
엄밀히 말해서는 논문이라고 하기에는 부적절할 수 있지만 그래도 2020년 EMNLP에서 발표되고 Best Demonstration Paper를 수상한 논문 Transformers: State-of-the-Art Natural Language Processing에 대해 리뷰해보았습니다. 논문에서는 HuggingFace의 Transformers 라이브러리와 이를 바탕으로 이루어진 커뮤니티에 대하여 소개합니다. 이번 포스팅은 이전 논문 리뷰와는 다르게 추가적인 내용이나 개인적인 생각은 가급적 제외하고, 원문의 의미가 잘 전달될 수 있도록 번역에 집중하였습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 필요한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
Abstract
자연어 처리는 모델 아키텍처와 사전 학습의 발달 덕분에 크게 발전하였습니다. 트랜스포머는 규모가 큰 모델을 구축할 수 있게 해주었고 사전 학습을은 이런 모델을 다양한 태스크에 효과적으로 사용할 수 있게 해주었습니다. 트랜스포머(Transformers)는 이러한 발전을 머신러닝 커뮤니티에 널리 알리는 것을 목표로 하는 오픈소스 라이브러리입니다. 이 라이브러리는 통합 API를 기반으로 세심하게 설계된 최첨단 트랜스포머 아키텍처로 구성되어 있습니다. 이 라이브러리는 커뮤니티에서 만들어지고 사용가능한, 엄선된 사전 학습 모델로 뒷받침됩니다. Transformers는 연구자가 확장할 수 있도록, 실무자가 간편하게 사용할 수 있도록, 그리고 산업에서는 빠르고 강건한 모델을 배포할 수 있도록 설계되었습니다. 라이브러리는 다음 링크에서 에서 사용할 수 있습니다. https://github.com/huggingface/transformers
1. Introduction
트랜스포머는 자연어 이해와 자연어 생성 작업 모두에서 컨볼루션 및 순환 신경망과 같은 대체 신경망(alternate neural networks)을 능가하는 성능으로 자연어 처리를 위한 지배적인 아키텍처로 빠르게 자리 잡았습니다. 이 아키텍처는 학습 데이터와 모델 크기에 따라 확장 가능하고, 효율적인 병렬 학습을 수행할 수 있으며, 시퀀스의 장거리 특성(long-range sequence properties)을 포착할 수 있습니다.
모델 사전 학습은 모델을 일반적인 말뭉치로 훈련한 후 특정 작업에 쉽게 적용되어 강력한 성능을 보입니다. 트랜스포머 아키텍처는 특히 대규모 말뭉치에 대한 사전 학습에 도움이 되며, 텍스트 분류, 자연어 이해, 기계 번역, 상호참조 해결, 상식 추론, 요약을 포함한 여러 자연어 처리 태스크에서의 정확도를 크게 향상시킵니다.
자연어 처리 분야에서 이러한 발전은 트랜스포머 기반 모델이 널리 활용되기 위해 해결해야 할 다양한 실질적인 과제로 이어집니다. 트랜스포머가 어디에나 사용될 수 있도록 다양한 플랫폼에서 모델을 훈련, 분석, 확장 및 증강할 수 있는 시스템이 필요합니다. 이 아키텍처는 점점 더 정교한 확장과 정밀한 실험을 설계하기 위한 빌딩 블록으로 사용됩니다. 사전 학습이 널리 사용됨에 따라 커뮤니티에서 사용되는 핵심 사전 학습 모델을 배포, 파인튜닝, 압축해야 할 필요성이 강조됩니다.
Transformers 라이브러리는 트랜스포머 기반 아키텍처를 지원하고 사전 학습된 모델의 배포를 용이하게 하기 위하여 설계되었습니다. 이 라이브러리의 핵심은 연구와 생산 모두를 위해 설계된 트랜스포머를 구현하는 것입니다. 라이브러리의 철학은 읽기, 확장, 배포가 용이한 인기 있는 다양한 모델을 산업에서 사용할 수 있는 수준까지 구현을 지원하는 것입니다. 이러한 철학을 토대로 라이브러리는 중앙 집중된 모델 허브에서 사전 학습된 다양한 모델을 배포하고 사용할 수 있도록 지원합니다. 이 허브는 사용자가 동일한 최소화의 API로 여러 모델을 비교하고 다양한 작업에서 공유된 모델을 실험할 수 있도록 지원합니다.
Transformers는 400명 이상의 외부 기여자로 구성된 활발한 커뮤니티의 지원을 통해 허깅페이스(HuggingFace)의 엔지니어와 연구원 팀이 지속적으로 관리하는 프로젝트입니다. 라이브러리는 Apache 2.0 라이선스에 따라 배포되었고 GitHub에서 사용할 수 있습니다. 자세한 문서와 튜토리얼은 HuggingFace의 웹사이트에서 확인할 수 있습니다.
2. Related Work
자연어 처리와 머신러닝 커뮤니티는 오픈소스 연구 도구를 구축하는 바람직한 문화를 갖고 있습니다. Transformers의 구조는 Google Research의 선구적인 tensor2tensor 라이브러리와 BERT의 원본 소스 코드에서 영감을 얻었습니다. 사전 학습된 모델을 손쉽게 캐싱한다는 개념은 AllenNLP에서 유래하였습니다. 이 라이브러리는 Fairseq, OpenNMT, Texar, Megatron-LM과 Marian NMT 등의 신경망 번역 및 언어 모델링 시스템과 밀접한 관련이 있습니다. 이러한 요소를 기반으로 Transformers는 모델을 쉽게 다운로드, 캐싱 및 파인튜닝하고 프로덕션으로 원활하게 전환할 수 있도록 하는 사용자 친화적인 기능을 추가하였습니다. Transformers는 이러한 라이브러리와 일부 호환성을 유지하며, Marian NMT 및 Google의 BERT를 사용하여 추론을 수행하는 도구를 직접적으로 포함합니다.
범용 NLP를 위한 사용하기 쉬운 사용자 친화적인 라이브러리의 역사는 오래되었습니다. NLTK Loper와 Bird는 두 가지 핵심 라이브러리로, NLP에 대한 다양한 접근 방식을 하나의 패키지로 엮었습니다. 최근에는 Spacy와 AllenNLP, flair를 포함한 범용 오픈소스 라이브러리가 다양한 NLP 작업을 위한 머신 러닝에 주로 초점을 맞추고 있습니다. Transformers는 이러한 라이브러리와 유사한 기능을 제공하며, 또한 앞서 언급한 라이브러리는 Transformers와 모델 허브를 저수준(low-level) 프레임워크로 사용합니다.
Transformers는 NLP 모델을 위한 허브를 제공하기 때문에, 사용자가 프레임워크별 모델 매개변수를 쉽게 사용할 수 있도록 수집하는 Torch Hub 및 TensorFlow Hub와 같은 인기 있는 모델 허브와도 관련이 있습니다. 하지만 이러한 허브와 달리 Transformers는 도메인에 특화되어 있어 시스템에서 모델 분석, 사용, 배포, 벤치마킹 및 손쉬운 복제를 자동으로 지원할 수 있습니다.
3. Library Design
Transformers는 데이터 처리, 모델 적용, 예측 생성 등 표준 NLP 머신 러닝 모델 파이프라인을 반영하도록 설계되었습니다. 라이브러리에는 훈련과 개발을 용이하게 하는 도구가 포함되어 있지만, 이 기술 보고서는 모델링에 대한 핵심적인 정보(core modeling specification)에 중점을 두고 있습니다. 라이브러리의 기능에 대한 자세한 내용은 다음 링크에서 제공되는 설명서를 참조하세요. https://huggingface.co/transformers/
라이브러리의 모든 모델은 그림의 다이어그램에 표시된 세 가지 빌딩 블록으로 정의됩니다. (a) 원본 텍스트를 희소 인덱스 인코딩(sparse index encodings)으로 변환하는 토크나이저(tokenizer), (b) 희소 인덱스를 contextual embeddings로 변환하는 트랜스포머(transformer), (c) contextual embeddings를 사용하여 작업별 예측을 수행하는 헤드(head)입니다. 이 세 가지 구성 요소로 대부분의 사용자 요구 사항을 해결할 수 있습니다.
각 모델은 고정된 헤드로 사전 학습되었고, 이후 각 태스크에 대해 다른 헤드를 사용하여 파인튜닝을 수행할 수 있습니다. 각 모델은 Python 또는 Rust로 구현된 토크나이저를 사용합니다. 자세한 부분은 조금씩 다르지만 사전 학습에 사용한 것과 같은 토크나이저를 사용해야 합니다. 헤드는 트랜스포머를 다양한 태스크에 사용할 수 있게 해줍니다. 여기서 입력 토큰 시퀀스는 x1:N는 어휘사전 V에서 유래하였고, y는 클래스 집합 C 내의 서로 다른 가능한 출력을 의미합니다.
Transformers
라이브러리의 중심에는 세심한 테스트를 거쳐 구현한 트랜스포머 아키텍처의 다양한 버전이 있습니다. 현재 구현된 아키텍처의 전체 목록은 그림의 왼쪽에 나와 있습니다. 각 아키텍처는 동일한 멀티헤드 어텐션 코어를 공유하지만, 위치 표현(positional representations), 마스킹, 패딩, sequence-to-sequence 설계 등에서 차이가 있습니다. 또한 자연어 이해, 생성, 조건부 생성과 같은 여러 NLP 애플리케이션과 더불어 빠른 추론과 다국어 응용과 같은 특별한 사용 사례를 위한 다양한 모델들이 구축되어 있습니다.
특히 모든 모델은 다음과 같이 같은 추상화 계층을 갖습니다. 베이스 클래스는 일련의 셀프 어텐션 레이어에서부터 마지막 인코더의 은닉 상태를 거쳐 생성한 인코딩(임베딩 행렬로의 투영)으로부터 모델의 연산 그래프를 구현합니다. 베이스 클래스는 각 모델에 특화되어 있으며 모델의 원본 구현을 따르기 때문에 사용자가 각 개별 아키텍처의 작동 원리를 쉽게 분석할 수 있는 유연성을 제공합니다. 대부분의 경우 각 모델은 쉬운 확장성을 위하여 단일 파일로 구현됩니다.
대부분의 경우 서로 다른 아키텍처가 동일한 API 클래스를 따르기 때문에 사용자는 서로 다른 모델 간 쉽게 전환할 수 있습니다. Auto 클래스는 모델 간, 심지어 프레임워크 간에도 매우 빠르게 전환할 수 있는 통합 API를 제공합니다. 이러한 클래스는 사용자가 지정한 사전 학습된 모델에 지정된 구성(configuration)으로 자동으로 인스턴스화됩니다.
Tokenizers
모델 사용에 필수적인 토크나이저의 구현은 NLP에 특화된 라이브러리의 핵심적인 특징입니다. 공통된 베이스 클래스에서 상속한 토크나이저 클래스는 그에 대응하는 사전학습된 모델에 의해 인스턴스화하거나 수동으로 구성할 수 있습니다. 이러한 클래스는 대응하는 모델에 대한 어휘 토큰-인덱스 맵을 저장하고 모델의 특정 토큰화 프로세스에 따라 입력 시퀀스의 인코딩과 디코딩을 처리합니다. 구현된 토크나이저는 그림의 오른쪽에서 나와 있습니다. 사용자는 인터페이스를 통해 토크나이저를 손쉽게 수정하여 추가적인 토큰 매핑, 특수 토큰(예를 들어 분류 또는 분리를 위한 토큰)을 추가하거나 어휘사전(vocabulary)의 크기를 조정할 수 있습니다.
토크나이저를 사용하여 유용한 기능을 추가로 구현할 수도 있습니다. 추가 기능은 시퀀스 분류에서의 token type indices부터 모델별 특수 토큰을 고려하여 시퀀스의 최대 길이로 자르기(maximum length sequence truncating)에 이르기까지 다양합니다.
매우 큰 데이터셋에 대하여 훈련할 경우, Python 기반 토큰화는 매우 느릴 때가 있습니다. 가장 최근 릴리스에서는 기본적으로 고도로 최적화된 토큰화 라이브러리를 사용하도록 구현 방식을 변경하였습니다. 다음에서 제공되는 이 저수준 라이브러리는 Rust로 작성되어 학습 및 배포 시 토큰화 프로세스의 속도를 향상합니다. https://github.com/huggingface/tokenizers
Heads
각 트랜스포머는 일반적인 작업에 적합한 출력을 제공하는 여러 개의 사전에 구현된 헤드와 쌍을 이룹니다. 이러한 헤드는 베이스 클래스 위에 추가적인 래퍼 클래스로 구현되며, 트랜스포머의 문맥 임베딩(contextual embeddings) 위에 특정 출력 레이어와 손실 함수를 선택적으로 추가합니다. 구현된 전체 헤드들은 그림의 위쪽에 나와 있습니다. 이러한 클래스는 비슷한 다음과 같이 비슷한 패턴으로 명명됩니다. XXXForSequenceClassification에서 XXX는 모델의 이름이며 파인튜닝 또는 사전 학습에 사용할 수 있습니다. 조건부 생성과 같은 일부 헤드는 샘플링과 빔 서치(beam search)와 같은 추가적인 기능을 지원합니다.
사전 학습된 모델의 경우, 모델 자체의 사전 학습에 사용된 헤드를 배포하였습니다. 예를 들어 BERT는 언어 모델링(language modeling)과 다음 문장 예측(next sentence prediction) 헤드를 제공하여 사전 학습 목표(pretraining objectives)를 사용하여 쉽게 적용할 수 있습니다. 또한 사용자가 다양한 다른 헤드와 함께 트랜스포머의 핵심 파라미터를 사용하여 파인튜닝할 수 있도록 지원합니다. 각 헤드는 일반적으로 사용할 수 있지만 실제 문제에 적용할 수 있는 헤드가 무엇인지에 대한 예제도 제공됩니다. 이러한 예는 사전 학습된 모델을 특정 헤드에 적용하여 다양한 NLP 작업에서 최고(state-of-the-art)의 결과를 얻을 수 있는 방법을 안내합니다.
4. Community Model Hub
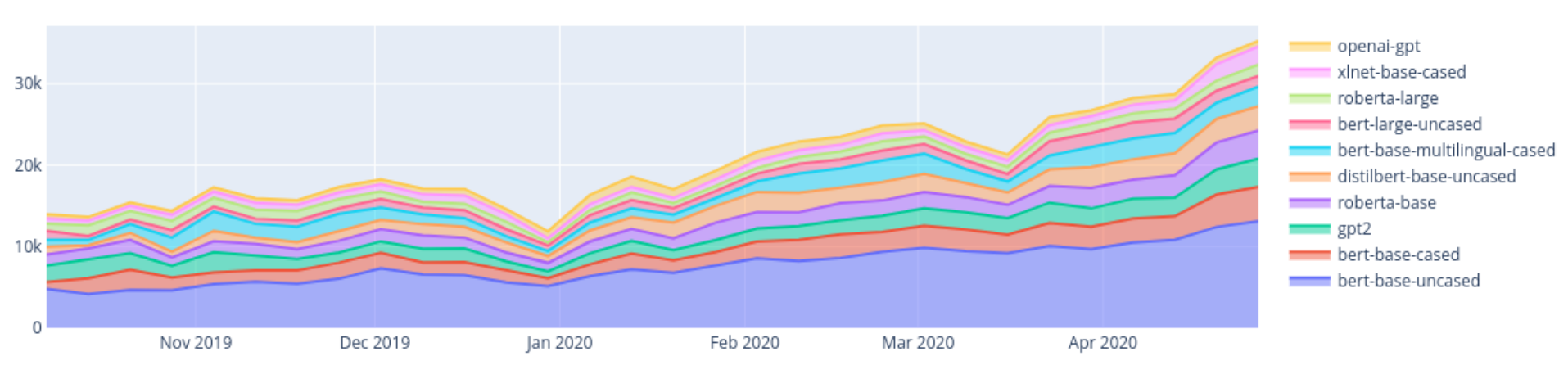
Transformers는 사전 학습된 모델의 쉬운 사용과 배포를 목표로 합니다. 이는 본질적으로 커뮤니티의 프로세스로 하나의 사전 학습된 모델만으로 여러 작업에 대한 파인튜닝을 용이하게 합니다. Model Hub는 모든 사용자가 자신의 데이터에 적합한 모델에 간편하게 접근할 수 있게 해줍니다. 이 허브에는 사전 학습 및 파인 튜닝된 2,097개의 사용자 모델이 포함되어 있습니다. 다음 그림은 시간에 따른 인기 있는 트랜스포머 모델의 다운로드 수를 보여줍니다. BERT, GPT-2와 같은 핵심 모델이 계속 인기를 끌고 있는 가운데, 라이브러리를 위해 특별히 개발된 DistilBERT를 비롯한 다른 모델도 커뮤니티에서 많이 다운로드되고 있습니다.
모델 허브의 인터페이스는 간단하고 커뮤니티에 개방되도록 설계되었습니다. 누구나 계정을 생성하고 명령줄 인터페이스를 사용하여 토크나이저, 트랜스포머, 헤드로 구성된 저장소를 생성하고 모델을 업로드할 수 있습니다. 이 번들은 라이브러리를 통해 학습된 모델일 수도 있고 다른 인기 있는 프레임워크의 체크포인트에서 변환한 모델일 수도 있습니다. 이런 모델은 허브에 저장되어 사용자가 두 줄의 코드를 통해 파인튜닝 및 추론을 위해 모델을 다운로드하고, 캐싱 및 실행에 사용되는 이름이 지정됩니다. 예를 들어 프랑스어 훈련 말뭉치에 대해 사전 학습된 BERT 모델인 FlauBERT는 다음과 같이 로드할 수 있습니다.
tknzr = AutoTokenizer.from_pretrained( "flaubert/flaubert_base_uncased") model = AutoModel.from_pretrained( "flaubert/flaubert_base_uncased")
모델이 모델 허브에 업로드되면 해당 모델의 핵심 속성, 아키텍처 및 사용 사례를 설명하는 랜딩 페이지가 자동으로 제공됩니다. 학습의 속성, 연구 인용, 사전 학습에 사용된 데이터셋, 모델과 모델의 예측에 대해 알려진 편항에 대한 주의 사항을 설명하는 모델 카드를 통해 추가적인 메타데이터를 제공할 수 있습니다. 모델 카드의 예는 다음 그림과 같습니다.
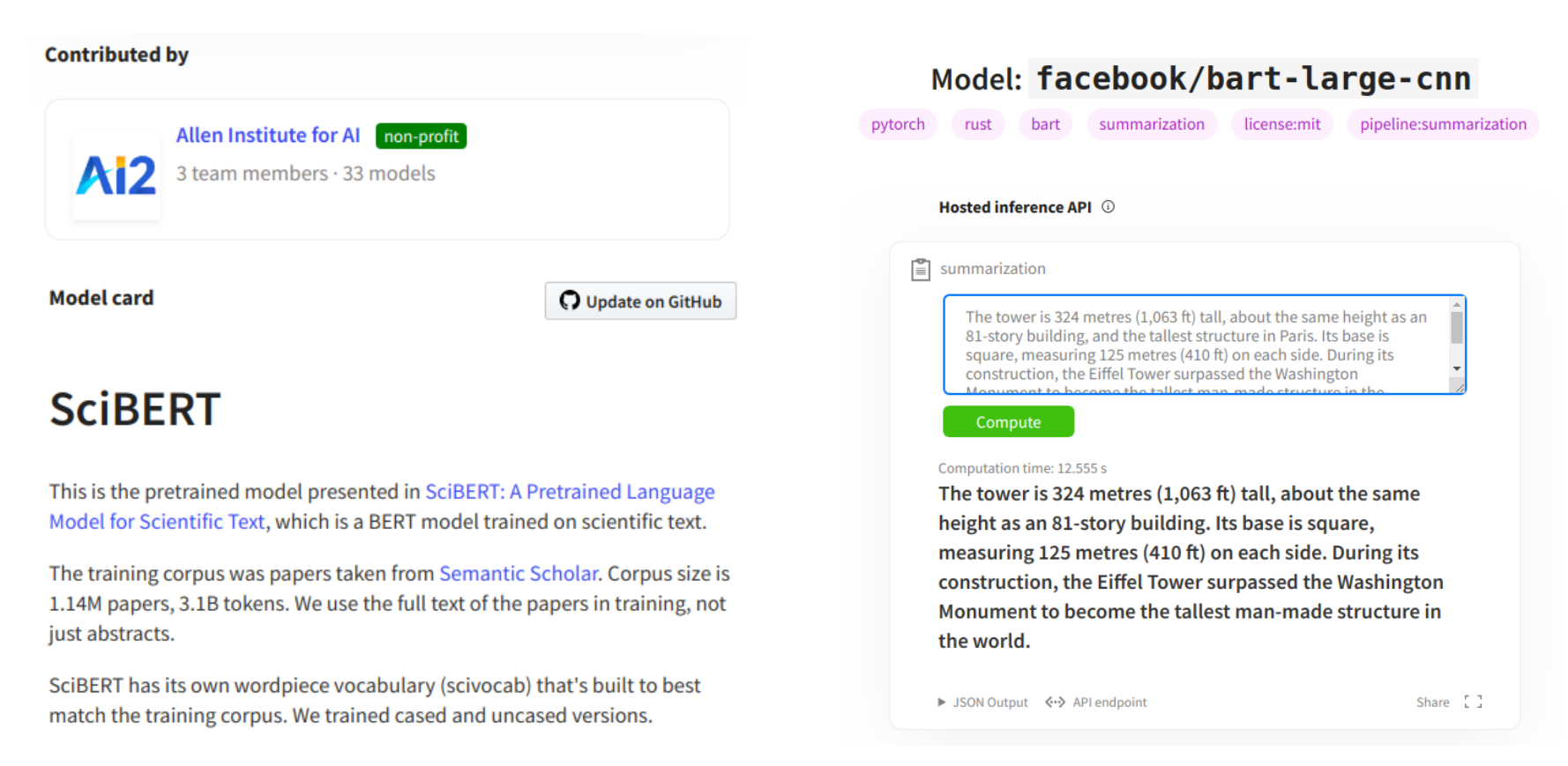
모델 허브는 트랜스포머 기반 모델에 특화되어 있기 때문에 일반적인 모델 컬렉션으로는 어려운 사용 사례를 타겟으로 할 수 있습니다. 예를 들어 업로드된 각 모델에는 모델 구조에 대한 메타데이터가 포함되므로, 사용자는 모델 페이지에서 실제 데이터를 사용하여 모델 출력을 실험하는 라이브 추론 기능을 사용할 수 있습니다. 그림의 오른쪽에서는 라이브 추론이 포함된 모델 페이지의 예시를 볼 수 있습니다. 또한 모델 페이지에는 벤치마킹 및 시각화와 같은 다른 모델별 도구에 대한 링크를 포함합니다. 예를 들어 모델 페이지는 트랜스포머 시각화 라이브러리인 exBERT로 연결될 수 있습니다.
CommunityCase Studies
모델 허브에서는 다양한 커뮤니티 관계자들이 Transformers를 어떻게 사용하는지 살펴보고, 실제로 관찰된 세 가지 구체적인 사용 사례를 요약하였씁니다. 설계자, 트레이너, 최종 사용자를 구분하여 각기 다른 목표를 가진 사용자가 개발한 특정 시스템을 살펴보겠습니다.
Case1: Model Architects
주요 NLP 연구소인 AllenAI는 의생명과학 텍스트에서 추출한 텍스트로 사전학습된 모델인 SciBERT를 개발하였습니다. 이들은 PubMed의 데이터를 활용하여 모델을 훈련하여 최고 수준의 성능을 제공하는 마스크드 언어 모델(Maksed Lanugage Model)을 생성하였습니다. 그 후 모델 허브에 이 모델을 배포하고 CORD - COVID 19 챌린지의 일부로 이를 홍보하여 커뮤니티가 사용할 수 있도록 하였습니다.
Case2: Task Trainers
뉴욕대학교(NYU)의 연구원들은 다양한 의미 식별 태스크(semantic recognition tasks)에서 Transformers*의 성능을 시험할 수 있는 테스트 베드를 개발하는 데 관심이 있었습니다. 이들이 개발한 Jiant 프레임워크는 모델을 사전 훈련하고 그 결과를 비교하는 다양한 방법을 제공합니다. 이들은 *Transformers API를 일반적인 프론트엔드로 사용하고 다양한 모델에 대한 파인튜닝을 수행하여 BERT의 구조에 대한 연구를 주도하였습니다.
Case3: Application Users
사용자 대시보드 및 분석에 중점을 둔 회사인 Plot.ly는 자동 문서 요약 모델을 배포하는 데 관심이 있었습니다. 확장성이 뛰어나고 배포가 간단하면서 추가로 훈련하거나 파인 튜닝할 필요가 없는 모델을 원했습니다. 그들은 모델 허브에서 정확하고 빠른 추론을 위해 설계된 사전 학습 및 파인 튜닝이 수행된 요약 모델인 DistlBART를 찾을 수 있었습니다. 그들은 ML에 대한 전문 지식이나 연구 없이도 허브에서 바로 모델을 실행하고 배포할 수 있었습니다.
5. Deployment
Transformers의 주요한 목표는 모델을 프로덕션을 위해 효율적으로 배포할 수 있도록 하는 것입니다. 사용자마다 프로덕션에 대한 요구 사항이 다르기 때문에 배포에는 훈련과는 많은 부분에서 다른 문제를 해결해야 하는 경우가 있씁니다. 따라서 라이브러리를 통해 프로덕션 배포를 위한 다양한 전략을 사용할 수 있습니다.
라이브러리의 핵심 특징 중 하나는 PyTorch와 TensorFlow 모두에서 모델을 사용할 수 있으며, 두 프레임워크 간에 상호 운용이 가능하다는 것입니다. 한 프레임워크에서 학습된 모델은 표준 직렬화(standard serialization)을 통해 저장되며, 다른 프레임워크에서 이를 원활하게 로드할 수 있습니다. 따라서 학습과 서빙 등 모델 사용에 따라 다른 프레임워크로 전환하는 것이 쉽습니다.
각 프레임워크에는 배포 권장 사항이 있습니다. 예를 들어 PyTorch에서 모델은 PyTorch 모델의 중간 표현(intermediate representation)인 TorchScript와 호환되며, 이를 통해 Python에서 보다 효율적으로 실행하거나 C++와 같은 고성능 환경에서 실행할 수 있습니다. 파인튜닝된 모델을 프로덕션 환경으로 내보내고 TorchServing을 통해 실행할 수도 있습니다. TensorFlow 생태계에는 여러 가지 서빙 옵션이 포함되어 있기 때문에, 이를 직접 사용할 수 있습니다.
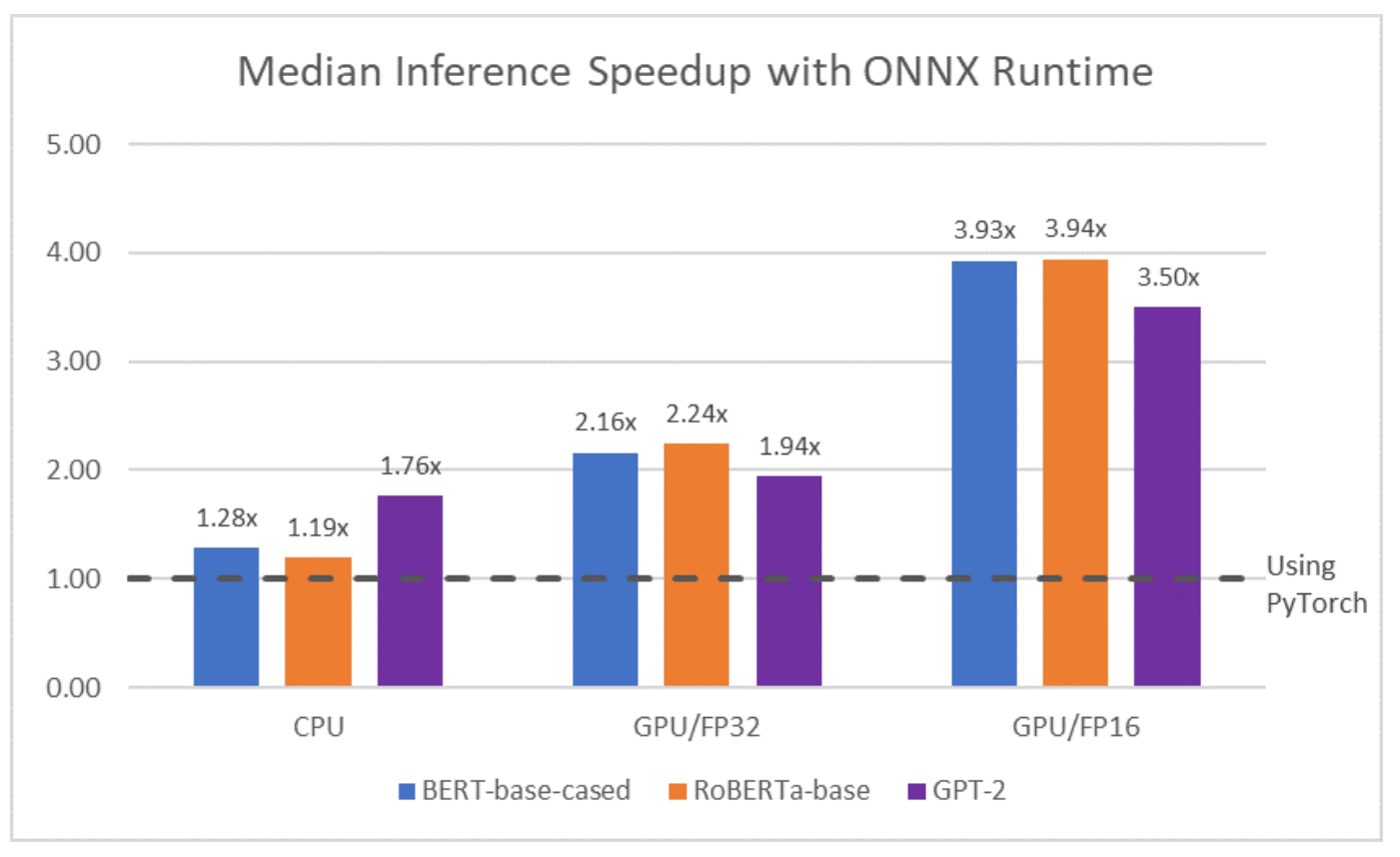
Transformers는 추가 편집(compilation)을 위해 모델을 중간 신경망 형식(intermediate network formats)으로 내보낼 수도 있습니다. 배포를 위해 모델을 ONXX(Open Neural Network Exchange) 형식으로 변환하는 기능도 제공합니다. 이를 통해 모델을 표준화된 상호 운용 가능한(standard interoperable) 형식으로 실행할 수 있을 뿐만 아니라 속도도 크게 향상됩니다. 다음 그림은 트랜스포머 라이브러리에서 BERT, RoBERTa, GPT-2를 최적화하기 위해 ONNX와 협력하여 수행한 실험을 보여줍니다. 이 중간 형식을 사용하여 ONNX는 모델의 속도를 거의 4배 향상할 수 있었습니다. 이 팀은 또한 JAX/XLA 및 TVM과 같은 다른 유망한 중간 형식에 대한 실험을 진행하고 있습니다.
트랜스포머가 모든 NLP 애플리케이션에 널리 사용됨에 따라 휴대폰이나 가전제품과 같은 엣지 디바이스에 배포하는 것이 점점 더 중요해지고 있습니다. 사용자는 어댑터(adapters)를 사용하여 모델을 iOS 애플리케이션에 임베드하기에 적합한 CoreML 가중치로 변환하여 on-the-edge 머신러닝을 활용할 수 있습니다.
6. Conclusion
트랜스포머와 사전 학습은 NLP에서 중요한 역할을 하므로 연구자와 사용자가 이런 모델에 쉽게 접근할 수 있어야 합니다. Transformers는 사용자가 사전 학습된 대규모 모델에 쉽게 접근하고, 이를 기반으로 모델을 구축하고 실험하며, 최고의 성능으로 다운스트림 태스크에 배포할 수 있도록 설계된 오픈소스 라이브러리이자 커뮤니티입니다. Transformers는 출시 이후 큰 인기를 얻고 있으며, 핵심 인프라를 지속적으로 제공하며 새로운 모델에 대한 접근을 용이하게 할 수 있도록 합니다.
Reflection
자연어 처리 문제를 해결하기 위해할 때 반드시 사용하게 되는 HuggingFace의 Transformers 라이브러리에 대한 논문을 리뷰하였습니다. 논문에서는 자연어 처리 태스크를 수행하는 모델의 성능을 향상하는 데 핵심적인 역할을 한 트랜스포머 아키텍처와 이를 기반으로 한 라이브러리, 관련 커뮤니티에 대해 소개합니다. 8월에 시작한 오픈소스 컨트리뷰션 아카데미의 HuggingFace 한글화 프로젝트가 그저께 마무리되었는데, 이를 기념하여 이 논문을 읽게 되었습니다. 사실 이런 논문이 있다는 것도 우연히 알게 되었는데, 담긴 내용이 흥미로웠고 프로젝트를 통해 허깅페이스에 관심을 갖게 되어 한번 읽어보았습니다. 최근에는 허깅페이스가 자연어 처리를 넘어서 인공지능 분야의 핵심적인 오픈소스 커뮤니티가 되었습니다. 그런 허깅페이스와 여기서 발표한 Transformers 라이브러리의 유래에 대해서 간단하게 알 수 있는 의미있는 글이었습니다.




댓글