
Contextualized Embedding에 대해 정말 폭넓은 연구를 수행한 논문인 Linguistic Knowledge and Transferability of Contextual Representations를 리뷰해보았습니다. 앞서 리뷰했던 contextualized representations 관련한 논문과 비슷한 부분이 많지만, 해당 논문들에서 수행한 연구를 결과를 통합하며, 추가적인 실험도 수행하였습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
Overview
사전 학습된 단어 표현은 최고의 성능을 내는 신경망 기반 NLP 모델의 핵심 요소입니다. 전통적으로 단어 벡터는 정적이었는데, 이는 각 단어에 하나의 벡터만이 할당됨을 의미합니다. 이내 각 단어에 입력 시퀀스 전체에 대한 함수를 기반으로 벡터를 할당하는 연구가 이루어졌습니다. 이러한 벡터는 contextual word representations(CWR)라고 불립니다. CWR 덕분에 같은 단어라도 문맥에 따라 모델링할 수 있게 되었습니다. CWR은 기본적으로 기계 번역이나 언어 모델링과 같은 태스크에서 대규모 데이터셋으로 훈련된 신경망의 출력입니다. CWR 덕분에 NLP 태스크에서 모델 성능은 크게 향상되었습니다.
CWR이 올린 성과는 이러한 벡터가 언어의 유용하고, 전이 가능한 특성을 잘 인코딩한다는 것을 의미합니다. 하지만 CWR이 어떤 언어학적 지식을 갖고, 전이 가능성을 어떻게 갖는지에 대한 이해는 미흡합니다. 이를 이해하기 위해 이루어진 연구는 계층적 구문론(hierarchial syntax)이나 형태론(morphology)에 대한 지식과 같이 하나의 현상에만 집중합니다. 논문의 저자는 기존의 연구를 확장하여, CWR를 다양한 probing tasks에 대하여 폭넓은 연구를 수행하였습니다.
프로빙 태스크(probing task)는 진단 분류기(diagnostic classifiers), 보조 분류기(auxiliary classifier) 또는 decoding이라고도 불립니다. 이는 한 시스템의 인코딩된 표현을 사용하여 다른 (probing) 작업에 대해 다른 분류기를 훈련하는 것입니다. Probing task는 특정 언어 현상을 분리하는 방식으로 설계되기 때문에 작업을 잘 수행하면 시스템이 학습한 언어에 대한 현상을 잘 인코딩한 것이라고 이해할 수 있습니다.
새로운 인코더 아키텍처를 통한 성능 향상과 인코더의 강점을 기반으로 하거나 약점을 완화하는 사전 학습 작업을 위해서는 CWR의 언어적 지식과 전이 가능성을 잘 이해하는 것이 필수적입니다. 논문에서는 다음과 같은 문제에 대한 답을 찾습니다. 여기서 contextualizer는 각 단어에 대해 문맥에 따른 벡터를 할당하도록 학습된 모델을 의미합니다.
- CWR은 언어의 어떤 특성을 이해하였고, 무엇을 놓치고 있을까?
- 전이 가능성은 contextualizer의 각 레이어에서 어떻게 그리고 왜 다를까?
- 사전학습 작업을 선택하는 것은 벡터의 언어적 지식과 전이 가능성을 학습하는 데 어떤 영향을 미칠까?
저자는 프로빙 모델을 사용하여 CWR이 담고 있는 언어 정보를 분석하였습니다. 사전 학습된 contextualizers에서 단어에 대한 특성(features)을 생성하고 , 이 특성들만을 가지고 모델은 예측을 수행합니다. 이를 통하여 CWR에 대하여 다음과 같은 흥미로운 인사이트를 밝혔습니다.
- 가중치를 고정한 CWR에 기반하여 훈련된 선형 모델은 많은 경우에 관련 태스크에서 SOTA(state-of-the-art) 모델이 되었습니다.
- LSTM의 첫 번째 레이어의 출력은 일반적으로 가장 전이가 잘 되며, 트랜스포머의 경우 중간에 위치한 레이어가 전이가 잘 이루어집니다.
- LSTM의 상위 레어이로 갈수록 더욱 태스크에 특화되며, 트랜스포머는 하나의 양상을 보이지는 않습니다.
- 다른 태스크보다 언어 모델링을 통해 사전 학습하는 것은 일반적으로 전이가 잘 이루어지는 표현을 생성합니다.
2. Probing Tasks
논문에서는 17개의 영어를 사용한 프로빙 태스크를 설계하여 CWR의 언어적 지식을 이해하고자 하였습니다. 이전 연구는 문장 임베딩에 주로 집중했지만, 저자는 각 단어 또는 단어 쌍이 갖는 의미에 집중하여 연구하였습니다.
2.1 Token Labeling
저자는 이전에 수행한 토큰 레이블링에 대한 개별적인 연구를 통합하고 새로운 프로빙 태스크를 제안하였습니다.
Part-of-speech tagging (POS)
형태소 태깅은 CWR의 구문에 대한 기본적인 이해를 평가합니다.
CCG supertaggig (GGC)
CCG는 Combinatory Categorial Grammar의 약어입니다. 이 태스크는 각 단어에 CCG 카테고리 또는 supertag를 할당하는데, 단어가 문맥 내에서 갖는 의미적인 역할을 평가합니다.
Syntactic consistuency ancestor tagging
이 태스크는 벡터의 hierarchical syntax에 대한 지식을 평가하기 위해 설계되었습니다. 단어가 주어지면 프로빙 모델은 구조 트리(phrase-structure tree)에서 단어의 parent, grandparent 또는 grand-grandprarent에 대한 constituent label을 예측합니다.
Semantic tagging
각 토큰에는 문맥 내에서 갖는 의미 역할을 반영하여 레이블이 할당됩니다. 의미 태그(semantic tag)는 사전적 의미를 평가하며, 중복되는 형태소를 추상화하고 형태소 태그의 모호함을 해소합니다.
다음 태스크를 설명하기 전에, 앞서 언급한 네 가지 태스크가 어떻게 다른지를 간단하게 설명해보겠습니다. 먼저 형태소 태깅(POS tagging)은 각 단어에 명사(noun), 동사(verb), 형용사(adjective), 부사(adverb)와 같은 형태소를 부여하는 작업입니다. 예를 들어 The cat sat on the mat.라는 문장이 주어지면 The는 관형사(Determiner), cat은 명사(Noun), sat은 동사(Verb), on은 전치사(Preposition), the는 관형사(Determiner), mat는 명사(Noun)으로 구분할 것입니다.
CCG supertagging은 각 단어에 구문 에서의 동작을 조금 더 상세하게 표현하는 supertag를 할당합니다. 이 태스크는 POS 태깅보다 조금 더 세밀하게 구문을 분석합니다. 예를 들어 She gave a book.이라는 문장에서 gave는 주어와 목적어를 취하는 타동사(transitive verb)라는 조금 더 구체적인 태그가 부여됩니다.
Consistuency parsing은 문장을 트리 구조로 분석합니다. 예를 들어 The cat sat on the mat.라는 문장은 The cat이라는 명사구(noun phrase)와 on the mat라는 전치사구(prepositional phrase)로 나뉜 뒤 다시 한 번 각 요소에 대한 분석이 이루어집니다.
마지막으로 Semantic tagging은 각 단어에 agent, patient, instrument 등의 의미역(semantic role)를 부여합니다. 예를 들어 She gave him a book.라는 문장에서 She는 Agent(주체), him은 Goal(목표), book은 Theme(사건에 가장 직접적인 영향을 받는 대상)이라는 의미역이 부여됩니다.
Preposition supersense disambiguation
이 태스크는 전치사의 사전적 의미 기여도(PS-fxn 함수)와 의미적 역할 및 연결하는 대상의 관계를 분류합니다. 예를 들어 다음과 같이 굵은 글씨로 표시된 전치사 뒤에 labeled function이 위치합니다. ↝ 뒤에는 전치사에 대한 추가적인 정보가 제공됩니다.

Event factuality (EF)
이 태스크는 어떤 사건의 사실성을 판단합니다. 예를 들어 다음 예시에서 첫 번째 문장은 두 번째 문장과 표면적으로는 비슷하지만, Jo가 실제로는 떠나지 않았음을 의미합니다.
- Jo didn’t remember to leave. (Jo는 떠나는 것을 기억하지 못했습니다.)
- Jo didn’t remember leaving. (Jo는 떠난 것을 기억하지 못했습니다.)
2.2 Segmentation
프로빙 태스크에는 BIO나 IO 태깅을 사용하는 segmentation 작업이 포함됩니다.
Syntactic chunking (Chunk)
CWR이 텍스트를 얕은 구문 단위(shallow constituent chunk)로 분할하여 span과 이들의 경계에 대한 개념을 이해하는지를 평가합니다.
Named Entity Recognition (NER)
CWR이 개체 유형을 이해하는지를 평가합니다. 예를 들어 어떤 단어가 장소인지, 사람인지, 기관인지 등을 분류합니다.
Grammatical error detection (GED)
문법적으로 옳은 문장이 되기 위해서 단어가 수정되어야 하는지를 분류하는 작업입니다.
Conjunct identification (Conj)
접속사를 구성하는 토큰을 식별하는 태스크입니다. 이 작업을 수행하기 위해서는 구문에 대한 깊은 이해를 필요로 합니다.
2.3 Pairwise Relations
프로빙 태스크는 단어 사이의 관계가 CWR에 인코딩되어 있는지도 평가합니다. 이 작업에서는 두 단어 w1, w2가 쌍으로 주어지면 [w1,w2,w1⊙w2]이 프로빙 모델의 입력이 됩니다. 이 작업은 arc prediction과 arc classification으로 분류합니다. Arc prediction은 모델이 두 토큰 사이에 관계가 있는지를 평가하는 이진 분류 태스크입니다. Arc classification은 어떤 관계를 갖는 두 토큰이 주어지면, 그들이 어떤 관계인지를 판단하는 다중 클래스 분류 태스크입니다.
Syntactic dependency arc prediction
모델에 두 토큰의 표현 (wa,wb)가 주어지고 문장의 구문 의존성 분석(syntactic dependency parse)에 wa를 head로 하고, wb를 modifier로 하는 dependency arc가 포함되어 있는지를 예측하도록 훈련됩니다.
Syntactic dependency arc classification
모델에 whead와 수식어(modifier)인 wmod의 두 토큰 (whead,wmod)이 주어지면 이들의 관계를 예측하도록 훈련됩니다.
Semantic dependency arc prediction
모델은 두 토큰이 semantic dependency arc에 의해 연결되어 있는지를 평가합니다.
Semsntic dependency arc classification
모델은 두 토큰의 의미적 관계를 분류합니다.
여기서 syntactic과 semantic의 차이는 이렇습니다. Arc prediction을 예로 들면, syntactic dependency arc prediction 태스크에서는 문장 내의 두 단어 사이에 문법적인 관계가 있는지를 결정합니다. 예를 들어서 She quickly reads books.라는 문장이 있을 때 She와 reads 사이에는 문법적 관계가 있지만, quickly와 books 사이에는 관계가 있다고 보기 어렵습니다.
반면 semantic dependency arc prediction 태스크는 문법이 아닌 의미적 관계를 확인합니다. 예를 들어 She gave him a book.라는 문장을 생각해보겠습니다. 여기서 She와 gave, him과 gave는 모두 주는 사람, 받는 사람이라는 의미적 관계를 갖지만, she와 book 사이에는 gave라는 단어에 의한 문법적 관계만 형성될 뿐, 의미적 관계가 있다고 보기 어렵습니다.
Dependency arc prediction 태스크의 음성 샘플(negative examples)를 생성하기 위해서 저자는 양성 샘플 (whead,wmod)를 사용하여 (wrand,wmod)를 생성하였습니다. wrand는 문장 내에서 head가 아닌 임의의 토큰입니다.
Coreference arc prediction
모델은 두 개체가 같은 대상을 가리키지를 예측하도록 훈련됩니다. 여기서도 음성 샘플을 생성하는 과정을 거쳤습니다. wb가 wa보다 나중에 나타나는 토큰일 때, 양성 샘플 (wa,wb)를 사용하여 음성 샘플 (wrandomentity,wb)를 생성하였습니다. 여기서 wrandomentitiy는 다른 상호참조 클러스터(coreference cluster)에 속하며 wb 이전에 등장하는 임의의 토큰입니다.
3. Models
Probing Model
프로빙 모델로는 선형 모델을 사용하였습니다. 프로빙 모델의 용량을 제한함으로써 CWR에서 어떤 정보를 추출할 수 있는지에 집중하였습니다.
Contextualizers
공식적으로 사용 가능한 여섯 개의 영어에 대하여 문맥화된 단어 표현(contextualized word representation)을 사용하였습니다.
ELMo
ELMo는 biLM 태스크에서 독립적으로 학습한 두 개의 contextualizers의 출력을 연결합니다. ELMo (original)은 두 개의 레이어를 갖는 LSTM을 사용합니다. 원본의 두 가지 변형을 사용하였는데, 4개의 LSTM 레이어를 갖는 ELMo (4-layer)와 6개의 트랜스포머 레이어를 갖는 ELMo (transformer)입니다.
OpenAI transformer
왼쪽에서 오른쪽 방향으로 학습된 12개의 트랜스포머 레이어를 갖는 모델입니다. 흔히 GPT로 알려져 있습니다. 참고로 여기서는 레퍼런스 논문이 Improving language understanding by generative pre-training로 되어있는 것으로 보아 GPT-1을 사용한 것으로 생각됩니다.
BERT
양방향 트랜스포머를 사용하여 마스크드 언어 모델링과 다음 문장 예측 태스크를 동시에 학습한 모델입니다. 여기서는 12개의 트랜스포머 레이어를 갖는 BERT (base, cased)와 24개의 트랜스포머 레이어를 갖는 BERT (large, cased)를 사용하였습니다.
4. Pretrained Contextualizer Comparison
논문에서는 여러 프로빙 태스크에서 contextualizer의 각 레이어에 대해 분석을 수행하였습니다.
4.1 Experimental Setup
프로밍 모델은 각 contextualizer의 개별 레이어에서 생성된 벡터 표현을 사용하여 훈련되었습니다. 또한 contextualization의 효과를 제대로 측정하기 위하여 noncontextual vector인 GloVe를 사용하여 훈련한 선형 프로빙 모델과의 성능도 비교하였습니다.
4.2 Results and Discussion
GloVe를 사용하는 프로빙 모델을 베이스라인으로 하여 각 contextualizer와 비교한 결과는 아래와 같습니다. 단순히 선형 모델만을 추가하는 것으로 CWR은 다양한 NLP 태스크에서 뛰어난 성능을 보입니다. 그리고 모든 경우에 CWR은 noncontextual 베이스라인보다 훨씬 뛰어납니다. 게다가 많은 경우에 프로빙 모델이 각 태스크에 대하여 세심하게 튜닝된 기존의 SOTA 모델보다 뛰어나거나 성능이 견줄만 합니다.
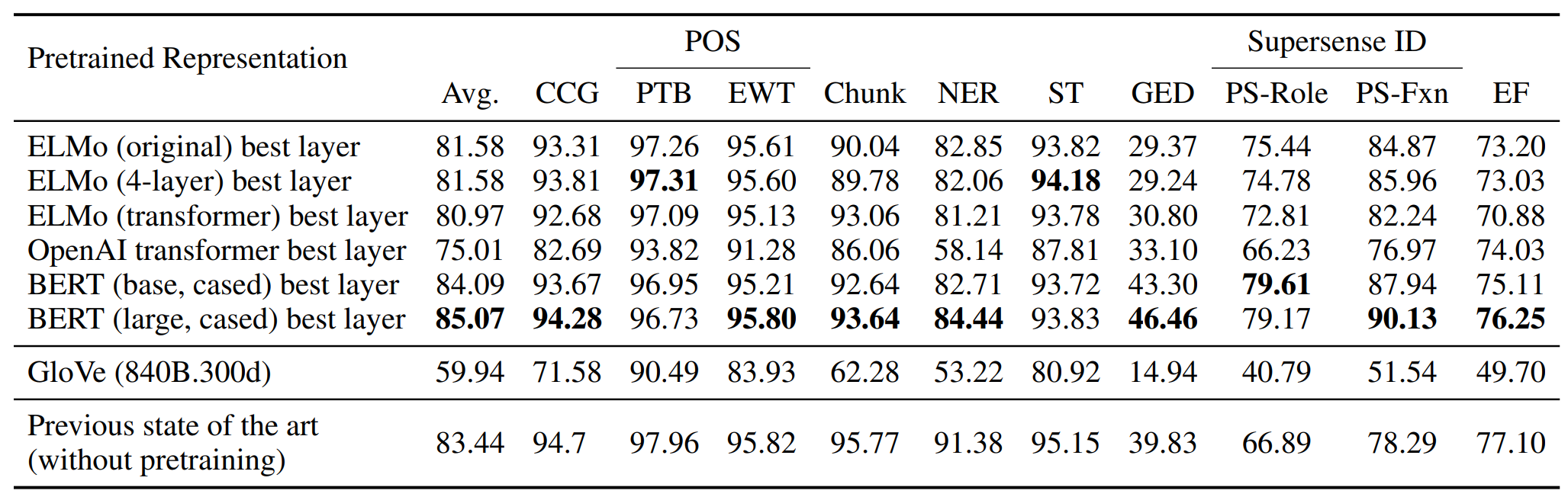
ELMo 계열에서는 트랜스포머보다 LSTM을 사용한 모델의 성능이 더 나았습니다. 또한 OpenAI transformer가 ELMo나 BERT보다 성능이 좋지 못하다는 점을 통해, 양방향성(bidirectionality)가 갖는 이점을 재확인할 수 있었습니다.
Probing Failures
프로빙 모델이 많은 경우 매우 우수한 성능을 보이지만, NER, 문법 오류 검사(grammatical error detection), 접속사 식별(conjunct identification)과 같은 태스크에서는 좋은 모습을 보이지 못했습니다. 이 원인은 (1) CWR이 단순히 이와 관련 정보나 predictive correlates를 인코딩하지 않거나, (2) 프로빙 모델의 크기가 작아서 관란 졍보나 predictive correlates를 추출하기에는 충분하지 않기 때문일 것입니다. 여기서 correlates는 보통 다른 변수나 결과와 통계적인 상관관계를 갖는 요인을 의미합니다. 따라서 predictive correlates는 따라서 어떤 결과를 예측하는데 사용할 수 있는 요소라고 생각할 수 있습니다. 전자의 경우 태스크별 contextual features를 학습하여야 할 것이며, 이는 후자의 경우에도 도움이 되겠지만, 저자는 단순히 모델 크기를 크게 하는 것만으로도 이 문제는 해결될 것이라고 생각하였습니다.
프로빙 모델의 실패를 분석하기 위해서 (1) 각 태스크에서 학습된 LSTM을 contextual probing model로 사용하거나, (2) 선형 프로빙 모델을 다층 퍼셉트론(MLP)으로 대체하여 실험하였습니다. 각 프로빙 태스크에서의 성능의 상한을 확인하기 위하여 full-feature model도 사용하였습니다. 여기서 CWR은 2-레이어 BiLSTM의 입력으로 사용되었고, 출력은 MLP로 주입되어 ReLU 레이어를 통해 예측을 생성합니다.
이 실험에서는 ELMo (original) pretrained contextualizer를 사용하였습니다. 실험 결과는 다음 표와 같습니다. 앞의 두 태스크는 선형 프로빙 모델과 기존 SOTA 모델의 성능 격차가 가장 컸던 태스크에 대한 실험이며, 뒤의 두 태스크는 고차원적인 구문에 대한 이해를 필요로 합니다.
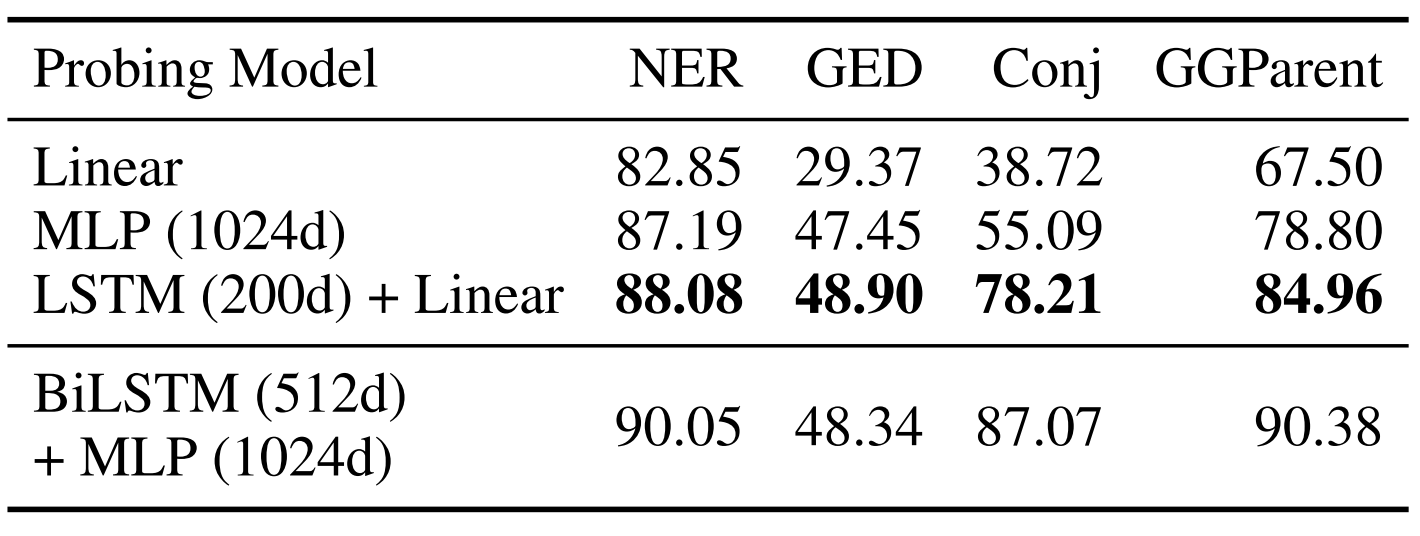
모든 경우에, 선형 모델을 다층 퍼셉트론으로 교체하거나, LSTM을 사용하여 파라미터를 추가하는 것으로 성능이 상당히 개선되었습니다. NER과 GED는 파라미터를 추가한 세 가지 방법의 성능이 비슷한데, CWR로부터 필요한 정보를 추출하기 위해 더 큰 용량이 필요했을 뿐임을 알 수 있습니다. 반면 Conj identification이나 GGParent Prediction에서는 단순히 파라미터를 추가하는 방법보다 task-trained component로써 파라미터를 추가할 경우 성능이 큰 폭으로 향상되었습니다. 즉 pretrained contextualizers가 이 태스크에 필요한 정보를 충분히 추출하지 못하였음을 알 수 있습니다.
5. Analyzing Layerwise Transferability
저자는 CWR이 다양한 프로빙 태스크를 어떻게 수행하는지를 연구하며 CWR의 전이 가능성을 정량화하였습니다. 아래 그림과 같이 사전 학습된 contextualizer의 각 레이어에서 생성한 표현에 대한 패턴을 분석하였습니다. 순환 모델은 첫 번째 레이어가 가장 transferagble합니다. 반면 트랜스포머 기반 contextualizer는 가장 transferable한 레이어가 일정하지 않지만, 대부분의 경우 중앙 근처에 위치합니다.
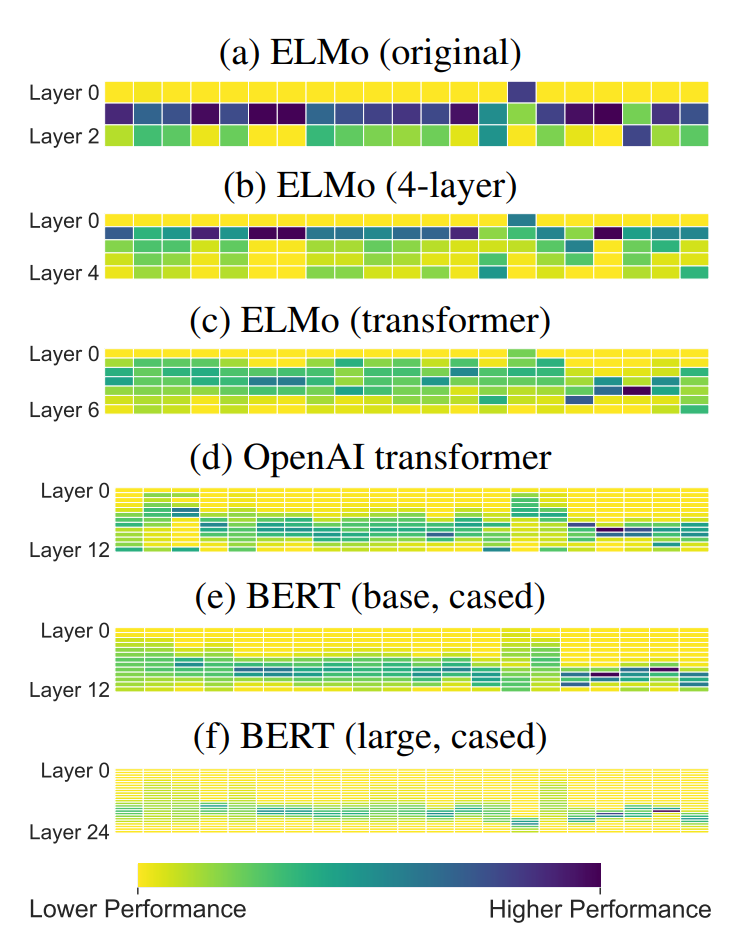
사전 학습은 모델이 사전학습에 특화된 정보를 인코딩하게 합니다. 따라서 전이 가능한 특성은 우연히 학습될 것입니다. 이러한 모델은 모두 고정된 크기의 벡터 표현을 사용하기 때문에 작업 특이성(task-specificity)은 일반성과 전이 가능성을 희생하여 얻게 되며, 저자는 이를 내재된 절충점(inherent trade-off)라고 하였습니다. 이어서 저자는 각 contextualizer layer에 의해 생성된 작업 특이성을 분석하였습니다.
5.1 Experimental Setup
여기서는 ELMo에 기반한 모델을 사용하여 CWR이 사전 학습 태스크인 양방향 언어 모델링을 얼마나 잘 수행하는지를 평가하였습니다. 각 레이어의 사전 학습된 표현을 사용하여 language model softmax classifiers를 재학습하여 다음과 이전에 위치할 토큰을 예측하게 하였습니다. 이 실험에서는 소프트맥스 분류기가 사전 학습 태스크에 대한 정보를 잘 포착하는 레이어의 표현으로 훈련될 경우 biLM perplexity가 더 낮을 것이라는 전제가 깔려 있습니다.
5.2 Results and Discussion
다음 그래프는 CWR만이 입력으로 주어졌을 대 소프트맥스 분류기의 성능을 나타낸 것입니다. 4-레이어 ELMo에서 첫 번째와 두 번째 레이어의 성능이 거의 비슷하다는 점이 흥미롭습니다. 반면 ELMo (transformer)는 단조로운 패턴을 갖지는 않습니다. 저자가 예상한 대로 가장 마지막 레이어가 가장 좋은 성능을 보입니다. 모든 모델에서 언어 모델링 태스크를 잘 수행하는 표현을 생성하는 레이어는 프로빙 태스크에서는 뛰어난 성능을 보이지 않습니다. 이는 contextualizer 레이어가 일반적인 특성과 태스크에 특화된 특성을 인코딩하는 데 트레이드오프를 갖는다는 것을 의미합니다.
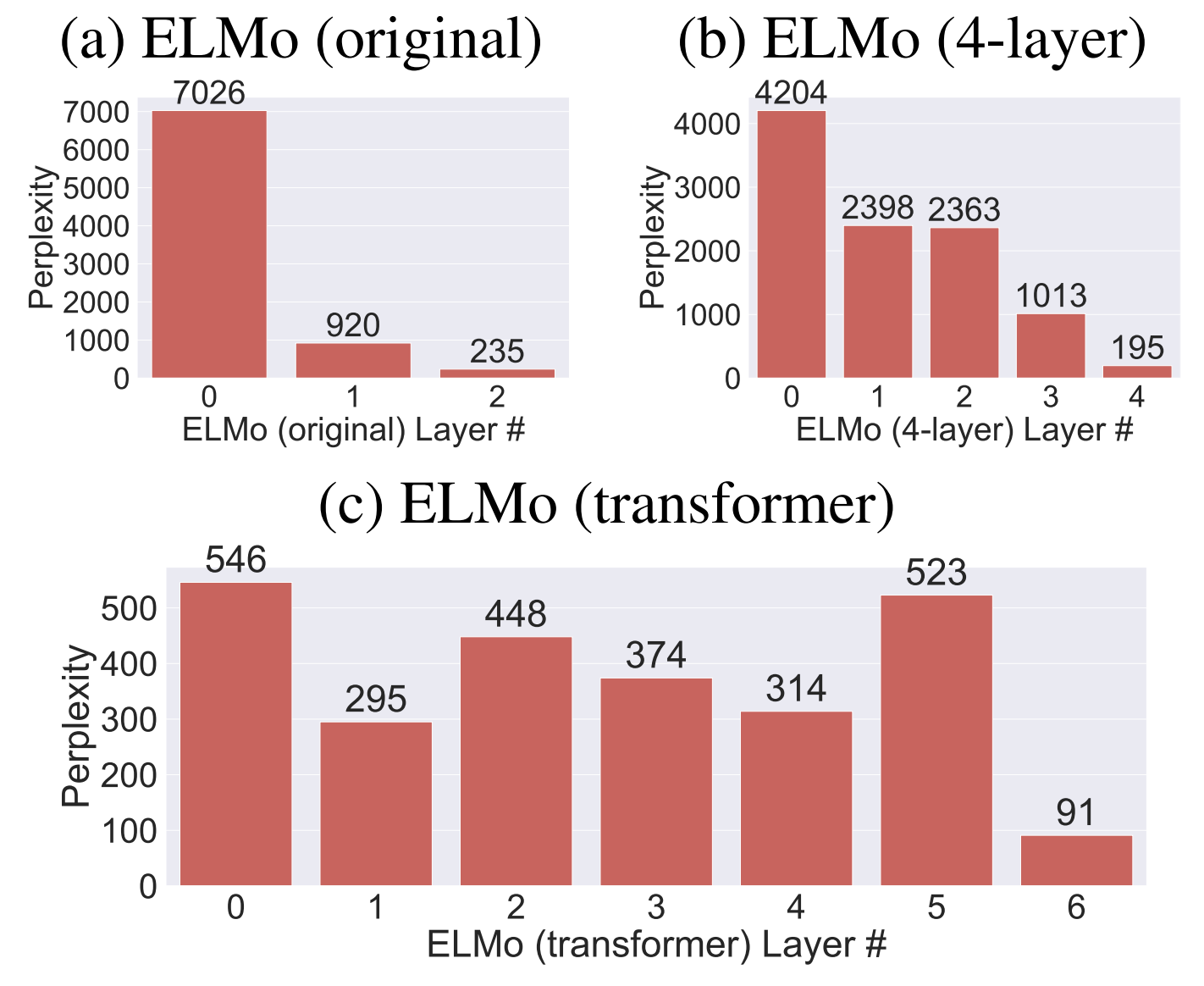
이 결과는 또한 LSTM의 상위 레이어가 태스크에 특화된 표현을 생성한다는 사실을 드러냅니다. 하지만 트랜스포머는 같은 동작 원리를 보이지는 않습니다. 이 결과는 파인튜닝 과정에서 gradual unfreezing(점차적으로 사전 학습된 모델의 가중치의 고정을 해제하는 것) 방식에 영향을 줄 것입니다. 상위 LSTM 레이어는 일반적인 정보를 덜 포함하고 있기 때문에 태스크에 특화된 정보를 학습하기 위해서는 파인튜닝이 조금 더 필요할 것입니다. 반면에 하위 레이어는 이미 전이 가능한 특성을 학습했기 때문에 파인튜닝의 이점을 얻지 못할 수도 있습니다.
6. Transferring Between Tasks
뛰어난 성능을 보이는 사전 학습된 contextualizers은 양방향 언어 모델링(ELMo), 다음 문장 예측(BERT)과 같은 자기 지도 학습(self-supervised tasks)를 사용하였습니다. 이러한 사전 학습 기법은 레이블이 없는 대규모 텍스트 데이터를 사용할 수 있습니다. 하지만 contextualizers는 명시적으로 지도 학습 목표를 통해 사전 학습될 수도 있습니다. 사전 학습 태스크를 선택하는 것이 CWR이 갖는 언어적 지식과 전이 가능성에 어떤 영향을 미치는지 이해하기 위해서, 저자는 다양한 지도 학습 태스크와 양방향 언어 모델링 태스크를 통한 사전학습을 비교하였습니다.
6.1 Experimental Setup
비교를 위해서 서로 다른 사전 학습 태스크에 대하여, contextualizer의 아키텍처와 사전 학습 데이터셋은 고정하였습니다. 모든 실험에서 ELMo (original) 아키텍처를 사용하였고, 학습 데이터는 PTB를 사용하였습니다. 따라서 각 모델은 같은 토큰을 사용하지만, 지도 학습 방법만이 다를 뿐입니다. 저자는 (1) non-contextual baseline인 GloVe와 (2) 사전 학습의 영향을 평가하기 위해서 임의로 초기화된, 학습되지 않은 ELMo (original) 베이스라인, (3) 더 많은 데이터(Billion Word Benchmark)를 사용하여 양방향 언어 모델링을 통해 사전 학습된 ELMo (original)과 비교하였습니다.
6.2 Results and Discussion
아래 표는 12개의 서로 다른 태스크에서 사전 학습된 contextualizers의 각 레이어의 타겟 태스크에 대한 성능을 평균한 것입니다. 평균적으로 양방향 언어 모델링의 사전 학습 효과가 가장 좋았습니다. 하지만 각 다운스트림 태스크에서 가장 뛰어난 성능을 보인 경우는, 관련 사전 학습 목표를 통해 학습하였을 때입니다. 이 결과는 여러 개의 표로 나타나있어 본문에는 포함하지 않았지만, 논문의 Appendix에서 찾아볼 수 있습니다.
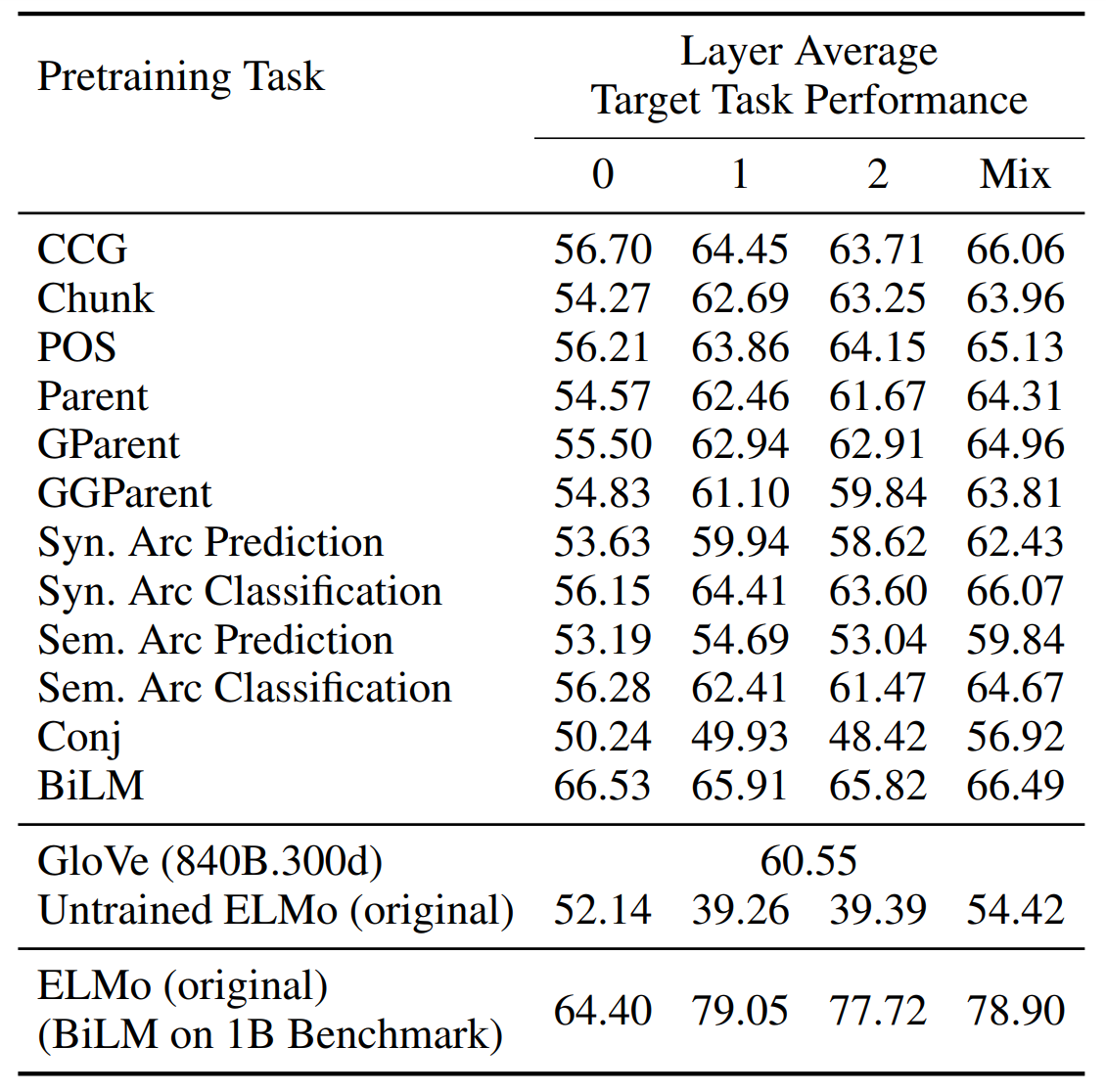
관련 태스크에서 학습한 지식을 전이하는 게 더 좋지만, 일반적으로 더 많은 데이터에서 학습한 경우 나은 성능을 보였습니다. 이는 사전 학습된 CWR의 전이 가능성은 학습 데이터의 규모에 영향을 받으며, self-supervised pretraining의 중요성을 강조합니다.
BiLM의 0번째 레이어는 PTB로 사전학습된 contextualizer의 단일 레이어로써는 가장 우수한 성능을 보입니다. 이 결과는 어휘 정보가 모델의 초기 일반화 가능성(initial generalizability)의 원천임을 의미합니다. 0번째 레이어는 토큰 수준의 문맥 정보가 없는 문자 수준의 합성곱 신경망(character-level convolutional neural network)이기 때문입니다.
7. Conclusion
논문에서는 Contextualized Word Representations(CWR)의 언어적 지식(linguistic knowledge)와 전이 가능성(transferability)를 17개의 다양한 프로빙 태스크(probing tasks)를 통해 연구합니다. 사전 학습된 contextualizer에서 생성된 특성(feature)은 넓은 범위의 태스크에서 뛰어난 성능을 보입니다. 저자는 CWR이 포착하지 못한 특정한 정보가 필요한 태스크에 대해서는, task-specific contextual features를 학습하면 필요한 지식을 인코딩하는 데 도움이 된다는 것을 입증하였습니다. 또한 연구를 통해 LSTM의 하위 레이어는 더 전이가 잘되는 특징을 인코딩하고, 상위 레이어에서는 보다 작업에 특화되어 있다는 것을 발견하였습니다. 트랜스포머의 경우 전이가 잘 되는 특성이 주로 중간에 위치한 레이어에서 학습되며, 작업에 특화된 특성에 대해서는 일정한 패턴을 보이지는 않았습니다. 이전 연구에서는 higher-level contextualizer layer가 higher-level semantic information을 인코딩한다고 하였습니다. 즉 출력에 가까운 레이어가 더 높은 수준의 의미 정보를 포착한다고 하였습니다. 하지만 저자는 이 현상을 특정한 고수준의 의미 현상은 contextualizer의 사전 학습 태스크에 유용하기 때문에 우연히 상위 레이어에 인코딩 된 것으로 보인다고 해석하였습니다. 마지막으로 연구를 통해 양방향 언어 모델링을 통해 사전 학습된 모델이 11개의 다른 사전 학습 태스크보다 더 전이가 잘 되는 representation을 생성한다는 것을 발견하였습니다.
8. Further Thinking
최근 리뷰한 논문은 대부분 단어 임베딩에 관한 것이었고, 특히 contextual representations이 static embedding에 비해 갖는 장점을 다루었습니다. 이전 논문은 벡터가 갖는 등방성의 의미, contextualized word embeddings가 어떤 상황에서 강점을 갖는지, CWR이 학습하는 장거리 의존성, ELMo의 각 레이어가 학습하는 정보 등에 대해 다룹니다. 이 연구에서는 앞선 논문들의 연구 결과를 대부분 포함하면서 이를 확장합니다. 다양한 모델의 각 레이어가 학습하는 정보가 무엇인지, 사전 학습 태스크에서 학습한 언어에 대한 지식이 어떻게 전이되는지를 폭넓은 실험을 통해 연구합니다. 단순히 CWR은 입력에 대한 함수이기 때문에 문맥에 따른 단어의 의미를 잘 표현한다고만 생각하였는데, 구체적으로 왜 이런 특성을 갖게 되는지, 그리고 모델의 각 레이어가 무엇을 학습하는지에 대해서 제대로 알 수 있게 되어 매우 의미가 있었습니다. 결국 데이터를 바탕으로 각 단어가 등장하는 상황을 학습하는 것인데 의미적, 구문적 정보를 구분하여 어떤 상황에서 무엇이 학습되는지를 구체적으로 연구하는 부분이 매우 흥미로웠습니다. 이를 바탕으로 다운스트림 태스크에서 어떤 문제를 해결하려고 하느냐에 따라서 사전 학습 모델을 어떻게 구성해야 할 지, 파인튜닝은 어떻게 수행해야 할 지에 대한 인사이트를 얻어간 것 같습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] A Neural Probabilistic Language Model [1] (1) | 2023.10.13 |
|---|---|
| [논문리뷰] emoji2vec: Learning Emoji Representations from their Description (0) | 2023.10.12 |
| [논문리뷰] Transformers: State-of-the-Art Natural Language Processing (1) | 2023.10.09 |
| [논문리뷰] Deep contextualized word representations (1) | 2023.10.08 |
| [논문리뷰] All-but-the-Top: Simple and Effective Postprocessing for Word Representations (1) | 2023.10.04 |




댓글