
리뷰 순서는 논문의 목차를 따릅니다. 해석이 잘못 되었거나, 오개념이 있다면 댓글로 지적해주시면 감사하겠습니다. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다. 중간에 부연 설명이 필요한 경우 [1]과 같이 표기한 후, 각 섹션의 마지막 부분에서 구체적인 내용을 추가로 작성하였습니다. Abstract를 포함한 일부 섹션은 최대한 모든 내용을 담으려고 하였고, 이외 일부 섹션은 요약과 생략이 되었을 수 있습니다.
Abstract
Attentional 메커니즘은 번역 과정에서 source sentence의 일부에 선택적으로 집중하며 NMT를 개선하기 위해서 사용됩니다. 하지만 attention에 기반한 NMT를 위한 아키텍처에 대한 연구는 거의 없습니다. 논문에서는 두 가지 간단하고 효과적인 attentional 메커니즘에 대해 연구하는데, 각각 항상 모든 source words에 집중하는 global 접근법과 한 번에 source words의 부분집합(subset)에만 집중하는 local 접근법입니다. 논문에서는 두 접근법 모두에 대해, WMT의 영어-독일어 양방향 번역 태스크에서의 효과를 입증하였습니다. Local attention을 사용하여, attention은 사용하지 않았지만, dropout 등 이미 알려진 기법들을 적용한 system에 비해 BLEU points를 5.0점이나 향상시켰습니다. 서로 다른 attention 아키텍처를 적용한 앙상블 모델은 영어를 독일어로 번역하는 WMT'15 태스크에서 25.9 BLEU points로 SOTA result를 달성하였습니다. 이는 NMT와 $n$-gram reranker를 사용한 기존 최고의 시스템보다 BLEU points가 1.0점 앞선 결과입니다.
1. Introduction
Neural Machine Translation(NMT)는 대규모의 번역 작업에서 최고(state-of-the-art)의 성능을 보여줍니다. NMT는 최소한의 도메인 지식을 요구하고, 개념이 간단하다는 점에서 매력적입니다. Loung등의 모델은 <eos> 심볼에 도달할 때까지 source 단어를 읽고, target 단어를 한 번에 하나씩 내어 놓습니다.
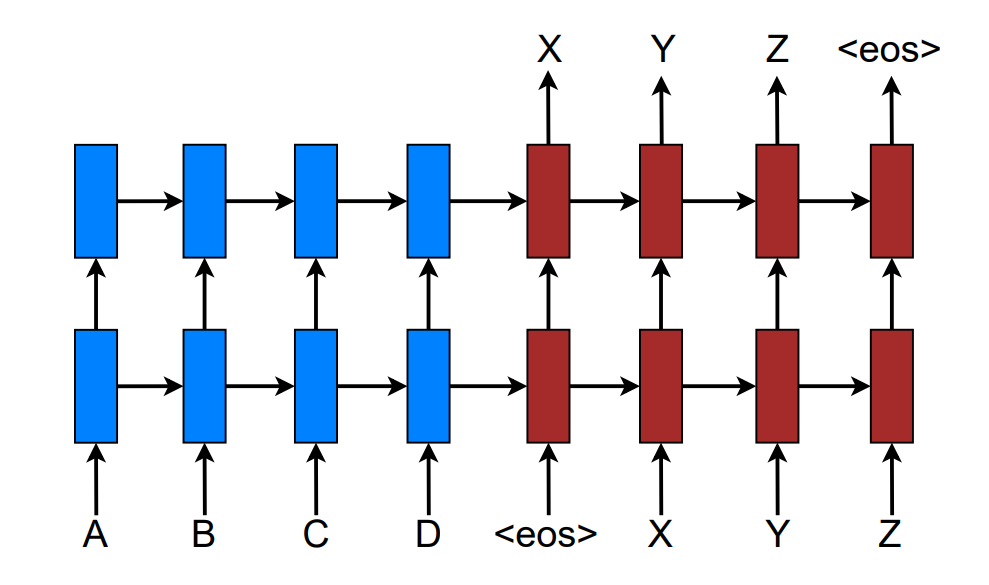
NMT는 주로 end-to-end 방식[1]으로 학습되었고, 매우 긴 시퀀스에 대해서도 일반화가 잘 되는 능력을 갖습니다. 따라서 전통적인 기계번역에서와 다르게, 모델에 거대한 phrase table(사전)과 언어 모델을 저장할 필요가 없습니다. 즉, NMT는 메모리 사용량이 적습니다. 게다가, NMT 디코더는 standard MT와 다르게 구현하기도 매우 쉽습니다.
더불어 최근에 인기를 얻은 attention이라는 개념 덕분에, 모델은 서로 다른 양식(modality)에 대한 alignments도 학습할 수 있습니다. 음성 인식 태스크에서의 음성과 텍스트, 이미지 캡셔닝에서의 이미지와 텍스트 설명이 그 예시입니다. Bahdanau 등은 attentional 메커니즘을 적용하여 단어를 번역하고 정렬하였습니다. 그러나 attention을 기반으로 한 아키텍처를 사용한 NMT에 대한 그 외의 연구는 없었고, 논문에서는 global과 local의 두 가지 새롭고 참신한 접근법을 설계하였습니다. Global approach는 Bahdanau 등의 모델과 유사하지만, 아키텍처가 더욱 단순합니다. Local approach는 hard와 soft attention을 섞은 Xu 등의 모델과 유사하지만, soft attention보다 연산량이 적고 hard attention의 미분 불가능 문제를 거의 해결하여 구현이 더욱 쉽습니다. 추가로, 논문에서는 attention에 기반한 모델에 사용되는 다양한 alignment functions를 연구하였습니다. 실험을 통하여 두 가지 접근법이 모두 효과적임을 WMT 영어-독일어 양방향 번역 태스크를 통해 입증하였습니다.
2. Neural Machine Translation
NMT 시스템은 입력 $x$와 출력 $y$에 대하여 조건부 확률 $p(y|x)$를 모델링하는 인공 신경망입니다. NMT의 기본적인 형태는 각 source 문장에 대한 표현인 $\boldsymbol s$를 계산하는 encoder와 한 번에 하나의 target 단어를 생성하는 decoder로 구성됩니다. 즉, 디코더는 다음 수식을 따라 decoding을 수행합니다.
$$ \log p(y|x) = \sum_{j=1}^m \log p(y_j|y_{<j}, \boldsymbol{s}) $$
Decoder 설계에 RNN을 사용하는 것은 자연스러운 선택입니다. 구체적으로, 각 단어는 다음과 같이 디코딩합니다.
$$ p(y_j|y_{<j},\boldsymbol s)= \textrm{softmax}(g(\boldsymbol{h}_j))$$
$g$는 vocabulary-sized bector로 변환하는 함수이고, $\boldsymbol{h}_j$는 다음과 같이 계산되는 RNN의 hidden unit 입니다.
$$ \boldsymbol{h}_j=f(\boldsymbol {h}_{j-1},\boldsymbol {s}) $$
$f$는 이전 단계의 hidden state를 통해 다음 단계의 hidden state를 계산하는 함수입니다. 단계적으로 요약하면, 이전 단계의 hidden state와 source 문장이 입력되면, 다음 단계의 hidden state가 계산됩니다. 그리고 계산된 hidden state는 $g$에 의해 변환되고, softmax 연산을 통해 어떤 확률과 같은 값이 됩니다. 이 값은 $j$번째 단계 이전의 예측값들과 source 문장이 주어졌을 때 $j$번째의 target word가 생성될 확률에 해당합니다.
논문에서는 stacking LSTM을 사용하였는데, 목표는 training corpus $\mathbb {D}$에 대해 다음 함수를 모델링 하는 것입니다.
$$ J_t = \sum_{(x,y~\in~\mathbb D)}-\log p(y|x) $$
3. Attention based Models
논문에서 attention-based model는 global과 local의 두 개의 대분류로 구분됩니다. 차이점은 attention이 모든 source position에 적용될 것인지, source position의 일부에 적용될 것인지에 따릅니다.
공통적으로 디코딩 단계에서 각 time step $t$에 대하여, stacking LSTM의 최상층에서 이전 time step의 hidden state $\boldsymbol{h}_t$를 입력으로 받습니다. 그리고 이를 바탕으로 다음 time step의 예측값인 $y_t$를 계산하는데 필요한 정보를 잘 담고 있는 context vector $\boldsymbol{c}_t$를 계산합니다. 두 벡터를 연결하여 다음과 같이 attentional hidden state를 만듭니다.
$$ \tilde{\boldsymbol{h}}_t = \tanh(\boldsymbol{W}_c[\boldsymbol{c}_t;\boldsymbol{h}_t]) $$
그리고 이 $ \tilde{\boldsymbol{h}}_t $는 softmax 층을 통과하여 다음과 같은 predictive distribution을 형성합니다.
$$ p(y_t|y_{<x},x)=\textrm{softmax}(\boldsymbol{W}_{\boldsymbol{s}}\tilde{\boldsymbol{h}}_t) $$
3.1 Global Attention
Global attention model의 핵심은 context vector를 유도할 때, encoder의 모든 hidden states를 고려하는 것입니다. Global 모델에서는 가변적인 길이(source side의 time step과 같은 길이)의 alignment vector인 $\boldsymbol{\alpha}_t$를 현재의 target hidden state와 각 source hidden state인 $\bar{\boldsymbol{h}}_s$를 비교하여 계산합니다.
$$ \begin{align*} \boldsymbol{\alpha}_t(s) &=\textrm{align}(\boldsymbol{h}_t,\bar{\boldsymbol{h}}_s) \\ &= {\exp \left( \textrm{score}( \boldsymbol{h}_t, \bar{\boldsymbol{h}})\right) \over{ \sum_{s'}\exp \left( \textrm{score}( \boldsymbol{h}_t, \bar{\boldsymbol{h}})\right)}} \end{align*} $$
score 함수는 content-based function이라고 부르며, dot, general, concat의 세 가지 방법으로 계산합니다. 처음에는 다음과 같은 location 방식으로 alignment vector를 계산하였습니다. alignment vector가 가중치로 주어지면 context vector는 모든 source hidden states에 대한 가중 평균으로 계산됩니다.
$$ \boldsymbol{\alpha}_t=\textrm{softmax}(\boldsymbol{W}_{\boldsymbol{\alpha}}\boldsymbol{h}_t)~~~~~~~~~~~location $$

Global attention 접근법인 Bahdananu의 모델과 비슷하지만, 몇 가지 차이점이 있습니다. 우선 encoder와 decoder 모두에서 top LSTM layers의 hidden state만을 사용하였습니다. 반면에 Bahdananu는 양방향의 hidden states를 concat하여 사용하였습니다. 두 번째로 논문에서의 제시한 방식이 더 간단한데, 논문에서는 $ \boldsymbol{h}_t \rightarrow \boldsymbol{ \alpha}_t \rightarrow \boldsymbol{c}_t \rightarrow \tilde {\boldsymbol{h}}_t $를 거쳐서 확률분포를 통해 예측값을 생성하지만, Bahdanau는 $\boldsymbol{h}_{t-1} \rightarrow \boldsymbol{\alpha}_t \rightarrow \boldsymbol{c}_t \rightarrow {\boldsymbol{h}}_t$를 거친 후, deep-output과 maxout layer까지 거쳐서 예측값을 생성합니다. 마지막으로 논문에서는 concat 뿐만 아니라 다른 방식도 사용하여 alignment 함수를 구현합니다.
3.2 Local Attention
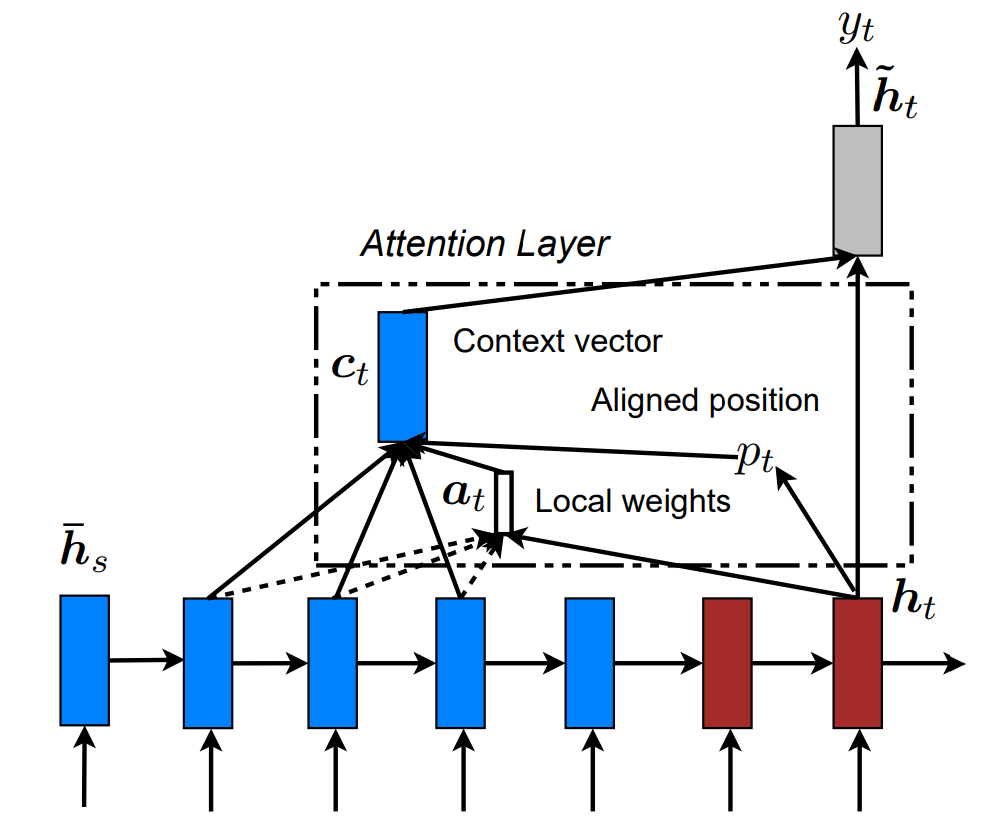
Global 접근법은 compuatational cost가 크고, 긴 문장에 대해서는 제대로 작동하지 않을 가능성이 있다는 문제가 있습니다. 그래서 고안한 방법이 local 접근법입니다. 이 방법은 Xu등의 이미지 캡셔닝 논문에서 제안된 soft와 hard attentional 모델의 tradeoff에서 영감을 받아서 만들어졌습니다. Soft attention은 global attention 접근법과 비슷한데, 가중치가 source image의 모든 패치 위에 softly하게 놓여졌다는 의미에서 그렇습니다. Hard attention인 한 time step에서 하나의 patch를 선택하여 집중합니다. 이 방법은 inference time에서 cost가 적긴 하지만, 모델이 미분 불가능하고 훈련을 위해서는 variance reduction이나 reinforcement learning과 같은 복잡한 기법들을 포함한다는 문제가 있습니다.
반면에 논문에서 제시한 local attention 메커니즘은 small window of context에 부분적으로 집중하는데, 미분 또한 가능합니다. 이 방법은 soft attention에서 발생하는 expensive compuation에 대한 문제도 해결하고, 동시에 hard attention보다 훈련이 쉽다는 장점을 갖습니다.
모델 관점에서 조금 더 자세하게 알아보면, 모델은 첫 번째로 target word에 대해 aligned position $p_t$를 생성합니다. window $[p_t - D, p_t + D]$안에 있는 source hidden state에 대한 가중 평균으로 $\boldsymbol{c}_t$가 계산됩니다. $D$의 값은 실험적으로 결정되었습니다. Window size를 지정하기 때문에, global과 다르게 local에서는 $\boldsymbol{\alpha}_t$의 차원이 고정됩니다.
Monotonic alignment
Local 접근법에는 두 가지 변형된 버전이 있습니다. local-m은 $p_t = t$라고 가정하여, source와 target 시퀀스가 단조적으로 정렬되었다고 생각합니다. alignment vector는 local에서와 같은 공식으로 계산합니다. 결론적으로 local-m은 alignment vector의 차원이 고정되었다는 것만 빼면 global 접근법과 같습니다.
Predictive alignment
local-p는 다음과 같은 공식을 사용하여 $p_t$를 정의합니다.
$$ p_t=S\cdot \textrm{sigmoid}(\boldsymbol{v}_p ^\intercal\tanh(\boldsymbol{W}_{\boldsymbol{p}}\boldsymbol{h}_t)) $$
$\boldsymbol{W}_{\boldsymbol{p}}$와 $\boldsymbol{v}_p$는 position을 예측하기 위해서 학습되는 파라미터입니다. $S$는 문장의 길이입니다. sigmoid 연산의 결과로 $p_t \in [0, S]$ 입니다. $p_t$를 중심으로 한 가우시간 분포를 모델링하여, 각 단어에 대한 source와 target 문장 내에서의 alignment를 결정합니다. aligment weights는 다음과 같이 정의합니다. align 함수는 Global attention에서 언급한 것과 같은 함수를 사용하였고, 표준편차는 실험적으로 $\sigma = {D \over 2}$로 결정하였습니다. 수식에서 $p_t$는 실수(real number)이며, $s$는 $p_t$를 중심으로 한 window 내의 정수입니다.
$$ \boldsymbol{\alpha}_t(s)=\textrm{align}(\boldsymbol{h}_t,\bar {\boldsymbol{h}}_t)\exp\left( -(s-p_t)^2\over 2\sigma^2 \right) $$
3.3 Input-feeding Approach
Global과 local 접근법은 독립적이기 때문에 무엇이 최적화된 것인지를 알 수 없고, 추가적인 검증이 필요합니다. 전통적인 MT에서는 이미 번역된 단어들의 집합인 coverage set를 유지하고 관리합니다. 마찬가지로 attentional NMT에서는 alignment decision이 이전 alignment 정보와 함께 고려되어야 합니다. 즉, $p_{t-1}$에 대한 정보가 이번 time step에서 필요합니다. 이 문제를 다루기 위해서 제안된 개념이 input-feeding approach입니다. 이는 Attentional vector $\tilde{\boldsymbol{h}}_t$를 다음 time step의 input과 concat하여 전달하는 개념입니다.
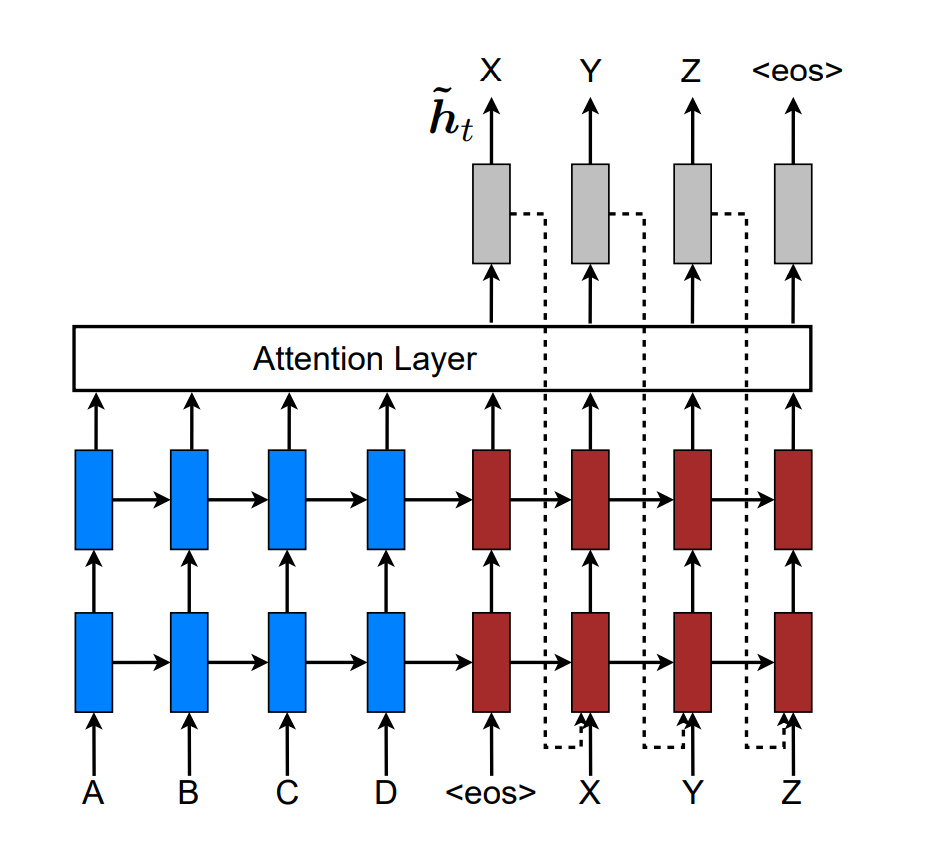
즉, alignment vector와 context vector를 통해 계산한 attentional vector를 이전 time step의 hidden state와 같이 전달하겠다는 의미입니다. 결론적으로 다음 time step에는, attentional vector, previous hidden state, previous prediction의 세 값이 전달됩니다.
이를 통해 두 가지의 효과를 얻을 수 있습니다. 먼저 이전 time step에서의 alignment choice에 대한 정보를 인지하게 되며, 모델을 수평, 수직적으로 더욱 싶게 만들어줍니다. 따라서 이전 time step에서의 alignment를 인지하여, 어떤 부분을 번역했는지에 대한 정보가 전달되고, 각 time step마다 고려할 부분이 많아져 더욱 정확성이 높은 네트워크가 됩니다. Bahdanau도 coverage effect를 구현하였고, Xu도 비슷한 개념을 도입하였으나, 이 논문에서처럼 그 효용을 입증하지는 않았고, 이 접근법이 더 일반화하기 좋습니다.
4. Experiments
WMT English-German 번역 작업을 통해 성능을 검증하였습니다. 하이퍼파라미터는 newstest2013에 포함된 3000개의 문장을 사용하여 최적화하였습니다. 성능은 case-sensitive, tokenized, NIST BLEU score를 사용하여 측정하였습니다. case-sensitive는 정확한 단어가 사용되었는지를 검사합니다. 구체적으로, 고유 명사의 capitalize 여부도 확인합니다. tokenize BLEU는 전체적인 문장의 의미가 유사한지를 검사합니다.
4.1 Training Details
모든 모델에 대해 실험은 WMT'14 데이터셋의 (1억 1600만개의 영어 단어, 1억 1000만개의 독일어 단어로 구성된) 450만 개의 문장 쌍으로 진행하였습니다. 두 언어 모두 vocab size는 top 50000개로 제한하였습니다. vocab에 존재하지 않는 단어는 모두 <unk> 토큰을 부여하였습니다. 50 단어가 넘는 문장은 사용하지 않았고, 훈련 도중에 미니배치를 셔플하여, 잠재적인 bias의 형성을 예방하였습니다.
LSTM은 4개의 레이어로 구성되었고, 각 레이어는 1000개의 cell을 갖습니다. Embedding 차원은 1000 입니다. Loung의 논문에서 사용한 setting과 유사하게 설정하였는데, 파라미터는 $[-0.1, 0.1]$로 uniform distribution을 사용하여 초기화하였으며, plain SGD를 사용하여 10 epoch동안 학습하였습니다. Learning rate는 1로 하였으며, 5 epoch이후 매 epoch마다 절반으로 줄였습니다. Batch size는 128이며, gradient는 5를 초과하면 정규화하여 스케일을 조정하였습니다. 0.2의 dropout을 적용하였고, dropout을 적용할 경우, 모델은 12 epoch를 학습하였습니다. 이 때, learning rate는 8 epoch 이후부터 절반으로 줄였습니다.
Local attention model의 window size $D$는 10으로 하였습니다. 코드는 MATLAB으로 구현하였으며, Tesla K40 GPU 하나를 사용했을 때, 초당 1000개의 target words를 생성하였습니다. 총 훈련 시간은 7~10일 정도가 걸렸습니다.
4.2 English-German Results

Local-p attention과 input-feeding approach 까지 적용한 결과, 기존에 알려진 기법인 dropout, reversing input 등을 적용한 NMT 모델보다 BLEU points가 5.0점 향상되었습니다. Unknown replacement 기법을 적용하자 추가로 1.9점이 향상되었는데, 이는 논문의 모델이 unknown words에 대해서도 alignments를 잘 학습했음을 입증합니다. 마지막으로 서로 다른 세팅을 적용한 모델 8개를 앙상블하여 SOTA 모델에 등극하였습니다.

논문의 모델은 WMT'14 데이터셋으로 학습하였으나, WMT'15 데이터셋에서도 SOTA 성능을 보여주었고, 그만큼 일반화가 잘 되었음을 보여줍니다.
4.3 German-English Results
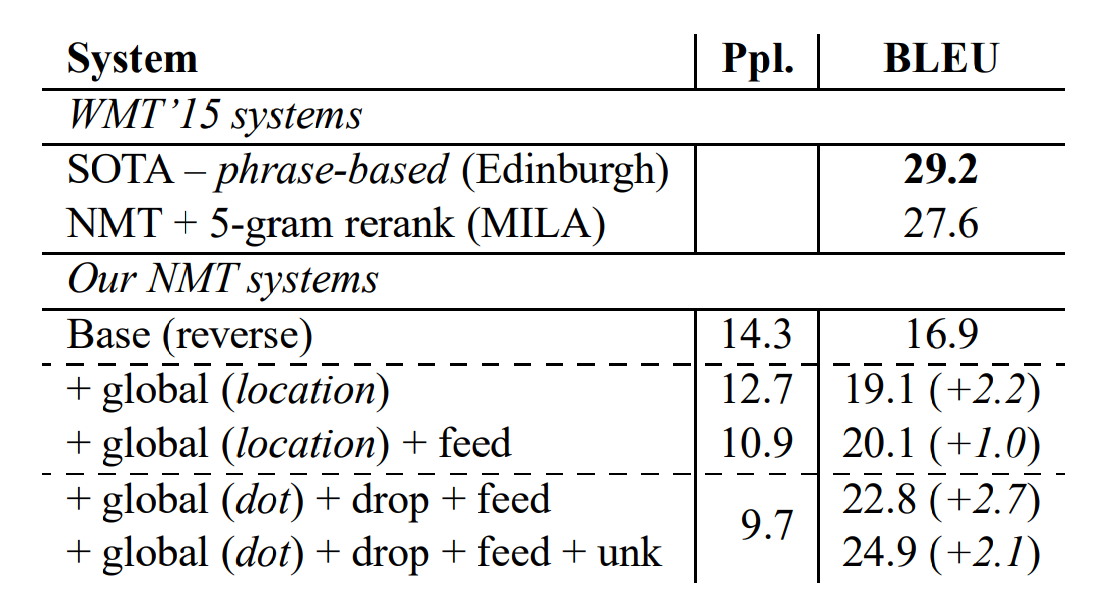
WMT'15의 German-English 번역 태스크에서는 SOTA system에 미치지는 못했으나, 논문에서 제안한 기법을 단계적으로 적용할 때, 의미있는 성능 향상이 있음을 보여줍니다. 마찬가지로, 이 기법들이 일반화가 잘 된다는 사실을 입증합니다.
5. Analysis
이 섹션에 사용된 모든 결과물들은 English-German newstest2014 태스크에 대한 것입니다.
5.1 Learning Curves
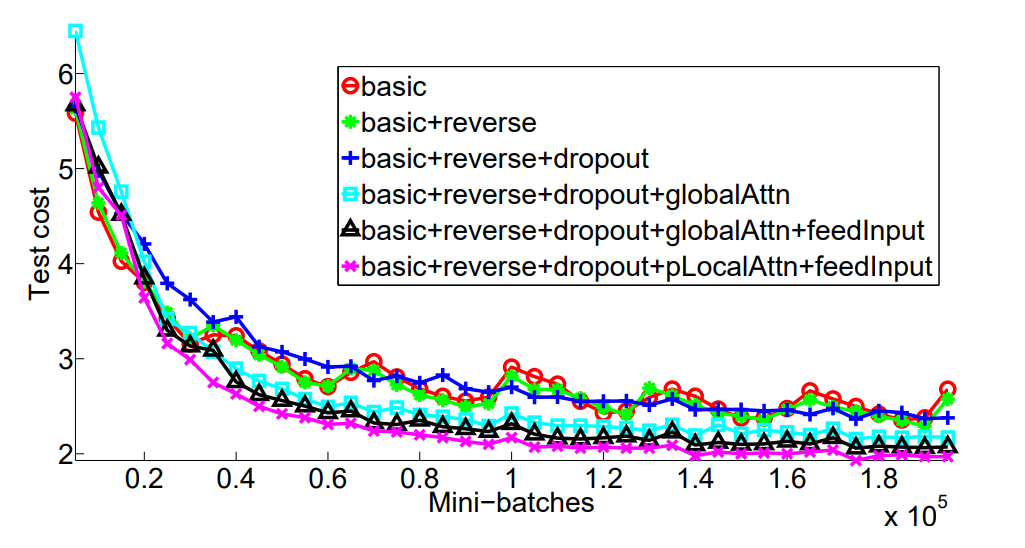
Dropout을 적용할 경우, 학습 시간은 느려지지만, test error가 감소함을 확인할 수 있습니다.
5.2 Effects of Translating Long Sentences
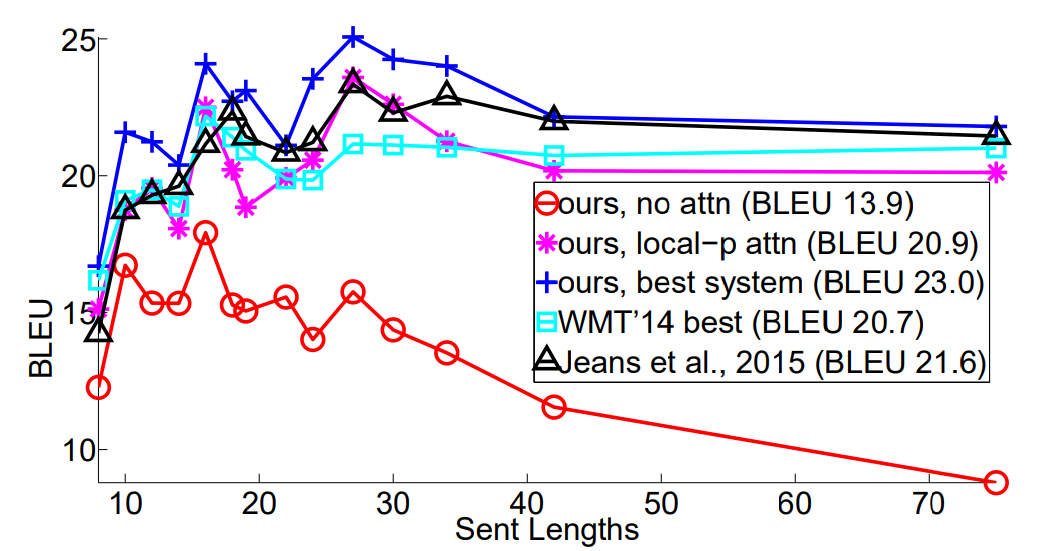
Attention 메커니즘을 사용하지 않은 모델에 비해서 긴 문장을 다루는데 적합함을 보여줍니다. 문장의 길이가 길어져도 번역의 질이 거의 저하되지 않습니다.
5.3 Choices of Attentional Mechanism
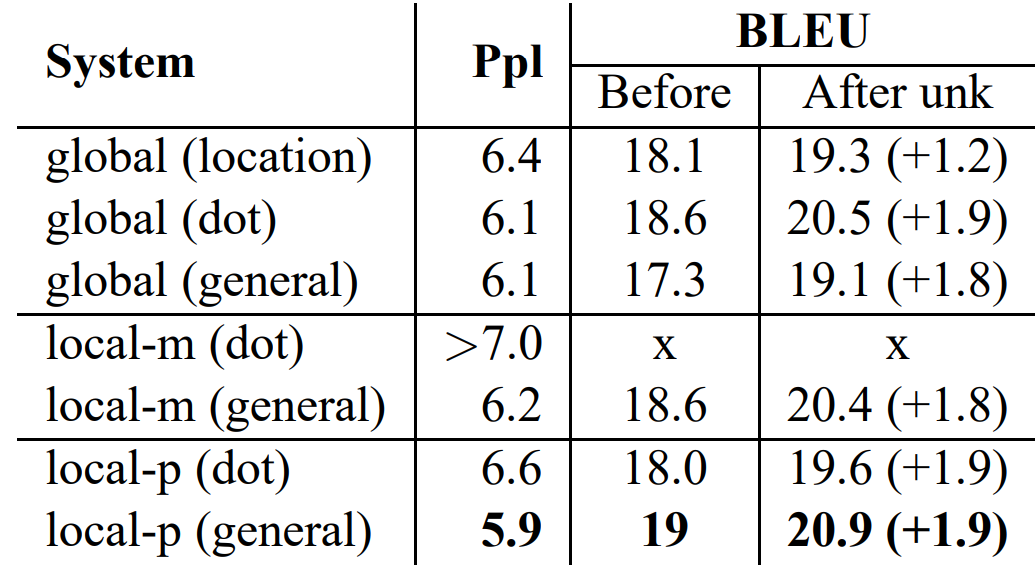
논문에서는 한정된 자원(GPU, 시간 등)으로 인해 모든 조합을 실험해보지는 않았다고 언급합니다. Global-location model은 replacing unknown word 기법과의 시너지가 좋지 않음을 확인할 수 있습니다. Content-based functions 중에서는 dot이 가장 좋은 성능을 보여줍니다.
5.4 Alignment Quality
논문에서는 attentional model에 대한 연구의 부산물로 word alignment를 얻었다고 소개합니다. Bahdanau 등도 일부 문장에 대해서 alignments를 시각화했고, 번역의 질이 향상되었음을 관찰했습니다. 이 외에 다른 alignment에 대한 연구는 존재하지 않습니다. 이 논문에서는 추가로 alignment error metric(AER)라는 지표를 도입하여 alignment quality를 측정했습니다.
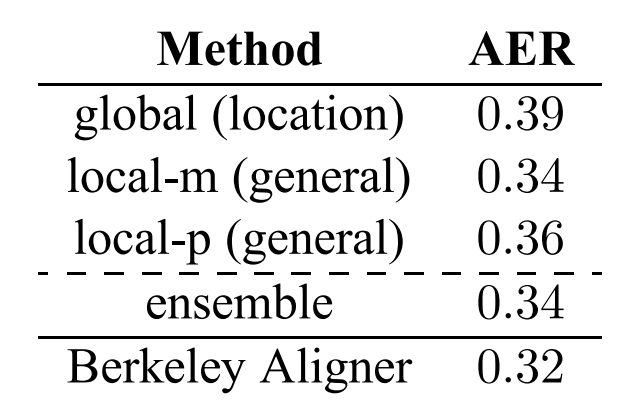
기존의 alignment data를 사용하여 모델이 reference와 같은 번역을 생성하도록 강제하였습니다. Target 단어에 대해서 가장 높은 가중치만을 선택하여 one-to-one alignements를 추출하였습니다. 즉, 여러 가중치를 바탕으로 가중 평균을 계산한것이 아닌, 가중치의 최댓값만을 선택하여 source와 target word간의 alignment를 학습하였습니다. One-to-many alignments를 사용하지 않았음에도 불구하고 가장 좋은 AER score를 얻을 수 있었습니다. 앙상블 모델과 local-m의 AER 점수가 같고, global 모델의 점수가 가장 높다는 점에서, 이 지표는 모델의 성능과는 큰 상관관계가 있지는 않다고 볼 수 있습니다.
5.5 Sample Translations
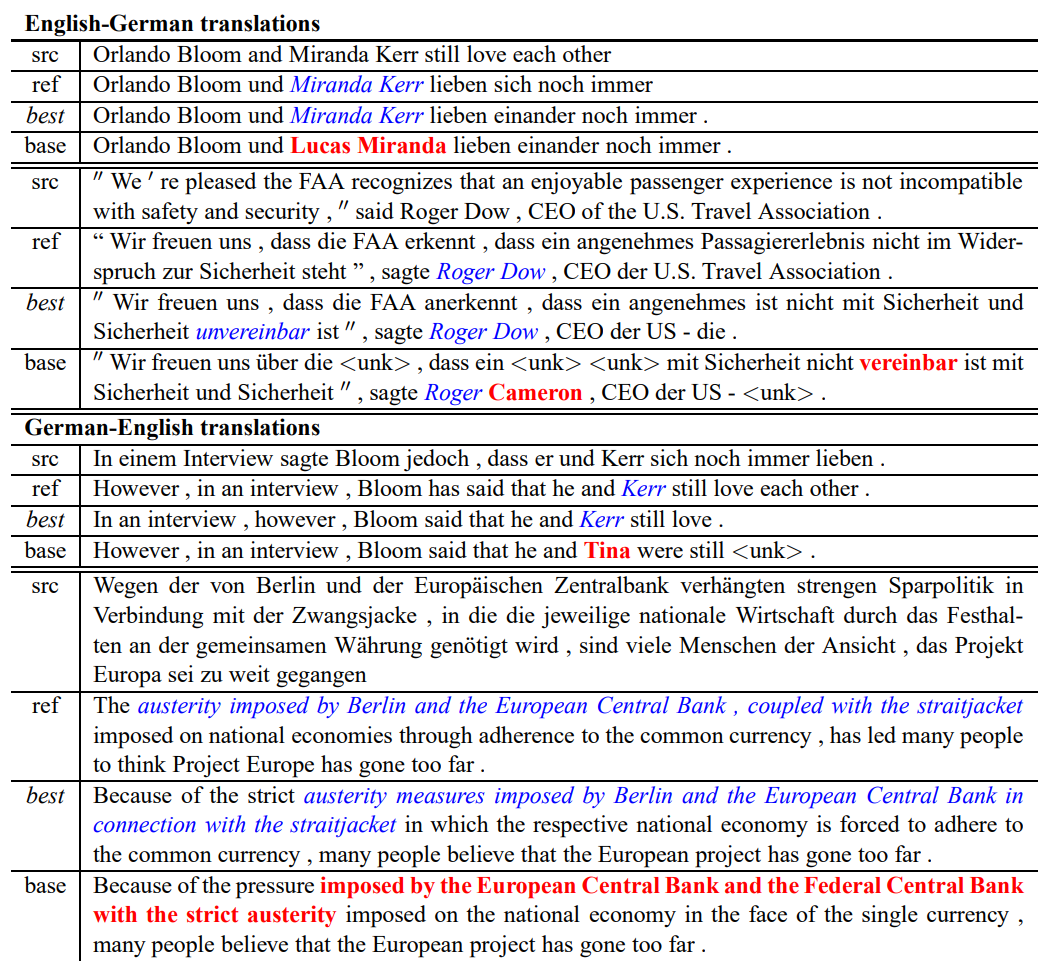
Attentional model이 이름을 정확하게 번역했다는 점이 흥미롭습니다. Non-attentional model도 그럴듯한 이름을 생성하지만, source와 target 문장에 나타난 이름 간의 직접적인 연관성은 없습니다. 또한, non-attentional model과는 다르게 이중 부정 문장에 대해서도 문제없이 번역한다는 사실을 확인할 수 있습니다.
6. Conclusion
논문에서는 두 가지의 간단하고 효과적인 attentional mechanism을 적용한 모델을 제안하였습니다. Global approach는 항상 모든 source positions에 집중하고, local approach는 source positions의 일부(subset)에 집중합니다. WMT English-German 양방향 번역 태스크로 성능을 검증하였으며, 이미 알려진 기법인 dropout, reversing input 등을 적용한 non-attentional model에 비해 BLEU points를 5.0점 향상시켰습니다. 특히 영어를 독일어로 번역하는 태스크에 대해서는 WMT'14와 '15 모두에서 SOTA 모델을 달성하였습니다. 다양한 alignment functions를 비교하여 attentional model 과의 최적의 조합을 발견하였습니다. Attention 메커니즘을 기반으로 한 모델은 긴 문장을 다루거나, 이름을 번역하거나, 이중 부정 문장 번역에 있어서 non-attention 모델보다 성능이 우수함을 검증하였습니다.




댓글