
추상적 요약(Abstractive Summary) 모델을 다룬 PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization에 대한 논문을 읽고 리뷰해보았습니다. 오개념이 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
개요
텍스트 요약은 입력 문서에 대한 정확하고 간결한 요약문을 생성하는 것을 목표로 합니다. 단순히 입력 문서의 일부를 복사하는 것에 그치는 추출적 요약(extractive summarization)과는 다르게, 추상적 요약(abstractive summarization)은 요약문에 새로운 단어를 생성하기도 합니다. 좋은 추상적 요약문은 핵심 정보를 잘 담고, 언어적으로도 유창합니다. 추상적 요약은 RNN을 기반으로 한 인코더 - 디코더 아키텍처를 사용한 sequence-to-sequence 프레임워크를 주로 사용하다가, 최근에는 Transformers 아키텍처를 사용하게 되었습니다. 추상적 요약 연구의 핵심은 대규모, 고품질의 문서-요약 쌍 데이터입니다. 그래서 최근에는 더 많고 긴 문서를 포함한 데이터, 다양한 도메인을 다루는 데이터 등을 포함한 데이터셋을 구축하는 작업이 활발히 이루어졌습니다.
대규모 말뭉치를 사용하여 자기지도학습(self-supervised learning) 기법으로 사전훈련한 Transformers 기반 모델은 텍스트 요약을 포함한 여러 NLP 분야의 다운스트림 태스크에 훌륭한 성과를 이루었습니다. 하지만 추상적 요약을 위해서 설계된 사전 훈련 목표(pre-trained objectvies)에 대해서는 연구된 바가 거의 없습니다. 논문에서는 입력 문서에서 몇 개의 문장을 제거하고, 남은 문장을 바탕으로 제거된 문장을 다시 생성하는 사전 훈련 기법을 제안합니다. 특히 추정적으로(putatively) 중요한 문장을 선택하여 제거 후 생성하는 방식은 임의의, 또는 처음 몇 개의 문장을 제거하는 방식보다 뛰어난 성능을 보였습니다. 논문에서는 이 사전 훈련 목표가 다운스트림 태스크에서 모델이 문서를 이해하고 요약과 같은 문장을 생성하는 것과 비슷하기 때문에 추상적 요약 작업에 매우 적합한 방식이라는 가설을 세웠습니다. 이러한 새로운 자기지도학습 기법인 Gap Sentence Generation(GSG)와 함께 Pre-training with Extracted Gap-sentences for Abstaractive SUmmarization Sequence-to-sequence 모델, PEGASUS가 탄생하였습니다.
정리하자면, 논문의 주요 Contributions은 다음과 같습니다.
- 추상적 요약 태스크를 위한 새로운 자기지도 사전훈련 목표(self-supervised pre-training objective)인 gap-sentence generation을 제안하고, gap-sentence를 선택하는 방법에 대한 연구를 수행하였습니다.
- 다양한 범주의 다운스트림 요약 태스크에서 논문에서 제안한 기법에 대한 검증을 수행하고, 12개의 데이터셋에 대하여 기존SOTA 모델보다 뛰어나거나 비슷한 성능을 보임을 확인하였습니다.
- 일부 데이터셋에 대한 인간 수준의 요약 성능과 실험 설계의 검증을 위하여 Human Evaluation에 대한 연구를 수행하였습니다.
연구 내용
새로운 사전훈련 목표인 GSG는 BERT의 사전훈련 목표인 MLM과 함께, 또는 독립적으로 사용하여 성능을 검증합니다.
Gap Sentence Generation (GSG)
논문의 저자는 다운스트림 태스크의 목표와 비슷한 사전 훈련 기법을 사용하면 더 빠르게 튜닝할 수 있고 더 좋은 성능을 보일 것이라는 가설을 수립했습니다. 추상적 요약이라는 용도를 고려하여, 제안한 사전 훈련 목표에는 입력 문서의 요약과 같은 텍스트를 생성하는 것이 포함됩니다. 추상적 요약에 대한 레이블이 없는 방대한 양의 말뭉치를 사전학습 과정에 활용하기 위해서 저자는 이러한 기법을 제안한 것입니다. 추출적 요약기로 사전훈련을 수행하는 것도 하나의 단순한 선택지입니다. 하지만 그런 방식은 모델이 단순히 입력의 일부를 복사하는 방법만을 학습할 것이고, 추상적 요약에는 적합하지 않습니다.
저자는 SpanBERT 논문에서 영감을 받아서 GSG를 고안하였습니다. 문서에서 문장을 통째로 마스킹하고 gap-sentences를 연결(concatenate)하여 pseudo-summary로 사용합니다. Gap sentence는 [MASK1] 토큰으로 대체하여 모델에 입력됩니다. 그리고 다른 작업의 mask rate과 비슷한 개념으로 전체 문장에 대한 gap-sentence의 비율을 Gap Sentence Ratio(GSR)로 정의하였습니다.
논문에서는 n개의 문장으로 이루어진 문서 D=xin에서 m개의 Gap sentence를 선택하는 세 가지 전략을 고려하였습니다.
Random
m개의 문장을 균일한 확률로 선택합니다.
Lead
처음 m개의 문장을 선택합니다
Principal
ROUGE1-F1 지표를 사용하여 중요도를 수치화하고 top-m개의 문장을 선택합니다. 점수를 계산하는 수식은 다음과 같습니다. 여기서 rouge 함수의 첫 번째 파라미터는 선택된 문장이고, 두 번째 파라미터는 그 문장을 제외한 문서 내의 모든 문장을 의미합니다. 즉, 각 문장 si에 대해서 그 문장을 제외한 문서 내 나머지 모든 문장 D∖xi과의 rouge 점수를 계산하고, 이 점수가 높은 m개의 문장을 선택합니다. 수식으로 나타내면 다음과 같습니다.
이 전략을 한 번 더 세분화할 수 있습니다. 위 공식에 따라서 계산한 점수를 바탕으로 단순히 top-m개를 선택하는 Ind(independently)방식과 greedy한 방식으로 ROUGE1-F1 점수를 최대화하며 m개의 문장을 선택하는 Seq(sequentially)방식이 있습니다. 논문에 나타난 Sequential Sentence Selection 알고리즘은 다음과 같습니다.
선택된 문장들의 집합인 S와 여기에 속하지 않는 문서 내 다른 문장을 합하여SS∪xi를 만듭니다. 그리고 위에서 언급한 수식대로 rouge 점수를 계산합니다. 이 점수가 최대가 되게 하는 문장 xk를 선택하여 집합 S에 추가합니다. 그리고 선택되 문서의 집합 S내에 m개의 문장이 포함될 때까지 이 과정을 반복합니다.
ROUGE1-F1 점수를 계산할 때도 두 가지 선택지가 있습니다. 첫 번째는 n-gram을 집합으로 생각하는 Uniq 방식입니다. 즉, 정답에 존재하는 n-gram이 생성된 텍스트에 여러번 존재해도 한 번만 카운팅합니다. 그리고 원래 구현처럼 동일한 n-gram이 여러번 존재하면 해당 횟수만큼 카운팅하는 Orig 방식입니다. 결과적으로 Principal 전략은 Ind/Seq와 Orig/Uniq의 조합을 고려하여 총 네 가지 세부 전략으로 세분화할 수 있습니다.
Masked Language Modeling (MLM)
BERT와 같이 이 논문에서도 MLM 기법을 사용하였습니다. 입력 텍스트의 토큰 중 15%를 선택하였고, 그 중 80%는 [MASK2] 토큰으로 대체, 10%는 랜덤한 토큰으로 대체하였고, 나머지 10%는 그대로 두었습니다. MLM 기법은 인코더를 훈련할 때 단독으로, 또는 GSG와 함께 사용되었습니다. 다음 그림은 MLM과 GSG를 함께 사용했을 때, 모델이 어떻게 학습하였는지를 나타냅니다.
MLM 기법이 다운스트림 태스크에서는 특별히 성능 향상을 보이지 않기 때문에, 논문에서 제안한 PEGASUSBASE와 PEGASUSLARGE 모델 중 최종적으로 가장 뛰어난 성능을 보여주는 Large 모델에서는 MLM 기법을 사용하지 않았습니다.
실험 결과
시간과 자원의 효율성을 고려하여 먼저 Base 모델로 실험을 진행하였습니다. Base 모델과 Large 모델의 차이는 다음과 같습니다. L은 인코더와 디코더 각각의 레이어 개수, H는 hidden unit의 차원, F는 피드포워드 레이어의 차원, A는 어텐션 헤드의 개수입니다. Base 모델은 배치 사이즈 256에서, Large 모델은 8192에서 훈련하였습니다.
| L | H | F | A | |
| PEGASUSBASE | 12 | 768 | 3072 | 12 |
| PEGASUSLARGE | 16 | 1024 | 4096 | 16 |
Sinusoidal positional encoding을 사용하였고, 사전 훈련과 파인 튜닝 모두에서 Adafactor를 사용하여 최적화하였습니다.
Pre-training Corpus
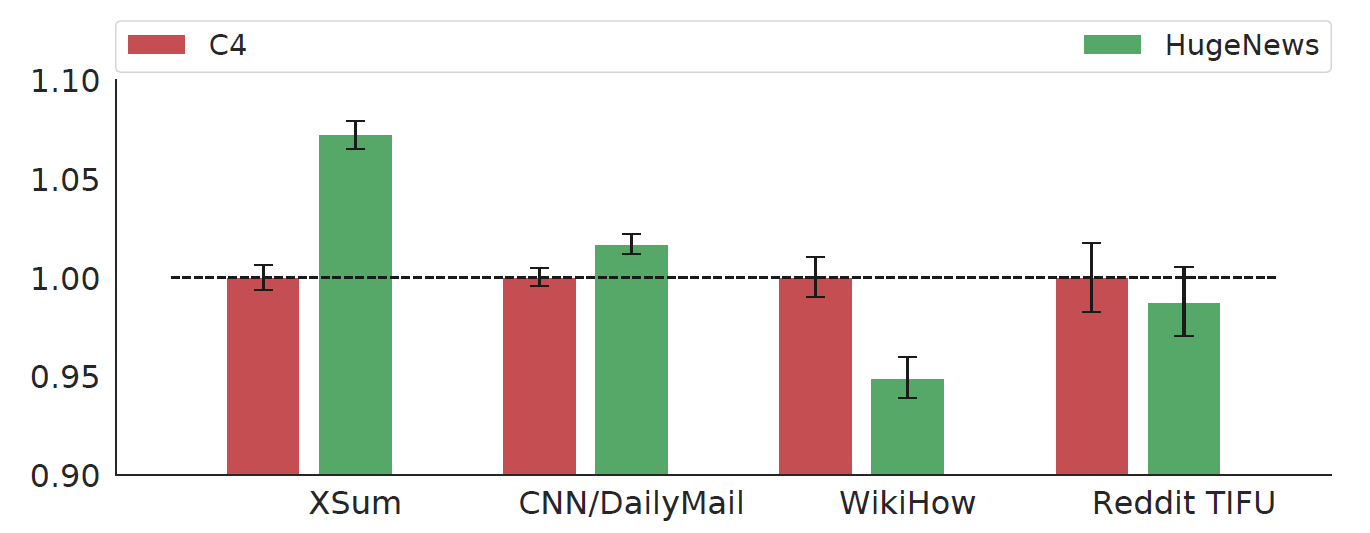
저자는 사전 학습에 사용할 말뭉치를 선택하기 위해서 ablation study를 진행하였습니다. 다음에 나오는 모든 그림에서 y축의 값은 가장 왼쪽 막대 그래프에 대하여 정규화한 수치입니다. 아래 그래프를 보면 HugeNews 데이터는 C4 데이터보다 뉴스 데이터를 사용한 다운스트림 태스크에 대하여 더 좋은 성능을 보입니다. 즉 사전 훈련과 다운스트림 태스크에 사용한 말뭉치의 도메인이 유사할 경우 더 뛰어난 성능을 보임을 알 수 있습니다.
사전학습 목표에 따른 영향
GSG
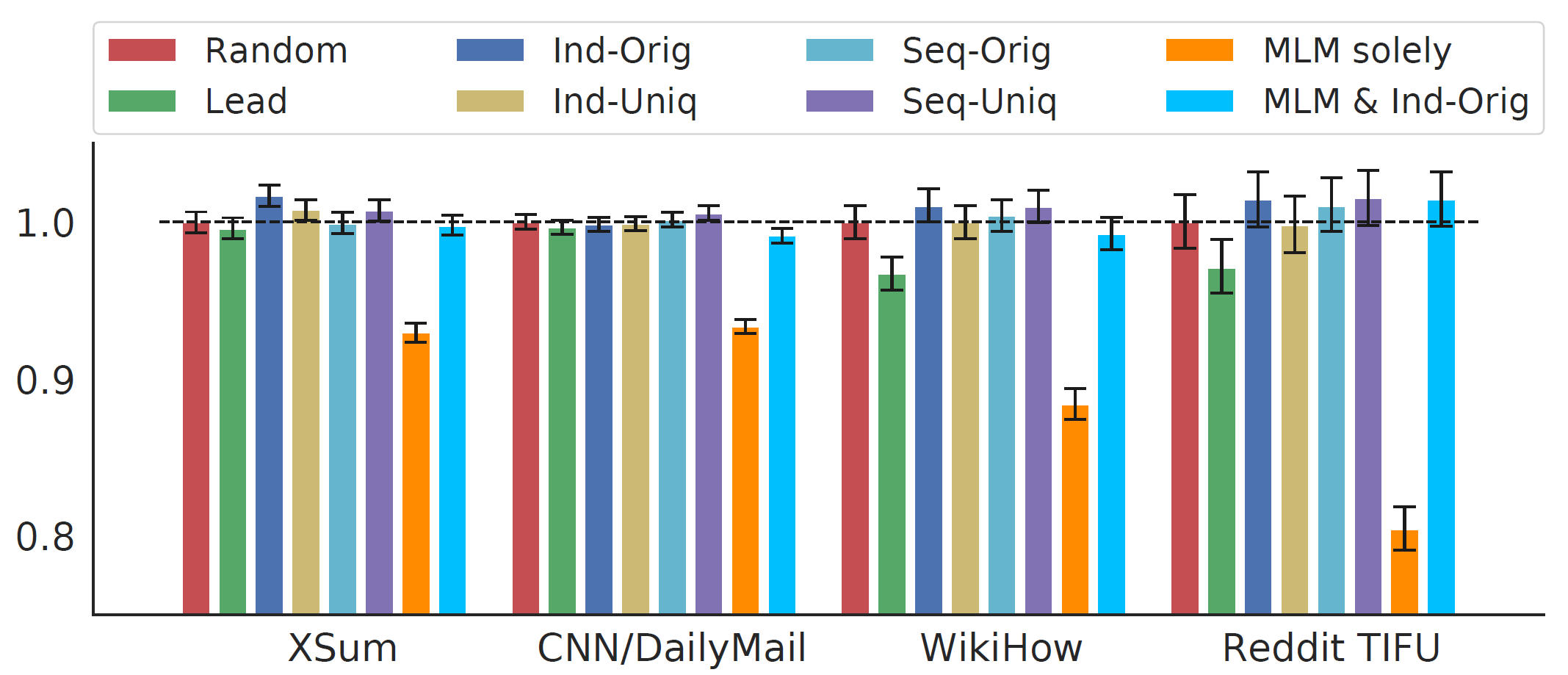
GSR을 30%로 하여 Lead, Random, Ind-Orig, Ind-Uniq, Seq-Orig, Seq-Uniq의 총 6개의 전략을 비교하였습니다. 다음 그림에서 알 수 있듯이, Ind-Orig가 가장 뛰어난 성능을 보였고 그 뒤를 Seq-Uniq가 따랐습니다. 두 기법은 네 개의 다운스트림 데이터셋에서 Random과 Lead보다 항상 좋은 성능을 보였습니다. Lead는 뉴스 데이터셋에 대해서는 나쁘지 않은 성능을 보이지만, 뉴스가 아닌 데이터셋에서는 성능이 매우 뒤떨어집니다. 이를 통해 뉴스 데이터에서 초반부에 요약 내용이 담긴다는 편향을 학습하였음을 알 수 있습니다. 이 실험을 통해 최종적으로 Large 모델에서는 Ind-Orig 기법을 사용하였습니다.
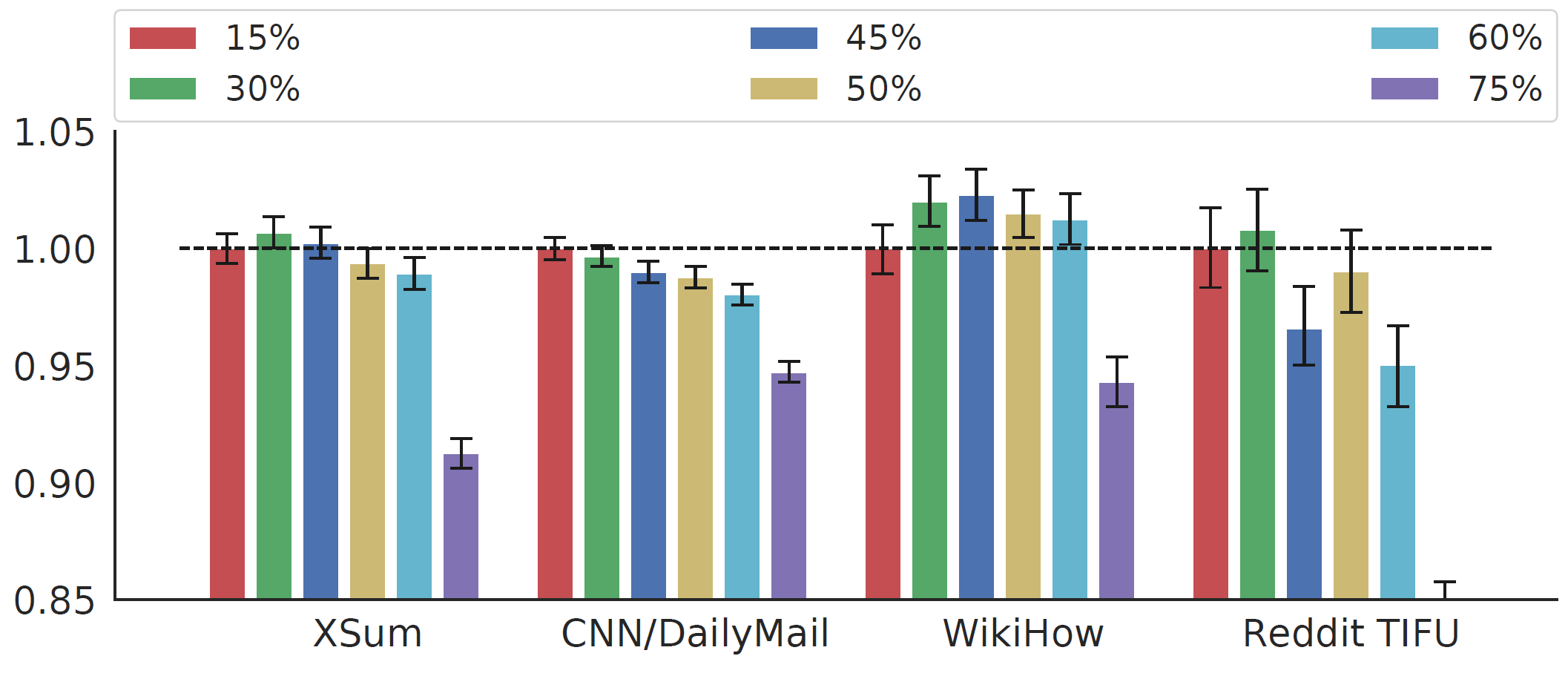
Gap-sentences Ratio (GSR)도 매우 중요한 하이퍼파라미터입니다. 낮은 GSR은 문제를 덜 어렵게 하지만 연산 측면에서는 효율적입니다. 반면 높은 GSR은 문맥에 대한 정보를 과도하게 잃어 문장 생성을 어렵게 만들 것입니다. 저자는 15%에서 75%까지 범위에서 GSR에 따른 성능을 비교하였습니다.
데이터셋마다 다르긴 하지만 다음 그래프에서 알 수 있듯이, GSR이 50% 보다 낮을 때 항상 가장 좋은 성능을 보였습니다. 최종적으로 Large 모델에서는 GSR을 30%로 설정하였습니다.
MLM
앞서 언급했듯이 MLM을 GSG와 함께, 또는 단독으로 사용하였습니다. 함께 사용할 때는 GSG의 Ind-Orig 기법을 사용하였는데, 30%의 문장을 마스킹하고 선택되지 않은 문장의 토큰 중 15%를 마스킹하였습니다. 그래프를 다시 확인해보면, MLM을 단독으로 사용하였을 때는 상당히 낮은 성능을 보였고, MLM과 GSG(Ind-Orig)를 함께 사용하였을 때는 Random만을 사용했을 때의 성능과 거의 비슷합니다.
흥미로운 점은 MLM & Ind-Orig와 Ind-Orig를 비교할 때, 파인튜닝 과정에서 pre-training step이 100k-200k일 때의 체크포인트를 사용할 경우에는 MLM이 성능을 향상시키지만, pre-training step이 500k 이상일 때의 체크포인트를 사용할 경우에는 성능이 오히려 저하됩니다. 따라서 Large 모델에서 최종적으로는 MLM을 사용하지 않기로 하였습니다.
Effect of Vocabulary
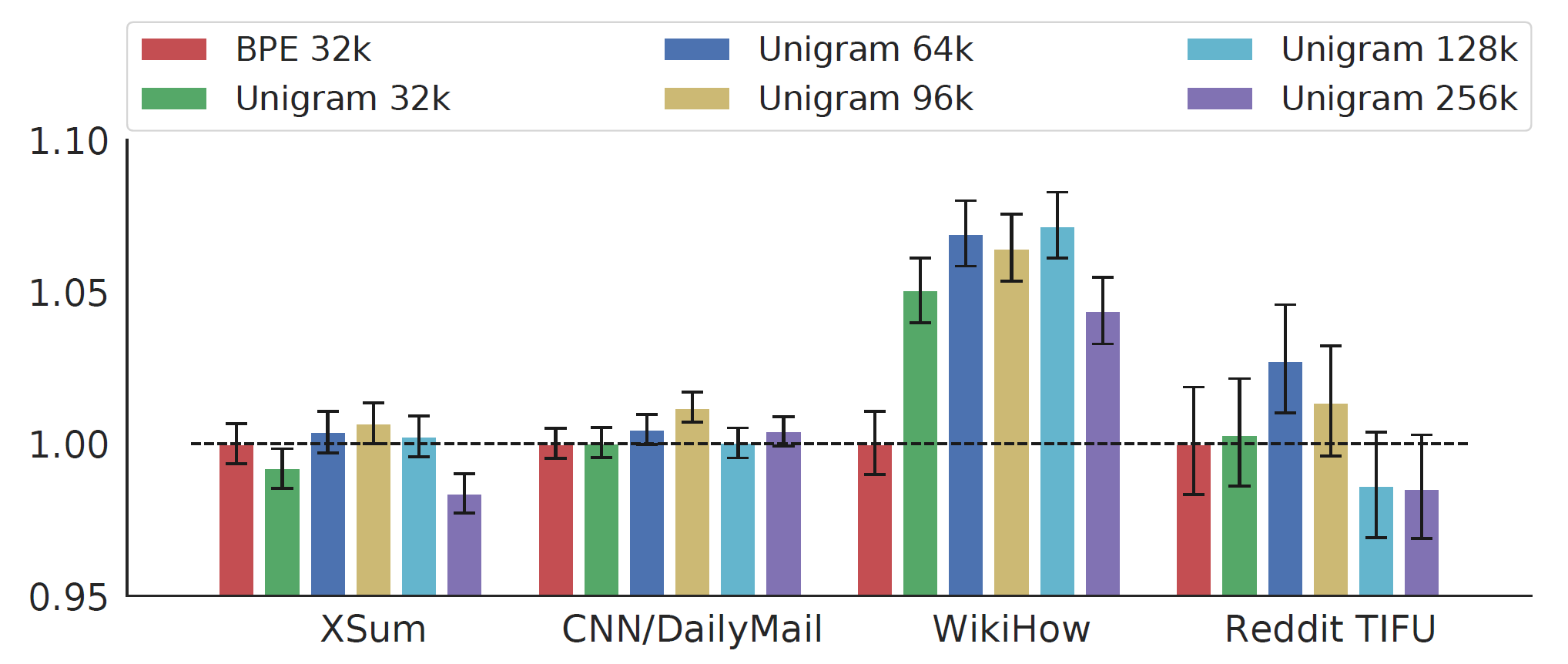
저자는 BPE와 SentencePiece Unigram algorithm 두 가지의 토큰화 기법을 비교하였습니다. 실험에서 모델은 C4 데이터와 15%의 GSR로 Ind-Orig 기법을 사용하여 500k step동안 사전훈련 되었습니다. 토큰화 기법과 Vocubulary size에 대하여 비교한 결과는 다음과 같습니다. 실험을 통하여 전반적으로 가장 좋은 성능을 보이는 Unigram 96k를 Large 모델에서 사용하였습니다.
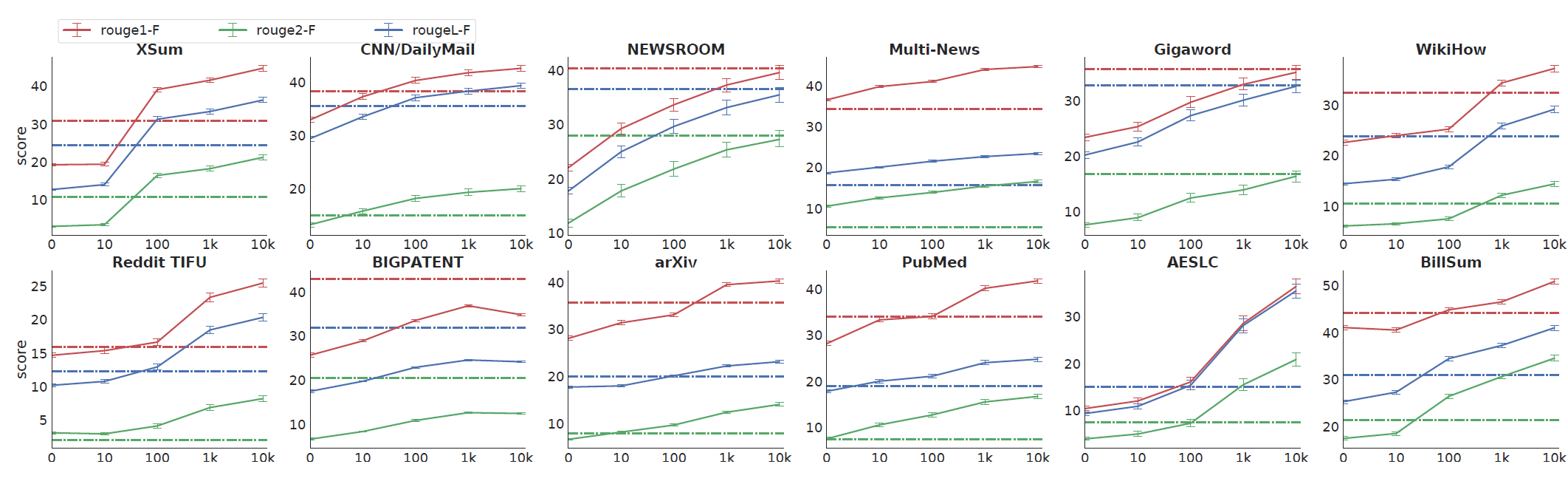
Zero and Low-Resource Summarization
현실에서는 요약 모델 훈련을 위한 레이블이 있는 데이터를 수집하기 매우 어렵습니다. 한정된 자원으로 요약 모델을 훈련하는 상황을 시뮬레이션하기 위해서, 파인튜닝에 사용한 각 데이터셋에서 10k (k=1,2,3,4)개의 샘플을 선택하였습니다. 그리고 배치 사이즈 256, 학습률 5e-4에서 2000 step동안 파인튜닝을 수행하고 evulation 성능이 가장 좋은 체크포인트를 선택하였습니다. 다음 그림에서 알 수 있듯이, 12개 중 8개의 데이터셋에서 겨우 100개의 데이터만으로도 TransformerBASE 모델의 성능을 뛰어넘는 것을 확인할 수 있습니다. 그림에서 점선으로 된 부분이 트랜스포머 모델의 성능을 의미합니다.
결론
논문에서 저자는 새로운 self-supervised pre-training objective인 Gap-sentences Generation과 함께 PEGASUS 모델을 발표하였습니다. 그리고 GSG의 다양한 변형을 시도하여 각 기법의 성능을 평가하고 검증하였습니다. 사전 학습에 사용한 데이터, GSR, 어휘사전의 크기가 미치는 영향을 분석하고 12개의 다운스트림 태스크에서 가장 좋은 성능을 보이는 모델을 구축하였습니다. 또한 한 번도 본적 없는 새로운 데이터에 빠르게 적응하고, 적은 데이터로도 뛰어난 성능을 보이기도 합니다. 마지막으로 Human Evaluation을 통해서 추상적 요약에 과도한 페널티를 부여하는 ROUGE 지표를 사용하여 훈련하였음에도, 요약의 성능이 매우 우수함을 입증하였니다.
더 알아볼 내용
논문에서도 언급했듯이 ROUGE 점수는 결국 텍스트 생성이나 추상적 요약과 같은 태스크에서 동의어나 문맥을 고려하지 못한다는 단점을 갖습니다. 그런데 왜 저자는 ROUGE 점수를 사용하여 모델의 성능을 측정하였는지가 궁금했습니다. 그리고 문서 내 다른 문장들과 비교하여 높은 ROUGE 점수를 갖는 문장을 “중요하다”고 생각한 근거에도 의문이 듭니다. 중요도를 평가하는, 그리고 gap sentences를 선택하는 다른 기법에 대한 연구가 있는지 알아보고 직접 실험해보고 싶다는 생각이 들었습니다.




댓글