
Attention mechanism의 시초라고 할 수 있는 논문, Neural Machine Translation by Jointly Learning to Align and Translate를 읽은 후 리뷰해보았습니다. 해석이 잘못 되었거나, 오개념이 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
개요
기계 번역 분야에서 신경망 기계 번역(Neural Machine Translation, NMT)는 당시 새롭게 제안된 접근법이었습니다. 통계 기계 번역(Statistical Machine Translation, SMT)와는 다르게 NMT는 번역 성능을 극대화할 수 있는 공동으로 훈련될 수 있는 시스템을 구축하는 것을 목표로 합니다. SMT 시스템은 Language Model, Translation Model, Decoder와 같이 여러 컴포넌트를 갖고 이외에도 Reordering Model 등이 있습니다. NMT도 Encoder와 Decoder 구조를 갖기 때문에 엄밀히 말하면 논문에서 말하는 single neural network라는 표현이 틀린 게 아니냐는 의문이 들 수도 있습니다. SMT와 NMT 모두 여러 컴포넌트들이 함께 번역 작업을 수행하기는 하지만, SMT는 위의 컴포넌트들이 따로 훈련되는게 NMT와 다른 점입니다. NMT에서는 인코더와 디코더가 번역 작업을 같이 수행할 뿐만 아니라 학습도 한 번에 이루어집니다.
논문에서는 이런 NMT 모델의 성능을 향상할 수 있는 새로운 메커니즘을 제안합니다. 앞서 언급했듯이, NMT 모델은 주로 인코더 - 디코더 아키텍처를 갖습니다. 인코더는 입력 시퀀스를 고정된 길이의 벡터(fixed-length vector)로 매핑하고, 디코더는 이를 바탕으로 출력 시퀀스인 번역문을 생성합니다. 저자는 여기서 고정된 길이의 벡터가 성능에 병목 현상을 일으킬 수 있다는 점에 주목합니다. 그리고 모델이 다음에 생성할 단어(target word)와 관련이 있는 입력 시퀀스(source sentence)의 일부에 주목하는 방법을 제안합니다. 여기서 각 단어를 생성할 때, 입력 시퀀스의 어떤 부분에 주목해야 하는지는 명시적으로 알려주는 것이 아니라 학습 데이터를 통해 자동으로 학습됩니다.
기존 연구의 한계와 개선점
위에서 설명한 신경망 기계 번역 모델의 특징을 요약하면 다음과 같습니다. 인코더 - 디코더 시스템은 원본 문장에 대해 올바른 번역이 생성될 확률을 최대화하기 위하여 인코더와 디코더가 함께 훈련됩니다. 인코더에서 입력 문장에 대한 모든 정보는 압축되어 고정된 차원의 벡터에 담깁니다. 문제는 이러한 방식은 긴 문장을 다루는 데 적합하지 않습니다. 특히 학습 데이터에서 본 문장보다 더 긴 문장을 다룰 때 문제는 더욱 심해집니다. On the Properties of Neural Machine Translation: Encoder–Decoder 논문에서는 실제로 입력 문장의 길이가 길어질수록 번역 모델의 성능이 급격히 저하되는 현상을 확인하였습니다.
저자는 이 문제를 해결하기 위해서 정렬(align)과 번역(translate)을 함께 학습하는 메커니즘을 제안합니다. (align을 번역하면 표현이 어색해져서 앞으로는 원문을 사용하겠습니다.) 모델이 번역문의 새로운 단어를 생성할 때마다, 입력 문장에서 관련된 정보를 갖는 부분(source positions)에 집중합니다. 그리고 현재까지 생성된 target words(번역의 일부)와 source positions을 바탕으로 한 context vectors에 기반하여 다음 단어를 예측합니다. 결국 가장 큰 차이점은, 입력 문장 전체를 하나의 고정된 차원의 벡터에 매핑하지 않는다는 것입니다. 그 대신에 번역을 생성하는 과정에서 입력 시퀀스의 일부를 유연하게 선택하여 인코딩을 수행합니다.
디코더
위 내용을 수식적으로 표현하면 다음과 같습니다. 먼저 기존 모델의 디코더가 다음 단어를 예측할 때는, 다음 수식의 확률을 최대화하는 방향으로 학습합니다.
풀이하면, 매 타임스텝마다 입력 시퀀스를 고정된 차원의 벡터로 매핑한 벡터인 c와 현재까지 생성된 번역이 주어졌을 때 다음에 생성할 단어를 포함한 번역문이 출력될 조건부 확률을 최대화한다는 것입니다. RNN 모델에서 각 조건부 확률은 아래와 같이 계산됩니다.
여기서 g는 어떤 비선형 함수이며 st는 RNN의 은닉 상태입니다.
논문에서는 디코더가 학습하는 조건부 확률에 대한 식을 다음과 같이 새롭게 정의합니다.
여기서 si는 i번째 타임 스텝에서 RNN의 은닉 상태이며, 다음과 같이 계산됩니다.
기존의 식과 가장 큰 차이점은 ci입니다. 즉, 매 타임스텝마다 참조하는 context vector도 달라진다는 것입니다. ci는 sequence of annotations (hi,⋯,hTx)에 의존하는데, hi는 입력 시퀀스 전체에서 i번째 단어 주위에 있는 단어들에 주목한 정보를 담고 있습니다. ci는 다음 수식과 같이 hi들의 가중합으로 계산됩니다. 참고로 논문에서 사용되는 annotations라는 표현은 굳이 번역하면 표현 벡터나 은닉 상태 정도가 되겠으나, 원래 의미를 살리기 위해서 원문 표기를 따랐습니다.
각 annotations(hj)에 대한 가중치(aij)는 다음과 같이 계산됩니다.
eij는 alignment model이라고 부르며 position j 주위의 입력 시퀀스와 출력 시퀀스의 position i가 얼마나 잘 매칭되는지에 대한 점수입니다.
논문에서 제안한 메커니즘의 또 한가지 새로운 점은 alignment가 latent variable이 아니라는 것입니다. 즉 alignment model이 translation model과 별개로 훈련하지 않고, soft alignment를 계산하는 과정에서 두 모델이 함께 학습됩니다.
인코더
일반적인 RNN에은 입력 시퀀스를 첫 번째 단어부터 순서대로 읽습니다. 하지만 논문에서는 양방향 RNN(bidirectional RNN, BiRNN)을 사용하여 각 annotation이 앞에 오는 단어(preceding words) 뿐만 아니라 뒤따라 오는 단어(following words)까지도 고려하도록 합니다.
즉, 순방향 RNN →f은 입력 시퀀스를 순서대로 읽고 순방향 은닉 상태(→h1,⋯,→hTx)를 계산하고, 역방향 RNN ←f은 입력 시퀀스를 역순으로 읽고 역방향 은닉 상태(←h1,⋯,←hTx)를 계산합니다. 그 후 각 단어 xj에 대한 annotations은 앞에서 계산한 순방향 은닉 상태와 역방향 은닉 상태를 연결(concatenate)하여 얻는데, 수식으로는 다음과 같이 나타냅니다.
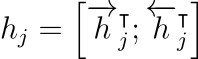
RNN은 최근 입력을 더 잘 기억하는 경향이 있기 때문에, annotation은 각 단어 근처의 단어들이 갖는 의미에 더욱 주목할 것입니다. 각 단어에 대한 annotations, 즉 sequence of annotations는 디코더와 alignment model에서 context vector를 계산할 때 사용됩니다.
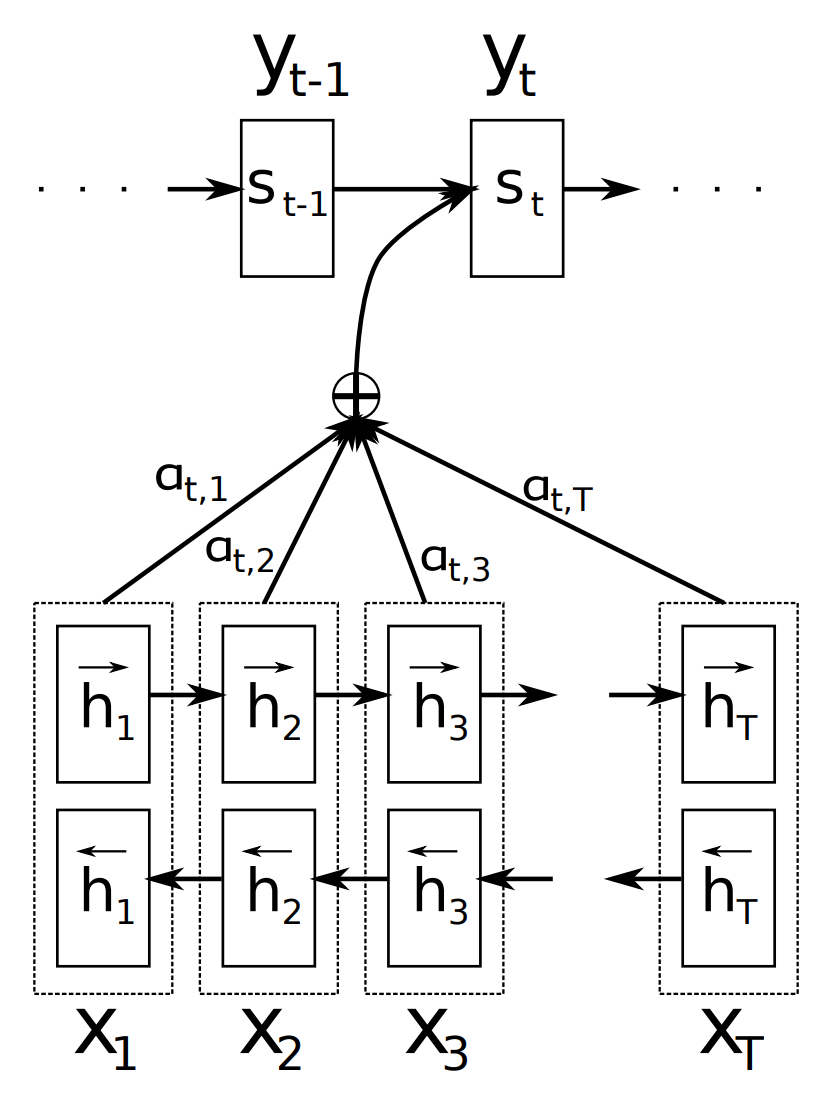
논문의 그림을 사용하여 수식을 다시 한번 이해해보겠습니다. 그림은 입력 문장 (x1,x2,…,xT)이 주어졌을 때, t번째 target word인 yt를 생성하는 상황입니다. 논문의 수식에서는 모든 아래 첨자에 t대신 i를 사용하므로 i번째 target word인 yi를 생성하는 상황이라고 가정하여 설명하겠습니다. 인코더에서 일어나는 일부터 순서대로 정리해보겠습니다. 참고로 이 논문에서 annotations와 hidden state는 서로 같은 개념을 뜻한다고 볼 수 있습니다. 인코더의 hidden state를 annotations, 디코더의 hidden state는 그대로 hidden state라고 표기합니다. 기호도 hj와 si로 구분하는데, 아마 각각을 구분하기 위해서 annotations라는 표현을 별도로 사용한 것이라고 생각됩니다.
양방향 RNN으로 이루어진 인코더는 각 입력 단어 xj에 대한 annotations인 hj를 만듭니다. 여기서 j의 범위는 1≤j≤xTx가 됩니다. 즉, xi부터 xTx까지의 annotations인 hi부터 hTx가 만들어질 것입니다. 그런데 인코더는 양방향 RNN이므로 각각의 annotations는 순방향과 역방향 RNN의 hidden state를 모두 사용해서 만듭니다. 순방향 RNN의 hidden state인 →hj와 역방향 RNN의 hidden state인 ←hj를 단순히 연결합니다. 수식으로는 hj=[→h⊺j;←h⊺j]와 같이 나타나는데, 전치(transpose)는 단순히 벡터를 연결하기 위한 과정에서 수행하는 것일 뿐입니다.
인코더에서 얻은 annotations hj와 디코더의 이전 타임스텝의 hidden state si−1를 사용하여 alignment energy인 eij 벡터를 계산할 수 있습니다. eij=a(si−1,hj)와 같이 나타나는데, a는 alignment model로 논문에서는 순방향(feedforward) 신경망을 사용합니다. i번째 target word가 생성될 때, 입력 시퀀스의 각 단어들에 대해 가중치 aij를 계산합니다. 수식을 다시 한번 보며 자세히 살펴보겠습니다.
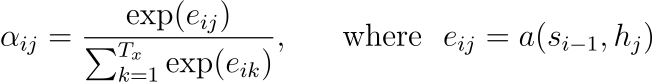
즉, i번째 target word를 생성할 때, 입력 시퀀스의 모든 단어 (x1,x2,…,xT)와의 alignment를 생각해야 하므로, 위 식의 분모에서 부분합 공식이 사용된 것입니다. 그 중에서 특히 j번째 입력 단어와의 관계에 주목하기 위해서 소프트맥스 함수를 취해서 αij를 계산합니다. 이렇게 계산한 가중치를 인코더의 각 annotations에 곱해서 가중합을 구합니다. 즉, 디코더에서 i번째 target word를 생성할 때, 인코더의 annotations인 hj를 앞에서 계산한 가중치인 aij만큼 고려하여 context vector ci를 계산하겠다는 것입니다. 엄밀한 설명은 아니지만 비유하자면, 단어를 새롭게 생성할 때 입력 문장의 각 단어를 얼마만큼이나 중요하게 생각할지를 계산하는 것입니다. 즉, aij는 source word xj와 target word yi가 연관될 확률을 나타낸다고 이해할 수 있습니다.
연구결과
양적 평가
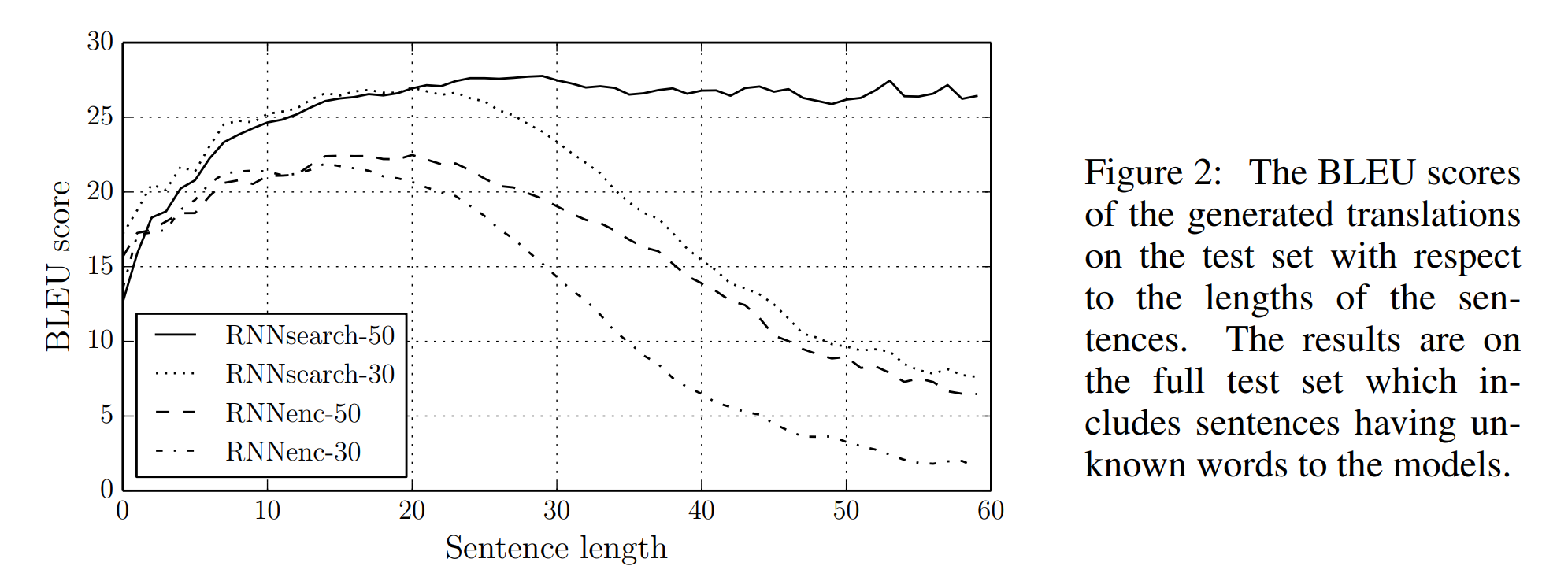
논문에서는 제안한 메커니즘을 바탕으로 RNNsearch라는 모델을 만들어 기존 모델과 비교하였습니다. 그림에서 30과 50은 학습한 문장의 최대 길의입니다. 기존 모델인 RNNencdec과 논문에서 새롭게 제안한 RNNsearch 모델은 모두 1000개의 hidden unit을 갖습니다. 주목할 점은 가설의 내용대로 고정된 차원의 벡터에 입력 시퀀스를 매핑하는 대신, alignment model을 사용하였더니 긴 문장에 대한 번역 성능이 크게 저하되지 않았다는 것입니다. 특히, RNNsearch-50의 경우 길이가 50이 넘는 문장에 대해서도 BLEU score가 감소하지 않습니다.
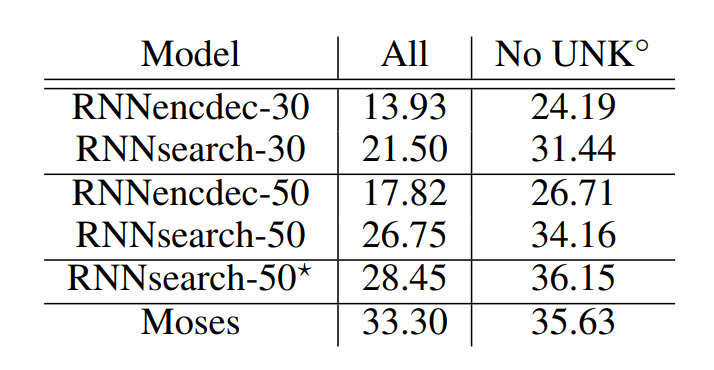
표는 모델 성능을 BLEU 점수로 평가한 결과입니다. phrase-based translation system인 Moses와 비교하여도 크게 뒤떨어지지 않는 성능이며, Moses는 RNNsearch 모델 학습에 사용한 데이터 외에도 418M(4억 1800만)개의 단어로 이루어진 단일 언어 말뭉치를 추가로 사용하여 구축된 모델임을 감안하면 놀라운 성과입니다.
참고로 논문이 발표된 당시에는 신경망 기계 번역보다는 통계 기계 번역이 훨씬 많이 사용되는 시기였습니다. phrase table과 statistical model 등을 사용한 기계 번역 기법은 오랫동안 연구되었기 때문에 당시에 최고의 성능을 내는 모델은 SMT 모델이었습니다. 과거에는 데이터나 하드웨어 성능의 한계가 존재했기 때문에 NMT 연구는 당시로서는 비교적 새로운 개념이었습니다. 게다가 SMT 모델은 앞에서 말한 phrase table이나 통계를 기반으로 번역을 수행하지만, NMT 모델은 블랙박스로 여겨졌기 때문에 해석가능성 면에서도 상당히 뒤쳐졌습니다. 따라서 NMT 모델의 성능과 효과를 입증하기 위해서는 당시 주류였던 SMT 모델과의 비교하는 일이 흔히 일어났습니다.
질적 평가
Alignment
논문에서 제안한 방법을 통해 이렇게 입력과 출력 문장의 각 단어에 대한 alignment를 시각화할 수 있습니다. 검은색을 0, 하얀색을 1이라고 두고 1에 가까울수록 alignment 점수가 높은 것입니다. 예시는 영어를 프랑스어로 번역한 것인데 alignment가 비교적 단조로운(monotonic) 것을 확인할 수 있습니다. 하지만 프랑스어와 영어는 형용사와 명사가 다른 순서로 나타나는데, 아래 예시에서는 모델이 이를 잘 학습한 것을 확인할 수 있습니다. 영어 문장의 European Economic Area가 프랑스어 문장에서는 zone économique européenne으로 번역되었습니다.

다음 예시에서는 soft alignment의 또 다른 강점을 확인할 수 있습니다. 영어 문장의 the man이 프랑스어 문장에서는 l’ homme로 번역되었습니다. hard alignment 모델의 경우 단순히 the를 l’로, man을 homme로 매핑할 것입니다. 하지만 영어에서의 정관사 the에 해당하는 프랑스어는 성별과 단, 복수형에 따라 le, la, l’, les 등 다양하게 번역될 수 있습니다. soft alignment는 이를 고려하여 l’를 번역할 때 man에도 주목한 것을 확인할 수 있습니다.

결론
논문에서는 기존 인코더 - 디코더 기반의 신경망 기계 번역 모델의 한계를 지적하고 새로운 메커니즘을 제안합니다. 인코더에서 입력 문장의 모든 내용을 고정된 차원의 벡터에 매핑하는 과정에서, 정보의 병목 현상이 발생한다는 가설을 수립하고, 모델이 입력 시퀀스와 출력 시퀀스의 alignment를 학습하는 방식을 제안합니다. 새로운 방법을 통해 NMT 모델의 번역 성능을 크게 끌어올렸을 뿐만 아니라, 실제로 긴 문장에 대한 번역 성능 저하가 거의 없음을 통해 가설이 옳았음을 입증하였습니다. soft alignment 모델을 통해 입력 시퀀스와 출력 시퀀스의 각 단어가 연관된 정도를 정량화하기도 하였습니다. 논문에서는 직접적으로 언급하지 않지만, 이는 어텐션 메커니즘(attention mechanism)의 시초이기도 합니다. 논문에서는 놀라운 성과를 소개하며, 마지막에 모델 성능을 한층 더 끌어올리기 위하여 희귀한 단어, 즉 학습 과정에서 unknown 토큰으로 대체되는 단어를 처리할 방법을 마련할 필요성이 있다고 하였습니다.
더 알아볼 내용
인코더에서 annotations가 만들어질 때, BiRNN을 사용하여 특정 단어 주변의 문맥을 학습합니다. 실제로 문장에서 각 단어가 갖는 의미를 이해할 때, 앞 뒤의 문맥을 모두 고려해야 하기 때문에 이러한 접근법은 적절하다고 생각합니다. 하지만 RNN의 고질적인 문제점이 여전히 남아 있는데, 만약 입력 문장에서 서로 멀리 떨어진 단어끼리 매우 강한 상관 관계를 갖는다면 annotations에 그러한 정보가 제대로 담길 수 있을지가 의문입니다. 그리고 실제로 이게 문제가 된다면 어떤 방식으로 해결된 것일지가 궁금했습니다. 현재 가지고 있는 지식으로는 아마 Transformer 아키텍처에서 Self-attention layer가 앞서 언급한 문제점을 개선한 게 아닐까 하는 생각이 듭니다. Query, Key, Value가 입력 시퀀스의 모든 토큰에 대해 병렬적으로 계산되므로 RNN의 문제점 자체는 해결되었을 것이라고 생각합니다. 여전히 남는 의문은, 트랜스포머 또한 위치 임베딩이라는 개념이 적용되는데, 문장 내에서 가까이 있는 단어끼리는 더 큰 연관성이 있다는 것을 전제로 이 개념을 도입한 것인지, 아니면 다른 어떠한 이유가 있는 것인지에 대해서는 관련 논문이나 개념을 조금 더 깊이 있게 학습하며 알아봐야 할 것 같습니다.




댓글