
최근 임베딩 관련한 논문을 계속해서 읽다가, paperswithcode에서 재미있는 논문을 발견하여 쉬어가는 느낌으로 읽고 정리해보았습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
1. Overview
이모티콘(emoji)은 1997에 처음 도입된 표준적으로 사용하는 작은 그림 문자의 집합입니다. 이모티콘은 지난 10년 동안 소셜 미디어에서 사용량이 급증했습니다. 옥스포드 사전은 2015년을 이모티콘의 해로 지정했으며, 한 해 동안 이모티콘 사용량이 800% 이상 증가하였다고 했습니다. 그리고 Face with Tears of Joy emoji 😂를 올해의 단어로 선정하였습니다. 논문이 발표될 당시 트위터(현재 X) 포스트의 10%, 인스타그램 게시글의 50% 이상에서 이모티콘이 사용되았다고 합니다. 이모티콘의 사용이 증가하면서 이는 공식적으로, 혹은 비공식적으로 언어와 사회 분야와 더불어 자연어 처리의 연구 주제가 되었습니다.
사회 과학 분야의 연구에서는 이모티콘을 모바일 플랫폼에서 감정 표현의 수단이라고 주로 해석하였습니다. Kelly와 Watts는 이 외에도 이모티콘이 유용한 소통 수단이라고 하였습니다. Lebduska는 이모티콘이 문화와 맥락에 의존하며, 때때로 재해석과 오해의 여지가 있다고 하였습니다.
더불어 소셜 미디어 데이터를 활용한 NLP 연구도 이전보다 활발히 이루어졌습니다. 이 연구는 주로 표현 학습(representation learning)과 단어 임베딩(word embeddings)에 의존합니다. 특히, $\texttt{word2vec}$이나 $\texttt{GloVe}$ 등을 활용한 사전 학습 단어 임베딩을 주로 활용합니다. 하지만 유니코드로 표현할 수 있는 모든 이모티콘을 포함한 연구는 없기 때문에, 이모티콘 표현(emoji representations)을 더하는 것으로 사회 분야의 NLP 응용에서 모델 성능 개선을 기대할 수 있을 것입니다.
논문에서는 이모티콘의 유니코드 심볼을 임베딩한 $\texttt{emoji2vec}$를 공개하였습니다. 트위터 감성분석 태스크를 통해 유용성을 입증하였고, 이모티콘 유추(emoji analogy)와 임베딩 공간에서 이모티콘 분포를 시각화하여 연구에 대해 정량적인 평가를 수행하였습니다.
2. Related Work
이모티콘 분산 표현에 대한 연구는 거의 없습니다. 첫 번째 연구는 인스타그램 데이터 팀의 블로그 포스트에서 비공식적으로 이루어졌습니다. 그들은 인스타그램 포스트를 스킵그램(skip-gram) 기반 알고리즘으로 학습하여 임베딩을 생성하였습니다. 두 번째 연구는 Barbieri에 의해 이루어졌으며, 대규모의 트위처 데이터셋에서 스킵 그램 기법으로 임베딩을 학습하였습니다. 이를 통해 유사도 측정 태스크에서 큰 성능 향상을 이뤄냈습니다. 하지만 자주 사용되지 않는 이모티콘에 대한 성능이 상당히 저조했습니다. 실제로 유니코드 표준에서는 1600개가 넘는 이모티콘이 존재하지만, Barbieri는 약 700개의 이모티콘만을 사용하였습니다.
논문의 연구는 두 가지 측면에서 기존 연구와 다릅니다. 먼저 이모티콘의 표현을 각 이모티콘에 대한 설명을 통해 학습하여 더욱 강건한 모델링이 가능할 뿐만 아니라, 자주 사용하지 않는 이모티콘(long tail of infrequently used ones)에 대한 임베딩도 학생성 가능합니다. 두 번째로 이 연구에서는 적은 데이터를 사용합니다. 수백만 개의 트윗을 사용하는 대신 몇 천개 되지 않는 설명문만을 사용하여 학습하지만, 트위터 감성 분석 태스크에서는 더 높은 정확도를 얻을 수 있었습니다.
Hill의 연구에서 사전의 설명에 포함된 단어나 개념을 통하여 단어 임베딩을 학습하였습니다. 이처럼 저자는 이모티콘에 대한 설명과 키워드를 통하여 임베딩을 생성합니다. 하지만 Park의 연구에서 문화나 언어에 따라 이모티콘이 갖는 의미가 달라질 수 있다는 점에서 이 연구가 갖는 한계도 존재함을 언급하였습니다. 논문에서는 영어를 사용하여 이모티콘을 정의하였기 때문에 이모티콘이 갖는 모든 의미적 특성을 포착하지는 못할 것이라고 하였습니다.
3. Method
논문에서는 $\texttt{word2vec}$ 임베딩과 같이 이모티콘 심볼을 300 차원 벡터에 매핑하여, $\texttt{emoji2vec}$가 $\texttt{word2vec}$에 더하여 함께 사용될 수 있도록 하였습니다. 이를 위해서 모티콘 심볼과 이름, 키워드를 유니코드 이모티콘 리스트에서 크롤링하였고, 결과적으로 1661개의 이모티콘 심볼과 6088개의 설명문(descriptions)을 수집하였습니다. 다음은 흔히 사용되지 않는 이모티콘의 예시입니다.

3.1 Model
이모티콘 임베딩은 간단한 기법을 통해 생성하였습니다. 이모티콘을 설명하는 문장의 단어 시퀀스 $w_1, \dots, w_N$가 주어졌을 때, 다음과 같이 $\texttt{word2vec}$ 임베딩을 통해 얻은 각 단어 벡터의 평균을 계산합니다.

여기서 $\textbf{\textit{v}}_j$는 이모티콘의 설명에 대한 벡터 표현입니다. 그리고 학습 데이터에서 각 이모티콘에 대하여 학습 가능한 벡터 $\textbf{\textit{x}}_i$를 정의하고, 이모티콘 표현 $\textbf{\textit{x}}_i$와 $\textbf{\textit{v}}_j$이 같아질 확률을 $\sigma(\boldsymbol{x}_i^T\boldsymbol v_j)$와 같이 모델링하였습니다. 학습을 위해서는 다음과 같은 손실을 사용하였습니다.

여기서 이모티콘에 대한 설명 $j$이 이모티콘 $i$와 잘 맞으면 $y_{ij}$는 1이고 그렇지 않으면 0이 대입됩니다.
3.2 Optimization
논문의 모델은 텐서플로로 구현되었고 SGD와 Adam을 사용하여 최적화 하였습니다. 일반화 성능을 향상하기 위하여 유효하지 않은 설명(invalid description)과 이모티콘을 짝지어 negative sample을 생성하였습니다. 그리고 양성 샘플과 음성 샘플의 비율을 하나의 파라미터로 사용하였는데, 실험을 통해 그 비율이 1:1일 때 가장 성능이 좋은 것을 확인하였습니다. 조기 종료(early-stopping) 기법을 사용하여 80 에포크동안 학습했을 때 가장 뛰어난 결과를 보였습니다. 재미있는 점은 2013 맥북 프로를 사용하여 학습하는 데 3분도 걸리지 않았다고 합니다.
4. Evaluation
emoji-description 분류와 Twitter sentiment analysis 태스크 모두를 사용하여 intrinsic, extrinsic 기법을 모두 사용하여 평가하였습니다. 보통 단어 임베딩을 평가할 때, intrinsic이라 하면 각 단어 임베딩이 자체적으로 갖는 의미를 평가하고, extrinsic은 주변 문맥을 고려하여 단어 임베딩이 어떤 역할을 수행하는지를 평가합니다.
4.1 Emoji-Description Classification
모델이 이모티콘의 설명에 대한 표현을 얼마나 잘 모델링하는지 분석하기 위하여, 저자는 이모티콘, 키워드, 레이블로 구성된 테스트 세트를 직접 구성하였습니다. 예를 들어 {😂, “crying”, True}, {😂, “fish”, False}와 같은 데이터가 사용되었습니다. 테스트 세트의 각 샘플에 대하여 $\sigma(\boldsymbol{x}_i^T\boldsymbol v_j)$를 계산하여, 이모티콘 벡터와 설명에 포함된 단어 벡터의 합에 대한 유사도를 비교하였습니다. 임곗값을 0.5로 설정하여, 그 이상일 경우 연관성이 있다고 분류하였을 때 85.5%의 정확도를 얻을 수 있었습니다. 임곗값을 다양하게 하여 다음과 같이 ROC 커브를 분석하였는데, AUC(area-under-the-curve)가 0.933인 것으로 보아 이모티콘 표현 학습이 잘 이루어졌음을 확인할 수 있습니다.

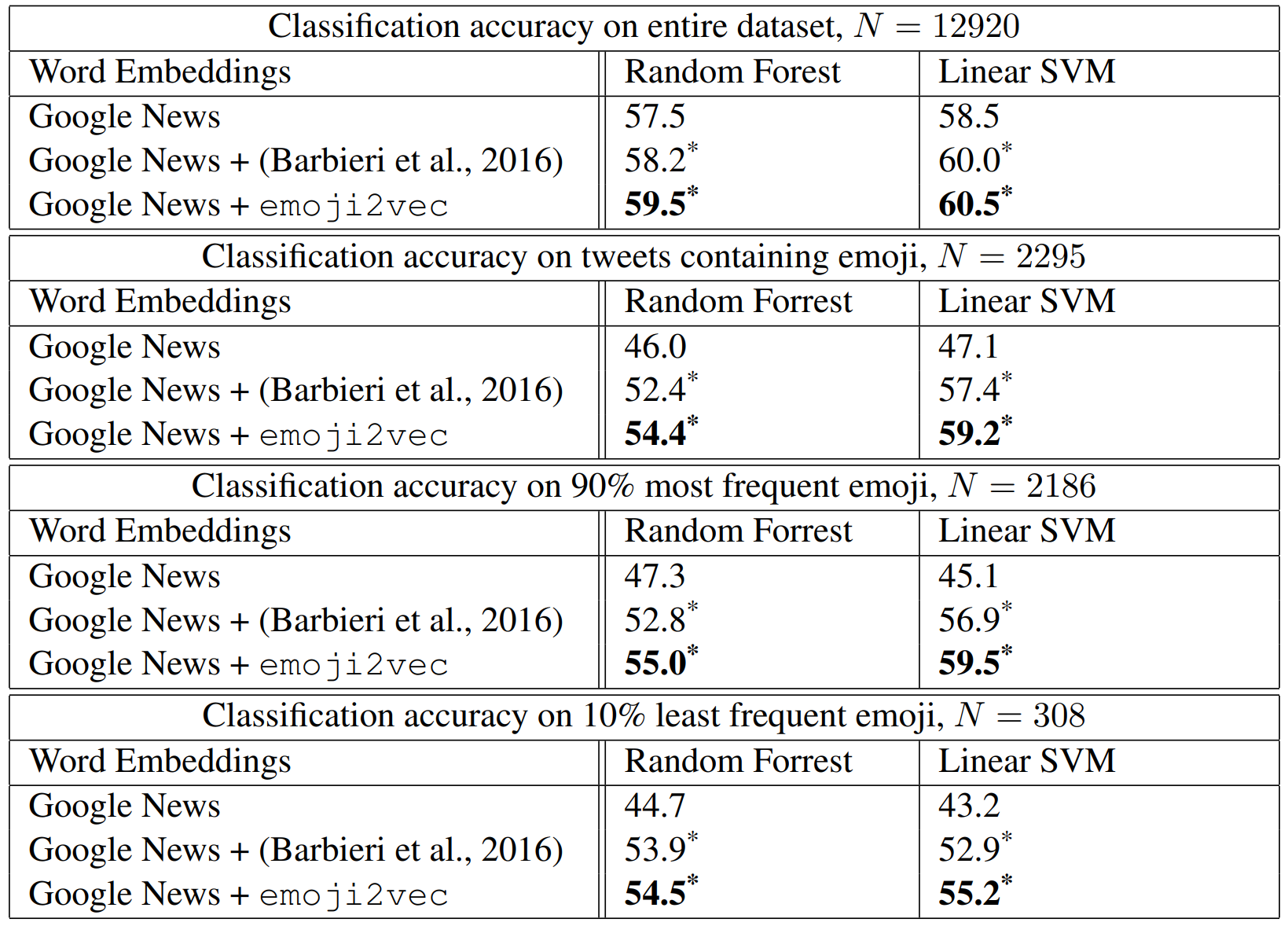
4.2 Sentiment Analysis on Tweets
$\texttt{word2vec}$과 Barbieri의 임베딩을 사용하여 증강된 $\texttt{word2vec}$을 논문의 모델과 비교하였고, 결과는 다음과 같습니다. 저자는 실험을 통해 이모티콘 임베딩이 다른 사회 NLP 태스크에서도 성능 향상에 도움이 될 것이라고 생각하였습니다. 또한 저자는 $\texttt{emoji2vec}$이 적은 데이터와 간단한 모델만으로 다른 기법보다 우수한 성능을 보임을 강조합니다.
4.3 t-SNE Visualization
저자는 또 다른 인사이트를 얻기 위해 t-SNE를 사용하여 이모티콘 임베딩을 2차원 공간으로 투영하였습니다. t-SNE는 샘플 간의 상대적인 거리를 보존하면서 고차원 임베딩을 저차원 공간으로 매핑하는 기법입니다. 다음 그림을 통해 몇 개의 클러스터가 이루어진 것을 볼 수 있습니다. 예를 들어 여러 국기들이 아래쪽에 모여있고, 웃는 얼굴들은 중앙에 모여있습니다. 반면에 숫자에 대한 이모티콘은 적절히 흩어져 있지 않은데, 이는 실험에서 사용된 간단한 모델의 한계를 보여줍니다.

4.4 Analogy Task
$\texttt{word2vec}$를 사용한 의미 유추는 이 임베딩의 잘 알려진 성질 중 하나입니다. 예를 들어 ‘왕’에 대한 벡터 표현에서 ‘남자’를 빼고 ‘여자’를 빼면 ‘여왕’의 벡터 표현과 유사해집니다. 단어 임베딩은 이런 방식으로 유추 태스크에서의 성능을 평가해왔습니다. 안타깝게도 이모티콘은 학습 데이터가 적기 때문에 이런 관계를 학습하기 어렵지만, 논문의 연구에서는 몇 가지 성공적인 학습 사레를 발견하였습니다. 다음과 같이 연산 수행 후 가장 가까운 이모티콘 5개를 선택하였을 때, 항상 첫 번째에 정답이 존재하진 않지만, 적어도 top 3안에는 포함되는 경우가 자주 있음을 발견하였습니다.

5. Conclusion
논문에서는 skip-gram 대신 간단한 모델을 사용하여 학습한 이모티콘 임베딩 $\texttt{emoji2vec}$를 제안하였습니다. 그리고 몇 가지 실험을 통해 사회 NLP 태스크에서 유용하게 사용될 가능성을 보였습니다. 학습에 적은 데이터와 간단한 모델이 사용되었다는 점에서 후속 연구를 통해 Emojipedia 텍스트 전체와 순환 신경망을 사용하면 더 뛰어난 성능을 보일 것임을 기대하였습니다. 추가 연구를 통해 문맥에 따라 이모티콘이 갖는 의미나 풍자 등의 언어적 현상을 학습하게 되면 한층 성능이 개선될 것이라고 언급하였습니다.
6. Further Thinking
연구 주체가 흥미로운 논문이었습니다. 예전에 ChatGPT와 같은 LLM에 몇 가지 이모티콘을 주고 영화 제목 맞추기 게임을 하는 게시글을 본 적이 있는 것 같은데, 그 내용이 생각나기도 했습니다. 논문에서 언급한 이모티콘 임베딩은 사회 분야의 NLP 문제를 풀 때 실제로 유용할 것이라는 생각에도 공감이 되었습니다. 다만 보통은 단어 벡터를 생성할 때 vocab size등을 고려하기 때문에 이모티콘에 대한 표현이 포함되지 않은 것이라고 생각합니다. Vocab size는 결국 모델이 학습해야 할 파라미터에 영향을 미치기 때문에 연산 등의 측면에서 이런 자주 사용되지 않는 문자는 어쩔 수 없이 제외했을 텐데, 이 연구가 단순히 이모티콘을 포함한 텍스트의 의미를 파악한다는 장점 외에 어떤 의미를 갖는지 의문이 생겼습니다. 분명 트윗 등의 social content의 의미 파악에는 도움이 되겠지만 그 과정에서 computational cost 등에서 손해를 볼 것 같은데 둘을 비교하였을 때도 충분히 의미가 있는지에 대한 연구가 존재하는지 알아봐야겠다는 생각이 들었습니다.
'Paper Review' 카테고리의 다른 글
| [논문리뷰] A Neural Probabilistic Language Model [2] (1) | 2023.10.14 |
|---|---|
| [논문리뷰] A Neural Probabilistic Language Model [1] (1) | 2023.10.13 |
| [논문리뷰] Linguistic Knowledge and Transferability of Contextual Representations (1) | 2023.10.09 |
| [논문리뷰] Transformers: State-of-the-Art Natural Language Processing (1) | 2023.10.09 |
| [논문리뷰] Deep contextualized word representations (1) | 2023.10.08 |




댓글