
FastText를 제안한 논문으로 알려진 Enriching Word Vectors with Subword Information를 리뷰해보았습니다. 이 논문의 저자 중 한 명은 word2vec의 저자인 Tomas Mikolov인데, 여러 논문을 읽을수록 단어 임베딩과 관련해서 정말 많은 연구를 하신 분이라는 생각이 듭니다. FastText도 word2vec의 확장으로 기본적으로 사용된 알고리즘은 같습니다. 이 논문에서도 skipgram을 사용하지만 subword information을 학습하여 더 풍분한 단어 벡터를 학습하는 기법을 제안합니다. 자세한 내용은 본문에서 소개하겠습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Overview
단어에 대한 연속적인 표현을 학습하는 방법은 NLP에서 오랫동안 연구되어 온 주제입니다. 1990년대에는 레이블이 없는 말뭉치에서 동시발생 행렬(co-occurrence matrix)의 통계를 사용하여 벡터를 생성하였습니다. 2010년대에 들어서는 신경망을 사용하여 주변 단어를 바탕으로 기준 단어를 예측하는 기법을 통해 벡터를 학습하였습니다.
하지만 기존의 방법은 대부분 단어간의 가중치가 공유되지 않고, 각 단어에 하나의 벡터를 할당하였습니다. 이런 방법은 단어의 내부 구조를 무시하기 때문에 형태학적으로 풍부한 단어를 가진 언어를 학습하는 데는 한계가 있습니다. 예를 들어 프랑스어나 스페인어는 대부분의 동사에 40개 이상의 변형된 형태가 있고, 핀란드어는 명사마다 15개의 변형된 형태가 있습니다. 이런 언어들은 말뭉치에는 흔히 나타나지 않는 형태의 단어를 많이 포함하기 때문에 모델이 학습하기가 매우 어렵습니다. 대부분의 경우 단어 형성은 특정한 규칙을 따릅니다. 따라서 문자 수준의 정보를 활용하여 형태학적으로 풍부한 단어에 대한 벡터 표현을 개선할 수 있습니다.
논문에서는 chracter n-grams를 사용한 단어 표현을 제안하여, 단어를 n-gram 벡터의 합으로 표현합니다. 이는 기존의 CBOW 모델을 확장한 것으로, 부분단어 정보(subword information)를 활용한 것입니다. 저자는 9개의 서로 다른 형태학적인 특징을 갖는 언어를 비교하여 이 기법의 유용성을 평가하였습니다.
2. Related Work
Morphological word representations
당시 단어 표현에 형태소 정보를 통합하려는 여러 가지 방법이 제안되었습니다. 희귀 단어를 더 잘 모델링하기 위해서 Alexandrescu는 단어를 특성의 집합으로 표현하는 factored neural network model을 도입하였습니다. 이 특성은 형태소 정보를 잘 학습할 수 있는데, 튀르키예어처럼 형태학적으로 풍부한 언어에 잘 적용되었습니다. 그 이후에는 형태소로부터 단어 표현을 도출하는 여러 구성 함수(composition function)가 제안되었습니다. 이런 방법은 논문과는 다르게 형태소 분해에 의존합니다.
특잇값 분해(SVD)를 통해 character four-gram을 사용하여 단어 표현을 학습하는 연구도 수행되었습니다. 또한 chracter n-gram count vectors를 통해 단어 표현을 생성하는 방법도 제안되었습니다. 하지만 이 연구에서 사용된 목적 함수는 paraphrase pair에 의존하지만, 논문의 연구는 어떤 데이터에도 적용될 수 있습니다.
Character level features of NLP
문자 수준 모델(chracter-level model)은 단어 단위로 시퀀스를 분할하는 대신 문자에서 언어 정보를 직접 학습합니다. 이런 모델은 RNN을 사용하여 언어 모델링, text normalization, 형태소 태깅과 같은 작업에 적용되었습니다. 또한 문자를 학습한 CNN을 사용하여 형태소 태깅이나 텍스트 분류, 언어 모델링에 적용되기도 하였습니다. 기계 번역에는 subword unit을 사용하여 희귀 단어에 대한 표현을 학습하는 방법이 제안되기도 하였습니다.
3. Model
3.1 General Model
먼저 continuous skip-gram 모델에 대해서 간단히 정리하겠습니다. W 크기의 단어 사전이 주어졌을 때 각 단어를 인덱스 w∈1,…,W로 표시할 수 있습니다. 이때 각 단어 w에 대한 벡터 표현을 학습하는 것이 목표입니다. Distributional hypothesis에 의하면 단어 표현은 문맥에 나타나는 단어를 잘 예측하도록 학습됩니다. 이를 공식화하면, 단어의 시퀀스 w1,…,wT에 대한 규모가 큰 말뭉치가 주어졌을 때, skipgram 모델의 목표는 다음 로그 가능도를 최대화하는 것입니다.
수식에서 Ct는 단어 wt 주위에 있는 단어의 인덱스입니다. 단어 wt가 주어졌을 때 context word wc를 관찰할 확률은 앞에서 단어 벡터에 의해 매개변수화될 것입니다. 여기서는 (단어, 문맥) 쌍을 어떤 실수로 매핑하는 채점 함수(scoring function)가 주어졌다고 가정하겠습니다. 문맥 단어가 나타날 확률을 정의하는 한 방법은 소프트맥스를 사용하는 것입니다.
하지만 이 모델은 단어 wt가 주어졌을 때 하나의 단어 wc만 예측하게 되어 있으므로 사용하기에 부적절합니다. 문맥 단어(context words)를 예측하는 문제는 독립적인 이진 분류 태스크로 정의할 수 있습니다. 그러면 독립적으로 각 문맥 단어의 존재 유무를 예측하는 것이 목표가 됩니다. t에 위치한 단어에 대해서 모든 문맥 단어를 양성 샘플(positive examples)이라고 생각하고, 사전에서 임의로 고른 단어를 음성 샘플(negative samples)이라고 생각하겠습니다. 문맥 단어의 위치가 c일 때, binary logistic loss를 사용하여 다음과 같은 음의 로그 가능도(negative log-likelihood)를 얻을 수 있습니다.
Nt,c는 음성 샘플의 집합입니다. 로그 손실 함수 ℓ에서 x↦log(1+e−x) 라고 하면, 목표 함수를 다음과 같이 쓸 수 있습니다.
채점 함수 s와 단어 wt, 문맥 단어 wc에 대한 매개변수화를 위해서는 단어 벡터를 사용하는 것이 자연스럽습니다. 어휘 사전 내의 단어 w를 Rd차원의 두 벡터 uw와 vw로 정의합니다. 이 두 벡터는 입력(input)과 출력(output) 벡터로 불리기도 합니다. 벡터 uwt와 vwc는 각각 단어 wt와 wc에 대응합니다. 그러면 점수는 s(wt,wc)=uwt⊺과 같이 단어와 문맥 단어 벡터의 스칼라 곱으로 계산됩니다. 여기서 묘사한 음성 샘플을 사용하는 skipgram 모델은 word2vec 논문에서 사용된 것과 같습니다.
3.2 Subword Model
Skipgram 모델은 단어의 내부 구조를 무시하고, 단어마다 하나의 벡터 표현만을 사용합니다. 여기서는 단어의 내부 구조를 고려하는 새로운 채점 함수 s를 제안합니다. 각 단어 w는 bag of character n-gram으로 표현됩니다. 다른 문자 시퀀스와 접두사, 접미사를 구분할 수 있도록 단어의 앞과 뒤에 특별한 경계 기호은 <와 >를 추가합니다. 또한 n-gram 집합에 단어 w 자체도 포함하여 각 단어에 대한 표현을 학습합니다. 예를 들어 n=3 이고, 주어진 단어가 where이라면, 이는 특수 시퀀스 \text{<where}>과 함께 다음과 같은 character n-gram의 집합으로 표현됩니다.
참고로 her이라는 단어에 해당하는 시퀀스 \text{}는 where라는 단어의 tri-gram \text{her}과는 다릅니다. 실제로는 n이 3보다 크거나 갖고 6보다 작거나 같은 모든 n-gram을 추출합니다.
크기가 G인 n-gram의 사전이 주어졌다고 가정합니다. 단어 w가 주어졌을 때, \mathcal G_w \subset{1,\dots,G}를 w에 대한 n-gram의 집합이라고 하겠습니다. 벡터 \mathbf z_g는 각 n-gram g에 대한 벡터 표현입니다. 그러면 단어를 그에 대한 n-gram 벡터 표현의 합으로 나타낼 수 있습니다. 따라서 다음과 같은 채점 함수를 얻게 됩니다.
이 간단한 모델을 사용하면 단어 간 표현을 공유할 수 있으므로 희귀 단어에 대한 신뢰할 수 있는 표현을 학습할 수 있습니다.
4. Experimental Setup
4.1 Baseline
대부분의 실험에서 논문의 모델은 \texttt{word2vec} 패키지를 사용하여 C로 구현한 \texttt{skipgram}과 \texttt{cbow}와 비교하였습니다.
4.2 Optimization
최적화 문제는 앞에서 언급한 음의 로그 가능도로 나타난 함수를 확률적 경사 하강법을 통해 풀었습니다. 베이스라인의 skipgram 모델에는 linear decay of step size라는 learning rate scheduler를 사용하였습니다.
4.3 Implementation details
베이스라인을 포함한 모든 모델은 300 차원의 단어 벡터를 사용하였습니다. 각 양성 샘플마다 5개의 음성 샘플이 사용되었는데, 음성 샘플은 uni-gram frequency의 제곱근에 비례하는 분포에서 임의추출하였습니다. 컨텍스트 윈도우의 크기 c는 1부터 5중에 균일분포로 추출하여 사용하였습니다. 많이 사용되는 단어를 서브샘플링하기 위해서 rejection threshold 10^{-4}를 사용하였습니다. 어휘 사전을 구축할 때는 학습 데이터셋에서 5번 이상 나타난 단어만을 사용하였습니다. skipgram 베이스라인에 대한 step size \gamma_0은 0.05로, cbow와 논문의 모델에는 0.05가 사용되었습니다.
영어 데이터에 대해 이 세팅을 사용하면 character n-gram을 사용한 논문의 모델의 학습 시간이 skipgram 베이스라인을 학습하는 것보다 1.5배 이상 걸렸습니다.
4.4 Datasets
학습에는 Wikipedia 데이터셋이 사용되었으며, 아랍어, 체코어, 독일어, 영어, 스페인어, 프랑스어, 이탈리아어, 루마니어어와 러시아어를 사용하였습니다. 원본 데이터는 Matt Mahoney의 pre-processing perl script를 사용하여 정규화하였습니다.
5. Results
5.1 Human similarity judgement
단어 표현의 품질은 첫 번째로 단어 유사도 및 연관성 측정 태스크를 통해 평가되었습니다. Spearman’s rank correlation coefficient를 사용하여 사람의 평가와 벡터 표현 간의 코사인 유사도를 비교하였습니다. 실험 결과는 다음과 같습니다. 일부 단어는 학습 데이터셋에 나타나지 않았기 때문에 cbow나 skipgram 베이스라인과는 비교할 수 없었습니다. 따라서 이 벡터를 null 벡터로 처리하였습니다. 반면에 논문의 모델은 부분단어에 대한 정보를 사용하기 때문에 out-of-vocabulary(OOV)의 벡터를 계산할 수 있습니다. OOV 단어가 나타날 때 null 벡터로 처리하는 모델은 \texttt{sisg-}이고 그렇지 않는 모델은 \texttt{sisg} 입니다.
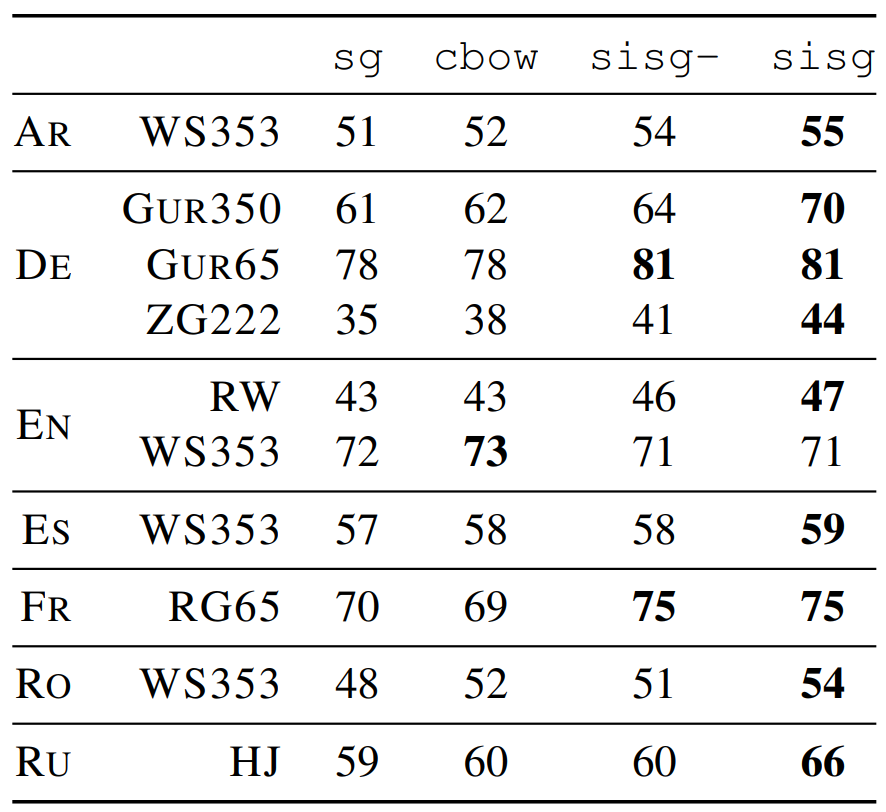
5.2 Word analogy tasks
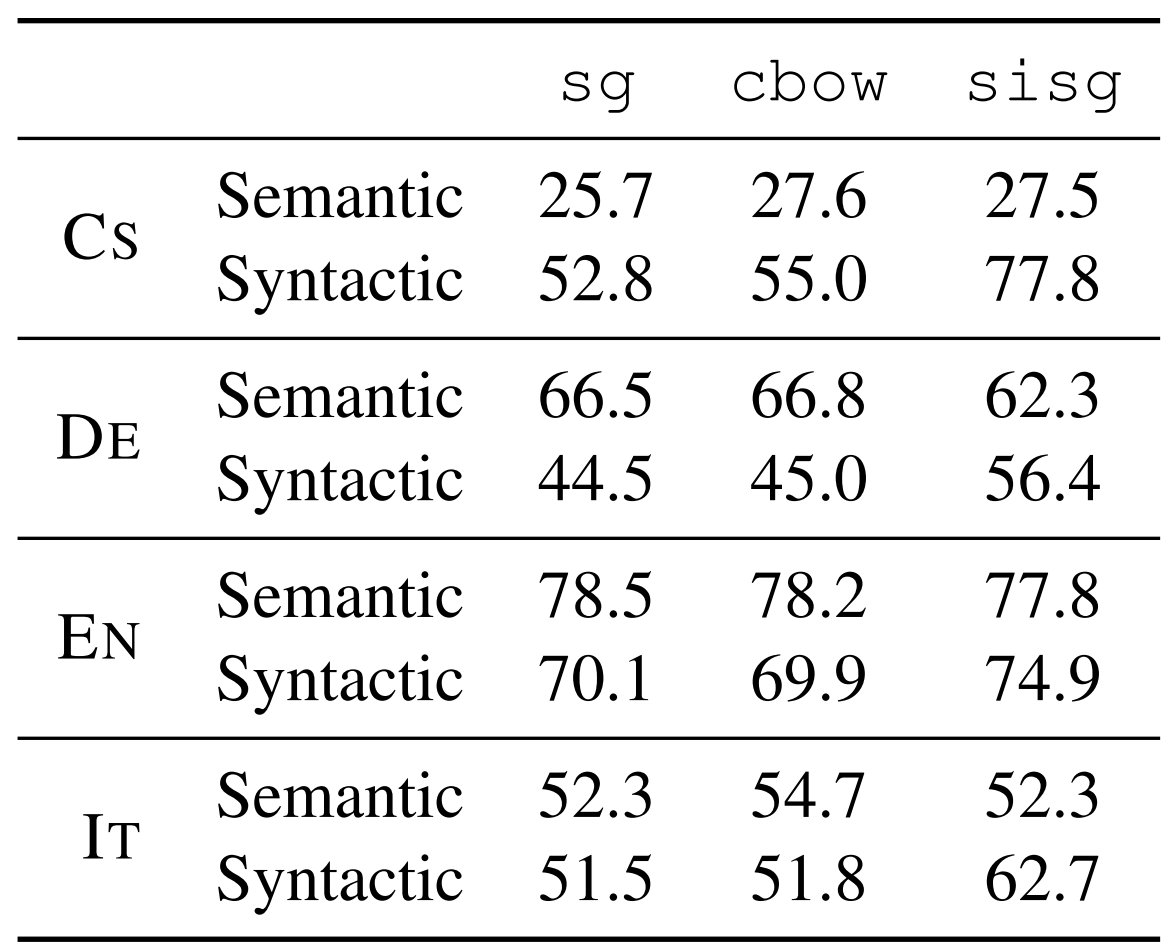
단어 유추 태스크는 A가 B일때 C가 D이다 라는 명제에서 D가 주어지지 않은 상황에서 D를 찾는 태스크입니다. 실험 결과는 다음과 같습니다. Syntactic task에서 주로 성능이 향상되었고, semantic 태스크에서는 큰 변화가 없었습니다. 이는 n-gram의 크기와 관련이 있는데 이에 대해서는 조금 뒤에서 다루겠습니다. 체코어나 독일어처럼 형태학적으로 풍부한 언어에서 특히 성능이 크게 향상된 것을 볼 수 있습니다.
5.3 Comparison with morphological representation
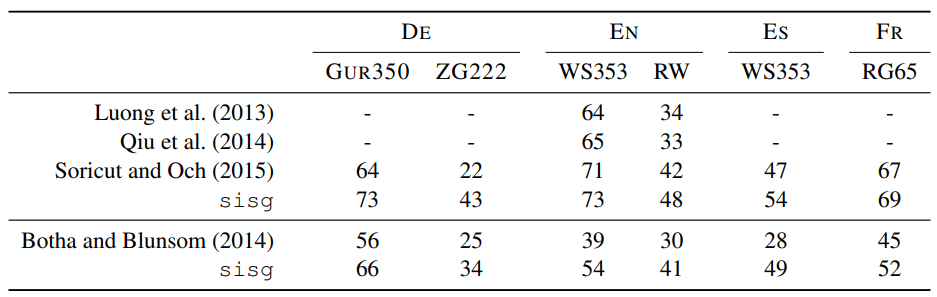
논문의 모델은 기존에 부분단어 정보를 포함하여 단어 벡터를 생성하는 모델과도 비교되었습니다. Recursive neural network, morpheme \texttt{cbow}, morphological transformations가 사용되었습니다. 또한 Botha의 연구에서 사용된 log-bilinear model과도 비교하였습니다. 실험 결과는 다음과 같습니다.
5.4 Effect of the size of the training data
데이터 규모에 따른 모델의 강건함을 평가하기 위해서 Wikipedia 데이터의 일부를 사용하여 학습한 후 성능을 측정하였습니다. 각각 1, 2, 5, 10, 20, 50%의 데이터를 사용하였고, reshuffle하지 않았기 때문에 더 큰 비율의 데이터는 작은 데이터를 포함합니다. 전반적으로 논문의 모델이 가장 성능이 좋았지만, 베이스라인 cbow 모델은 데이터가 많아질수록 성능도 향상되었습니다. 반면 논문의 모델은 빠르게 최고 성능에 도달하는 편입니다.
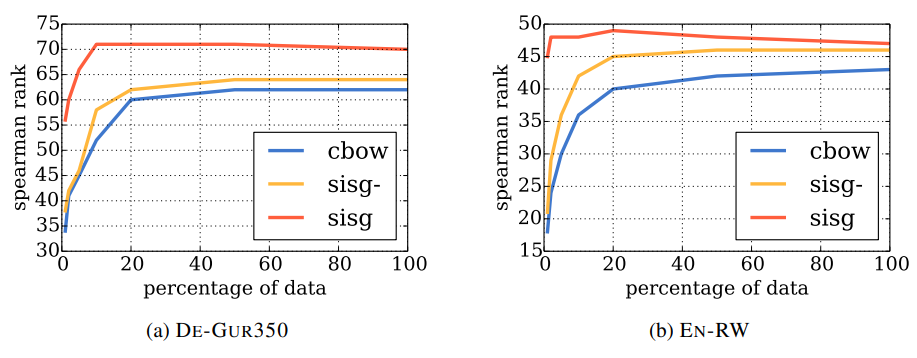
눈여겨 봐야 할 또 다른 결과는 논문의 모델은 적은 데이터로도 다른 모델보다 우수한 성능을 보인다는 것입니다. 일반적으로 단어의 벡터 표현을 사용할 때는 다운스트림 태스크에서 태스크와 관련된 텍스트로 재학습시키는 것이 권장됩니다. 하지만 이 실험 결과에서는 태스크와 관련된 데이터의 규모가 작더라도 기존에 학습된 단어 표현에서 많은 이점을 얻을 수 있다는 것을 시사합니다.
5.5 Effect of the size of n-grams
제안된 모델은 character n-gram을 사용하며, 앞에서 언급했듯이 3에서 6개의 문자를 통해 n-gram을 생성하였습니다. 이는 이 정도의 길이면 충분히 넓은 범위의 정보를 나타낼 것이라고 판단하여 임의로 선택한 것입니다. n-gram은 활용형이나 축약형 같이 짧은 접미사와 긴 어근을 모두 포함할 것입니다. 이를 확인하기 위해 실험을 통해서 실제로 결과를 비교해보았습니다.
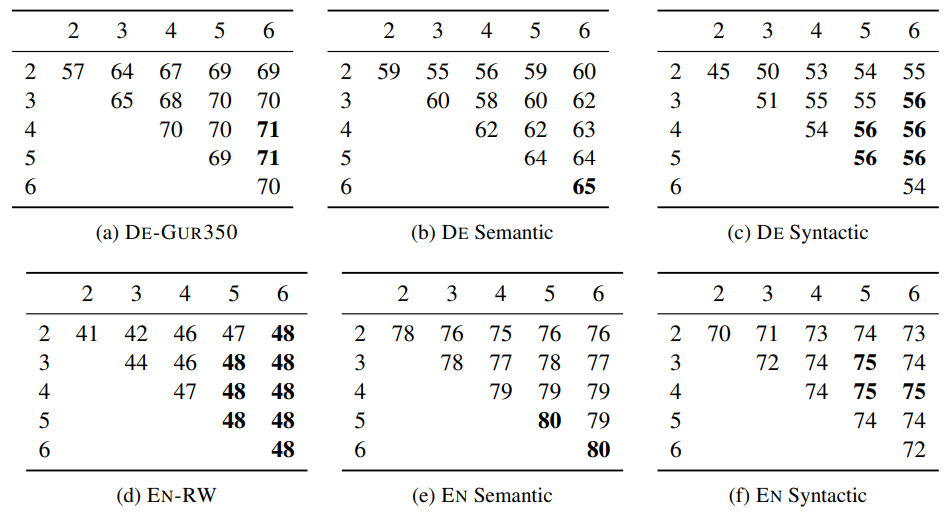
최적의 선택은 태스크나 언어에 따라 다르지만 일반적으로 3-6은 합리적인 값입니다. 또한 n-gram의 길이가 길수록 일반적으로 더 좋은 성능을 보입니다. 독일어의 경우 많은 명사가 합성되어 만들어졌기 때문에 더 좋은 성능을 보이는 것으로 해석됩니다. n이 2일 경우 성능에 거의 영향을 미치지 못합니다. 앞에서 언급했듯이 단어의 시작과 끝을 의미하는 기호를 추가하였기 때문에 단어의 경계에서 2-gram은 실제로는 하나의 문자만을 나타낼 것이기 때문에 접사에 대한 정보를 반영하지 못하기 때문입니다.
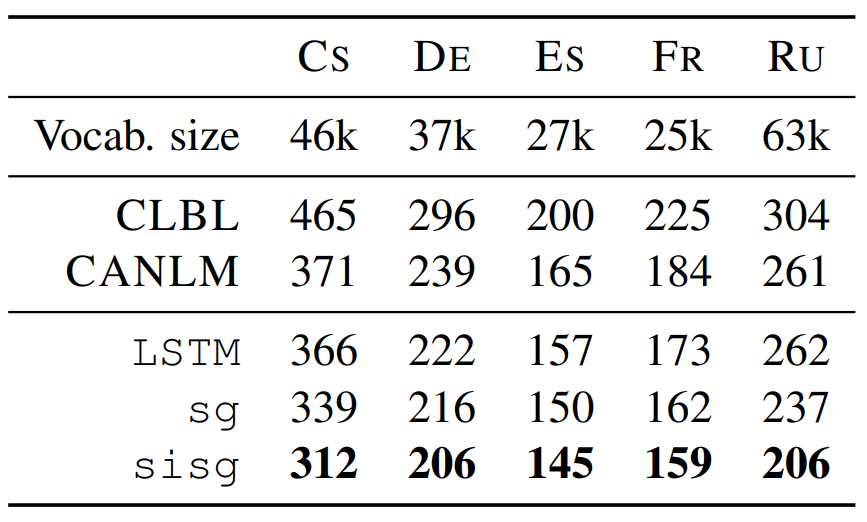
5.6 Language modeling
논문에서 제안한 방법을 통해 생성한 단어 벡터를 사용하여 언어 모델링 태스크의 성능을 평가하였습니다. 모델은 650개의 LSTM unit을 사용하는 recurrent neural network이며 dropout은 0.5, weight decay는 10^{-5}가 사용되었습니다. Adagrad 알고리즘과 학습률 0.1을 사용하였으며 norm이 1.0보다 큰 그라디언트는 clipping을 적용하였습니다. 모델의 가중치는 [-0.05, 0.05]로 초기화하였고 배치 사이즈는 20입니다. 베이스라인은 Botha의 log-bilinear model과 Kim의 character aware language model이 사용되었습니다. 사전 학습된 단어 벡터를 사용하지 않은 논문의 모델은 \texttt{LSTM}로 표기하였고 사전 학습된 단어 벡터를 사용하는 모델은 \texttt{sg}와 \texttt{sisg}입니다. 전자는 subword information을 포함하지 않은 단어 벡터를 사용하고, 후자는 이 정보를 포함합니다. 실험 결과는 다음과 같습니다. 측정 지표는 perplexity이며 그 값이 낮을수록 좋습니다. 다른 실험들과 마찬가지로 체코어와 러시아어처럼 형태학적으로 풍부한 언어가 더 많은 성능 향상을 보였습니다.
6. Qualitative analysis
6.1 Nearest neighbors
다음 표는 벡터 간의 코사인 유사도를 기반하여 선택된 단어에 대한 최근접 이웃 단어를 정리한 표입니다. 복잡하고 기술적이거나 희귀한 단어에 대해서는 베이스라인보다 논문의 모델이 실제로 더 연관된 단어를 찾는 것을 볼 수 있습니다.

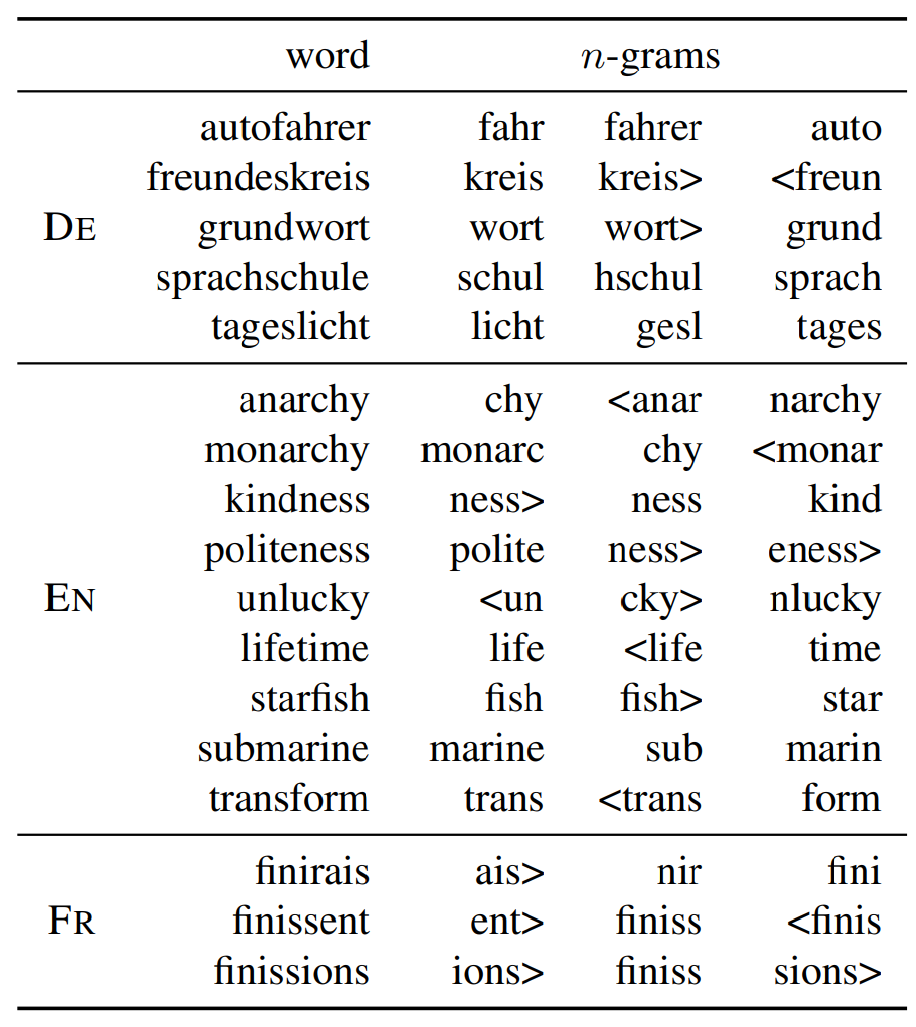
6.2 Character n-grams and morphemes
저자는 단어에서 가장 중요힌 n-gram이 형태소에 해당하는지 여부를 평가하고자 하였습니다. 이를 위해서 먼저 n-gram의 합으로 구축된 단어 벡터에 대해 생각해보겠습니다. 수식으로는 u_w=\sum_{g\in \mathcal{G_w}}z_g로 나타낼 수 있습니다. 그리고 각 n-gram g에 대하여, g를 제거한 제한된 표현 u_{w\backslash g}를 다음과 같이 계산합니다.
$$
u_{w\backslash g}=\sum_{g^{\prime}\in\mathcal{G}-{g}}z_{g^{\prime}}.
$$
그 후 u_w와 u_{w\backslash g}의 코사인 유사도에 따라 n-gram의 순위를 평가합니다. 다음 표는 세 개의 언어에서 선택된 단어에 대핸 n-gram rank입니다. 독일어는 많은 합성 명사를 포함하기 때문에, 가장 중요한 n-gram이 실제 형태소에 대응하는 것을 볼 수 있습니다. 또한 영어에서도 lifetime이나 starfish에서 이러한 예시를 확인할 수 있습니다. 또한 kindness나 unlucky와 같이 접사에 대응하는 경우도 있습니다. 프랑스어에서는 어미가 있는 동사의 굴절이 선택된 것을 확인할 수 있습니다.
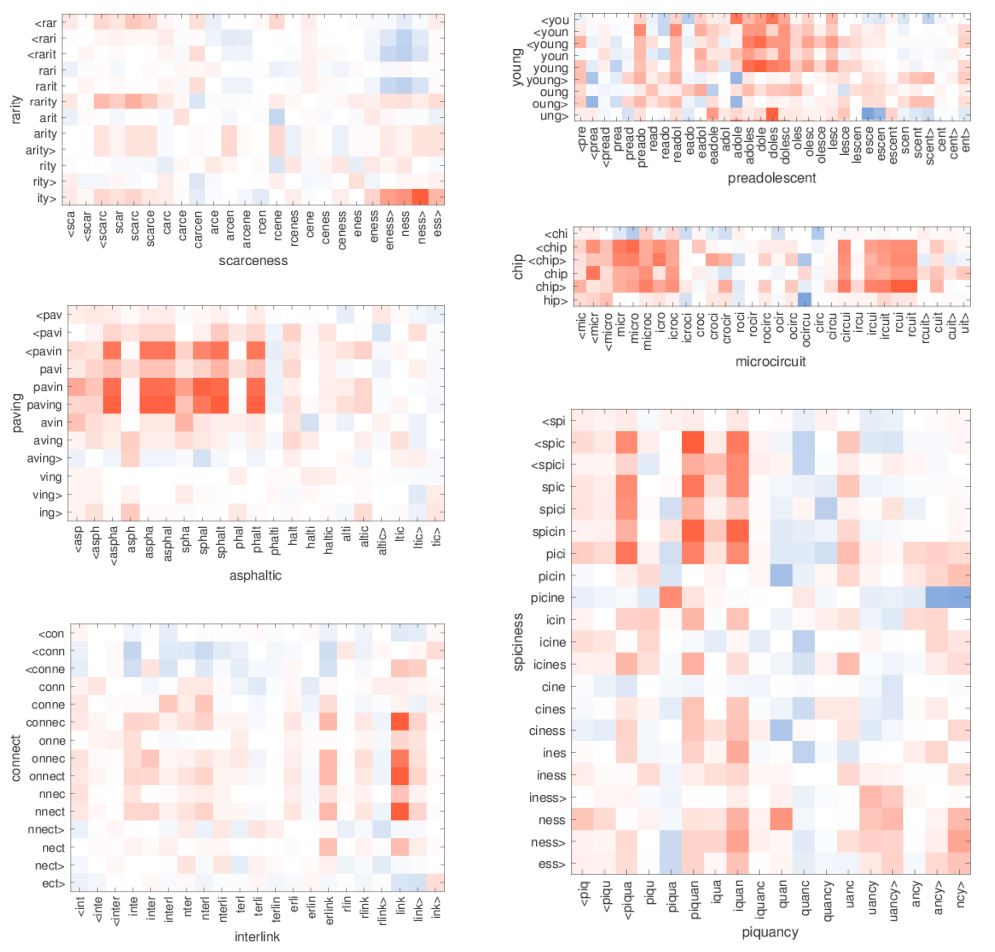
6.3 Word similarity for OOV words
논문의 모델은 학습 데이터셋에 나타나지 않은 단어에 대한 벡터도 생성할 수 있습니다. 그러한 단어는 단순히 n-gram의 평균을 계산하여 사용합니다. 이 벡터의 품질을 평가하기 위해서 저자는 영어 RW(rare word) similarity 데이터셋에서 몇 개의 단어 쌍을 선택하여 실험을 진행하였습니다. 단어 쌍에서 두 단어 중 하나는 학습 데이터에 포함되지 않습니다. 실험 결과는 다음 그림과 같으며, 유사도가 높을 수록 빨간색에 가깝습니다.
흥미로운 점은 부분 단어끼리 잘 대응이 된다는 것입니다. 예를 들어, 단어 chip이 microcircuit의 두 개의 n-gram 대응하는 것을 볼 수 있습니다. 두 n-gram은 대략 micro와 circuit 그 사이에 있는 n-gram과는 유사도가 높지 않습니다. 또한 rarity와 scarceness의 예시에서 접미사 -ness와 -ity가 잘 매치되는 것을 볼 수 있습니다.
7. Conclusion
논문에서는 부분 단어에 대한 정보(subword information)을 고려하여 단어의 벡터 표현을 학습하는 간단한 방법을 제안하였습니다. 논문의 접근법은 skipgram 모델에 character n-gram을 포함하였습니다. 이 모델은 단순하기 때문에 훈련 속도가 빠르며 전처리나 지도학습이 필요하지도 않습니다. 또한 실험을 통해 이 모델이 subword information을 학습하지 않는 베이스라인 뿐만 아니라 형태학적 분석에 의존하는 다른 모델보다도 뛰어난 성능을 보임을 입증하였습니다.
8. Reflection
계속해서 업로드한 리뷰에서 다룬 논문이 대부분 단어 임베딩에 관한 것이었는데 어느 정도 마무리가 되어가는 것 같습니다. 어쩌다보니 contextualized vector에 대한 리뷰를 먼저 올리고 뒤늦게 static embedding에 대해 공부하였습니다. 왜인지 모르게 과거 논문이 복잡한 수식이 많고 수학적인 배경지식을 많이 요구해서 난이도 면에서는 적절한 순서였던 것 같고, 그래고 여러 논문을 읽으며 NLP의 전반적인 흐름에 대해서 조금이나마 이해가 된 것 같아서 유익했습니다. 단어 임베딩과 관련한 전반적인 흐름을 다시 정리하고 토큰화나 언어 모델에 대한 개념을 조금 더 다져보고 싶다는 생각이 들었습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] Word Translation Without Parallel Data (2) (0) | 2023.11.05 |
|---|---|
| [논문리뷰] Word Translation Without Parallel Data (1) (0) | 2023.11.04 |
| [논문리뷰] GloVe: Global Vectors for Word Representation (1) | 2023.10.27 |
| [논문리뷰] Attention Is All You Need (1) | 2023.10.24 |
| [논문리뷰] Linguistic Regularities in Continuous Space Word Representations (0) | 2023.10.20 |




댓글