습니다. 위 코드에서 results를 계산하는 줄만 아래와 같이 바꿔주면 됩니다.
results = bleu_metric.compute(smooth_method="floor")
그러면 다음과 같은 데이터프레임이 출력되는데, 여기서 bigram(2-그램) 정밀도를 확인해보면 2.0이라는 값이 나옵니다.
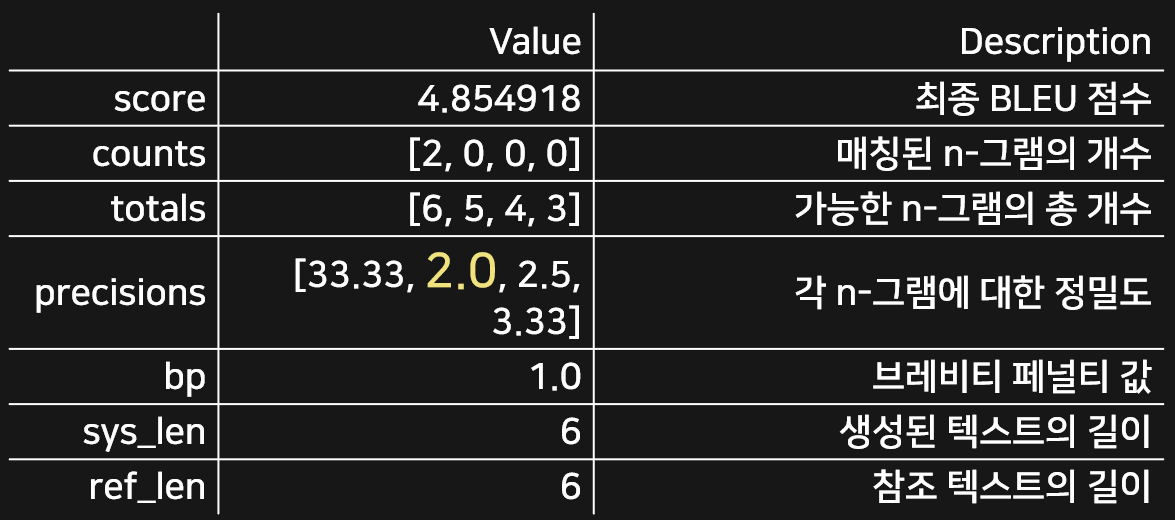
위의 식과 함께 생각해보면, 5개의 bigram에 대해서 겹치는 게 하나도 없기 때문에 0.1을 5로 나누어준 값인 0.02가 정밀도로 계산됨을 알 수 있습니다. 따라서 위와 같이 2.0이라는 값이 출력된 것입니다.
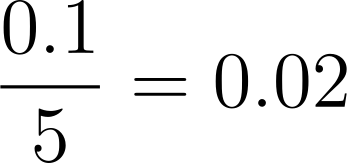
마무리
앞서 BLEU 점수가 등장한 배경과 BLEU 점수가 갖는 한계, 그리고 파이썬 코드로 BLEU 점수를 직접 계산하는 방법에 대해서 다루어보았습니다. 내용에 오류가 있거나 잘못된 사실이 있다면 댓글로 지적해주시면 감사하겠습니다!
'ML, DL Basic' 카테고리의 다른 글
| 딥러닝 논문을 읽는 방법 (0) | 2023.11.03 |
|---|---|
| Attention과 Query, Key, Value (1) | 2023.10.26 |
| Hierarchical Softmax 자세히 알아보기 (0) | 2023.10.20 |
| 딥러닝의 역사 알아보기 (2) | 2023.10.18 |
| 다양한 성능 평가 지표와 F1 점수 (1) | 2023.10.12 |




댓글