
이전에 리뷰한 논문, How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings의 레퍼런스 중 하나인 What do you learn from context? Probing for sentence structure in contextualized word representations를 리뷰해 보았습니다. 이전 논문에서 워낙 요구하는 배경지식이 많았고, 백지 상태로는 이해하기 어려운 개념들이 많아서 추가로 읽어보았는데, 오히려 새로운 궁금증만 잔뜩 안고 가는 느낌이었습니다. 아직 많은 논문을 읽어본 것은 아니지만 Embedding에 관한 논문은 특히 모델 아키텍처를 low-level까지 깊게 파고들고, 전통적인 자연어 처리나 언어론의 개념을 많이 요구하는 것 같습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
Overview
사전학습된 단어 임베딩은 자연어 처리 문제를 위한 매우 중요한 도구입니다. 이 모델은 동시출현에 대한 통계(co-occurence statiscis)와 레이블이 없는 데이터로 학습되어, 단어에 대한 연속적인 벡터 표현을 제공하고 넓은 분야에 걸친 NLP의 다양한 다운스트림 태스크에서 일반화 성능을 향상시켜 줍니다. 최근에는 각 단어에 대해 하나의 고정된 벡터를 매핑하는 대신 문맥에 따라 다른 단어 임베딩을 생성하는 모델이 여럿 생겨났습니다. 이 모델은 LSTM이나 Transformer로 이루어진 인코더를 사용하여 각 토큰에 대한 contextual embedding을 생성합니다. 이러한 모델은 기존의 단어 임베딩 방식과 인터페이스가 유사하여, 어떤 모델에서도 drop-in replacement로써 잘 동작합니다. 여기서 drop-in replacement는 대체하였을 때 별도로 설정을 바꿀 필요가 없고, 성능 저하도 없으며 오히려 속도나 안정성 등의 성능이 올라가는 대체물을 의미합니다. Contextual Embedding을 적용한 모델은 문장 성분 분석(constituency parsing), 의미역 분석(semantic role labeling), 상호참조(coreference)등 여러 분야에서 눈에 띄는 성능 향상을 보였습니다.
여기서 잠깐 앞서 언급한 각 태스크에 대해서 간단하게 설명하겠습니다. 먼저 constituency parsin은 phrase-structure parsing이라고 부르며, 우리말로는 분장 성분 분석 정도로 이해할 수 있습니다. 문장을 constituent parts(sub-phrase)로 나눠서 계층적 트리 구조로 분석하는 것입니다. 예를 들어서 The cat sat on the mat.라는 문장을 분석한다면 다음과 같이 될 것입니다.
여기서 S(Sentence)는 전체 문장을 의미하고 NP와 VP는 각각 명사구(noun phrase)와 동사구(verb phrase)입니다. Det는 지시자(determinater)입니다. Constituency parsing은 흔히 dependency parsing과 구분하여 언급되는 개념입니다. Constituency parsing은 계층적 구조에 집중한다면 dependency parsing은 각 단어의 문법적인 관계를 방향이 있는 그래프로 설명합니다.
다음으로 semantic role labeling은 의미적 역할이나 arguments와 관계된 predicates(주로 동사)를 예측하는 태스크입니다. 바꿔 말하면 문장 내에서 “누가 누구에게 무엇을 했는지”를 결정하는 작업입니다. 여기서 predicates은 항상 그렇지는 않지만, 일반적으로 동사이며 동작, 상태, 진행 과정 등을 나타냅니다. 그리고 arguments는 predicates와 관계되어 어떤 의미적인 역할을 수행합니다. Semantic role은 SRL의 구체적인 프레임워크에 따라 다르지만 일반적으로는 다음과 같은 역할이 있습니다.
여기서 몇 가지만 설명해보면 Agent(A)는 어떤 행위를 하는 사람이고 Theme(T)은 그 행위의 영향을 받는 개체이며 Goal(G)는 그 행동을 하는 대상을 의미합니다. 예를 들어 John gave Mary a book.(John이 Mary에게 책을 주었다.)이라는 문장을 살펴보겠습니다. Predicate은 주다 라는 뜻의 gave가 될 것이고 Agent는 John입니다. 앞의 설명으론 명확하게 이해하기 어려웠지만, 주다라는 행위의 대상인 Goal은 Mary이고, 그 행위에 영향을 받는 대상인 Theme은 a book이 됩니다. SRL은 결국 이런 라벨링을 자동으로 수행하는 태스크입니다.
마지막으로 coreference(상호참조)는 두개 이상의 문장에서 같은 개체를 참조하고 있는 현상을 의미합니다. 상호참조의 예시로는 다음과 같은 것들이 있습니다.
대명사 상호참조(Pronominal coreference)
Alice went to the part because she wanted to play.
이 문장에서는 she가 Alice를 참조하고 있습니다.
명사 상호 참조(Nominal coreference)
The CEO of the company annouced the new policy. The executive emphased its importance.
이 문장에서는 The executive라는 명사가 The CEO of the company를 참조합니다.
정관사 명사구(Definite noun phrase)
A dog was barking loudly. The dog seemed agitated.
이 문장에서 The dog은 A dog를 참조하고 있습니다.
문장이 중의성을 갖거나, 상호참조하는 개체간의 거리가 멀거나, 인간에게는 상식이어서 문맥 내에서 별도로 설명되지 않는 경우 등 여러 문제점들 때문에 상호참조해결은 매우 어려운 태스크입니다.
다시 논문의 내용으로 돌아와서, 저자는 contextual representation이 contextual word embedding(일반적으로 Word2Vec, GloVe, FastText와 같은 정적 임베딩)보다 뛰어난 성능을 보여주는 상황이 어디인지를 연구하고자 하였습니다. 당시에는 형태소 태깅(part-of-speech tag), 형태론(morphology), 단어 의미 명확화(word-sense disambiguity)와 같은 태스크에서 토큰 단계에서의 이러한 contextual representations의 능력에 대해 많이 연구되었습니다. 저자는 이런 연구에서 나아가 구문론, 의미론, 국소 또는 장거리 현상(local and long-range phenomena)에 걸쳐 넓은 범위의 태스크를 다루는 edge probing이라는 개념을 도입하였습니다. 특히 저자는 각 위치에서 어떤 정보가 인코딩되는지, 그리고 문장 구조를 이해하여 문장 내에서 단어의 역할을 잘 인코딩하는지에 대해서 집중적으로 연구합니다. 이런 구문론적인 정보가 내재된 것인지, 아니면 벡터 표현이 이러한 고수준의 의미적 관계를 잘 인코딩했는지에 대한 질문의 답을 찾아갑니다. 그리고 인코더가 국소적인 정보만을 파악하는지 아니면 긴 범위에 걸친 구조(long-range structure)도 잘 이해하는지를 탐구합니다.
이러한 질문들에 저자는 사전학습된 인코더의 고정된 contextual embedding을 사용한 probing model을 통해 답을 찾습니다. 이 모델은 predicate-argument 쌍과 같이 주어진 범위에 대한 임베딩에만 접근할 수 있으며 일반적으로는 문장 전체에 대한 문맥이 필요한 semantic role과 같은 특성들을 예측해야 합니다. 저자는 제안한 edge probing이라고 명명하였습니다. 이 기법은 구조화된 작업을 그래프의 여러 엣지로 분해하고 공통 분류기 아키텍처를 사용하여 독립적으로 예측할 수 있습니다.
Edge Probing
저자는 실험을 위해서 여러 태스크에서 사용할 수 있는 일관된 지표(uniform set of metrics)와 아키텍처의 필요성을 느끼며, edge probing 프레임워크를 정의하였습니다. 이 프레임워크는 일반적으로 사용할 수 있고 문장의 일부에 대한 고정된 레이블이 있는 그래프로 표현될 수 있는 모든 태스크에 적용할 수 있습니다. 이 부분에 대한 원문의 표현은 can be applied to any task that can be represented as a labeled graph anchored to spans in a sentence인데, 원문을 함께 읽으면 의미가 조금 더 명확해질 것입니다.
Formulation
문장을 토큰의 리스트 T=[t0,t1,…,tn]이라고 표현하고, 레이블이 있는 엣지를 s(1),s(2),L라고 하겠습니다. s(1)=[i(1),j(1)), s(2)=[i(2),j(2))로 정의합니다. 문장 성분에 대한 라벨(constituent label) 같이 엣지가 하나(unary edge)만 있는 경우에는 s(2)가 생략됩니다. L은 태스크에 따라 다른(task-specific) 레이블의 집합인 L에 유래한 0개 또는 더 많은 타겟의 집합입니다. 모든 태스크를 하나의 분류 모델로 치환하기 위해서, 각 태스크의 레이블을 예측하는 버전(labeling version)에 집중하였습니다. Span이 입력으로 주어지고, 모델은 L을 멀티레이블 타겟으로 예측해야 합니다. 언급했듯이 이는 각 태스크에 대한 접근법 중 일부에 불과합니다. 따라서 저자가 사용하는 지표는 식별(identification)과 레이블링을 동시에 수행하는 모델과 비교하는 데 사용하기에는 부적절합니다. 하지만 이 연구는 적용이 아니라 분석에 집중하기 때문에 labeling version을 사용하는 게 적절하다고 하였습니다. 왜냐하면 이 접근법은 binary F1 score를 사용하여 어떤 현상에 대해서 면밀하게 연구하고 일관되게 평가할 수 있기 때문입니다.
Tasks
논문에서는 8개의 핵심적인 NLP 태스크로 실험을 진행하였습니다. 하나씩 설명해보겠습니다.
Part-of-speech tagging (POS)
형태소 태깅은 통사론과 관련된 태스크로 각 토큰에 명사, 동사, 형용사 등의 태그를 붙이는 작업입니다. s1=[i,i+1)을 하나의 토큰으로 정의하고 POS 태그를 예측합니다.
Constituent Labeling
문장 성분 분석은 조금 더 일반적인 태스크로 일정 범위의 토큰(span of tokens)에 non-terminal 레이블을 부여하는 작업입니다. 여기서 non-terminal은 앞에서 언급했듯 constituent labeling은 트리 구조로 문장 성분을 분석하는 작업인데, 이 트리의 노드가 두 번 이상 세분화될 수 있기 때문에 non-terminal이라는 표현이 사용되었습니다. 예를 들어 어떤 span이 명사구인지, 동사구인지 등을 판단한 후 다시 한번 동사인지, 지시자인지로 나눌 수 있습니다. 즉, s1=[i,j)이 어떤 문장 성분에 해당하는지 예측합니다.
Dependency Labeling
문장 성분 예측과 비슷하지만 span of tokens의 위치에 집중하기보다는 한 토큰과 다른 토큰의 관계에 주목합니다. 앞서 언급했듯 constituent labeling과 자주 함께 등장하는 개념입니다. 예를 들어서 문장 내의 두 토큰이 주어, 목적어 관계를 갖는지를 예측하는 작업입니다. s1=[i,i+1)을 하나의 토큰으로 정의하고 s2=[j,j+1)를 이 토큰의 syntatic head로 정의하여, i와 j 두 토큰의 의존적 관계를 예측합니다. 여기서 syntatic head는 전체 문장의 의미를 결정하는 중심 단어를 의미합니다. 문장 내 다른 단어는 dependents라고 불리며 문법적 또는 의미적 정보를 추가로 제공하여 head에 종속된 것으로 간주됩니다. 예를 들어 She reads books라는 문장에서, reads라는 동사는 전체 문장의 syntatic head가 됩니다. She와 books는 reads에 종속된 dependents입니다.
Named Entitiy Labeling
개체명 예측은 주어진 개체가 속하는 범주를 예측하는 작업입니다. 예를 들어 개체가 사람을 의미하는지, 장소인지, 또는 기관인지 등을 예측합니다. Entity span을 s1=[i,j)로 정의하며 개체가 어떤 유형에 속하는지를 예측합니다.
Semantic Role Labeling (SRL)
Predicate-argument 관계를 분석하는 작업입니다. 예를 들어 Mary pushed John이라는 문장이 있을때, SRL은 Mary를 pusher로 John을 pushee로 구분하는 작업을 말합니다. s1=[ii,j1)은 predicate을 의미하고 s2=[i2,j2)는 해당 predicate에 대한 argument를 의미할 때, s2의 역할을 예측합니다. 예를 들어서 ARG0(agent, the pusher)와 ARG1(patient, the pushee)의 관계를 예측합니다.
Coreference
상호 참조는 서로 다른 spans of tokens이 같은 개체를 언급하고 있는지를 결정하는 작업입니다. s1와 s2에 대해서 상호참조가 발생했는지에 대한 이진 분류를 수행합니다.
Semantic proto-role (SPR)
Predicate-argument 쌍의 change_of_state나 awareness와 같이 세밀하고 비독점적인 의미론적 속성을 예측하는 작업입니다. 예를 들어서 Mary pushed John이라는 문장에서 SRL은 Mary를 pusher로 인식했다면 SPR은 pusher가 자신이 push라는 행동을 하고 있다는 것을 인지한 상태인지를 판단합니다. s1을 predicate span으로 s2는 argument head로 정의하고, multi-label 분류를 수행합니다.
Relation Classification (Rel.)
관계 유형에 대한 정보가 주어졌을 때, 두 개체의 관계를 예측하는 작업입니다. 예를 들어서 Mary is walking to work.라는 문장에서 이 태스크는 Mary와 work를 연결하여 Entity_Destination 관계로 분류합니다. s1와 s2 각각을 개체라고 생각하여 두 개체의 관계를 예측합니다.
Datasets
8개 중 5개의 태스크, POS tags, constituents, named entities, semantic roles, coreference 태스크에 OntoNotes 5.0 corpus 데이터를 edge probing 형식으로 치환하여 사용하였습니다. POS tagging의 경우 단순히 OntoNotes의 constituency parsse data에서 레이블을 추출하였습니다. Coreference는 OntoNotes가 상호참조가 존재하는 데이터(positive sample)만을 제공하기 때문에, negative sample을 생성하여 사용하였습니다. 나머지 세 개의 태스크에서는 English Web Treebank을 사용하였습니다.
Experimental Set-up
Probing Model
프로빙 모델의 아키텍처는 다음과 같습니다. 이 모델은 contextual embedding에서 어떤 정보를 추출할 수 있는지에 집중하도록 설계되었습니다. Contextual vectors [e0,e1,…,en]과 정숫값을 갖는 span s(1)=[i(1),j(1))과 선택적으로 s(2)=[i(2),j(2))를 입력으로 받아서 projection layer를 지나고, 이어서 self-attention pooling 연산을 통해 고정된 길이의 span에 대한 벡터 표현을 계산합니다. 풀링(pooling)은 벡터 [ei,ei+1,…,ej−1]와 같이 어떤 span의 범위 내에서만 수행되며, 이는 모델이 문장의 나머지 부분에 대해 직접 접근할 수 있는 유일한 정보입니다. 그러나 contextual embeddings 덕분에, 문장의 전반적인 맥락에 대한 정보는 여전히 포함되어 있습니다.
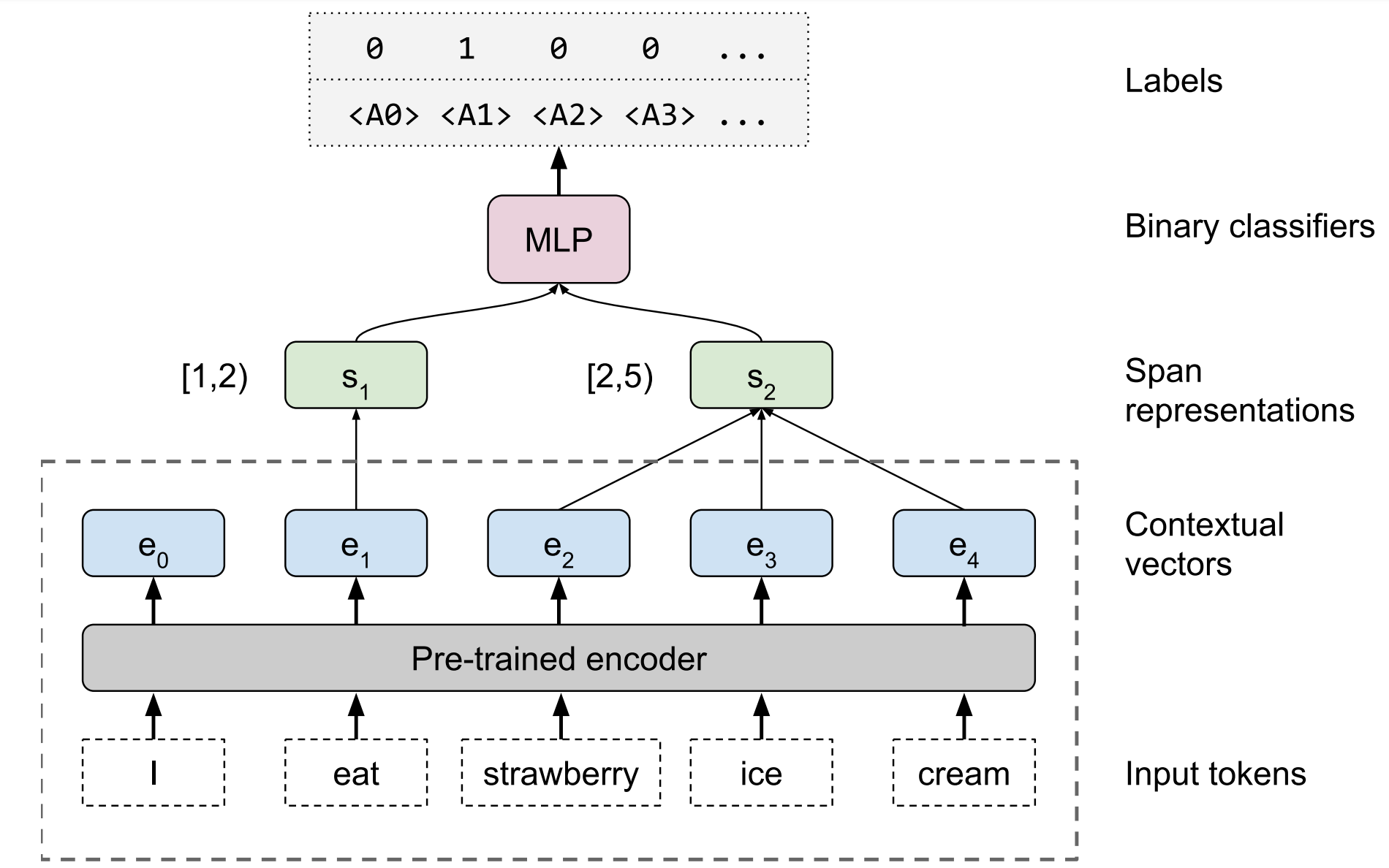
Span representations은 연결(concatenate)되어 두 개의 레이어를 갖는 MLP에 주입된 후, 시그모이드 레이어를 거칩니다. 모델은 타겟 레이블의 집합인 L∈0,1|L|에 대하여 binary cross-entropy를 최소화하는 것을 목표로 훈련합니다.
Sentence Representation Models
저자는 CoVe, ELMo, OpenAI GPT, BERT로 총 네개의 contextual encoder를 갖는 모델을 탐구하였습니다. 각 모델은 토큰의 리스트 [t0,t1,…,tn]을 입력으로 받아 contextual vectors의 리스트 [e0,e1,…,en]을 출력합니다.
CoVe는 영어-독일어 번역으로 훈련된 두 층의 biLSTM의 최종 레이어 출력을 사용합니다. 이 출력값은 300차원의 GloVe 벡터와 결합됩니다.
ELMo는 문맥을 고려하지 않는 글자 단위의 연산을 수행하는 CNN 레이어와 두 층의 양방향 LSTM을 사용하여 Billion Word Benchmark dataset으로 훈련된 언어모델입니다.
GPT는 Toronto Books Corpus로 문장 생성 언어 모델로써 학습된 12개의 트랜스포머(Transformer) 기반의 레이어를 갖는 인코더입니다. 원래는 트랜스포머의 디코더를 사용한 모델이지만, 여기서는 contextual embeddings를 사용했다는 점에서 인코더라는 표현으로 통일한 것으로 보입니다.
BERT는 Toronto Books Corpus와 English Wikipedia를 사용하여 maksed language modelling과 다음 문장 예측 태스크를 통해 학습된 트랜스포머 인코더입니다.
BERT와 GPT를 비교하기 위해서 다음 각각의 토큰에 대한 contextual embeddings를 생성하는 두 가지 방법을 사용하였습니다. 먼저 cat 토큰은 CoVe와 같이 서브워드 임베딩을 마지막 층의 출력과 연결하고 mix 토큰은 EMLo와 같이 임베딩을 포함한 레이어들의 출력에 선형 결합을 수행합니다.
결과적으로 contextual vector는 CoVe에서 d=900 차원을 갖고, ELMo는 d=1024, GPT와 BERT-base는 d=1536 (cat), d=768 (mix) 차원을 갖습니다. 사전훈련된 각 모델은 서로 다른 토큰화 기법과 입력에 대한 처리 방식을 갖습니다. 각 모델이 기대하는 방식에 따라 원본 데이터를 토큰화하기 위해서 byte-level에서 Levenshtein distance에 기반하여, heuristic alignment 알고리즘을 사용합니다. 이에 대해서 Appendix E의 일부를 가져와 조금 더 자세히 설명해보겠습니다.
CoVe는 Moses tokenization을 GPT와 BERT는 subword model을 사용합니다. 따라서 Levenshtein distance에 기반한 heuristic project를 사용한 새로운 토큰화 기법을 통해 spans를 정렬합니다. 레벤슈타인(Levenshtein) 거리는 문자열의 유사도를 정량화하는데 편집 거리라고도 부릅니다. 두 문장이 같아지기 위해서 글자 단계에서 삽입, 삭제, 대체 연산을 수행하는 최소 횟수를 측정합니다. 예를 들어서 kitten와 sitting이라는 두 단어를 생각해보겠습니다.
kitten의 k를 먼저 s로 대체합니다. 그 다음 sitten의 e를 i로 대체하여, sitting으로 만듭니다. 마지막으로 g를 추가하면 sitting이 됩니다. 따라서 총 3번의 변형이 가해졌고, 레벤슈타인 거리는 3이 됩니다.
Probing 태스크를 위한 원천 데이터는 각자 특정한 토큰화 기법에 따라서 다르게 표기되어 있습니다. 이러한 방식은 항상 사전 학습된 representation 모델의 토큰화 방식과 일치하지는 않습니다. 예를 들어서 다음과 같은 문장을 생각해보겠습니다.
Text: I don’t like pineapples.
Native: I do n’t like pineapples .
Moses: I do n 't like pineapples .
Subword: _i _do _n’t _like _pinea _pples .
pineapples에 대한 표현이 natvie와 같은 원래 tokenization에서는 s=[4,5)로 표현되겠지만, Moses tokenization에서는 sMoses=[5,6)에 해당하고, Subword 모델에서는 ssubword=[5,7)에 해당합니다.
저자는 이러한 aligning 문제를 해결하기 위해서 레벤슈타인 거리를 사용했습니다. Source tokenization [s0,s1,…,sm]이 주어졌을 때, target tokenizer을 문자열 ˜S를 토큰의 리스트인 [t0,t1,…,tn]로 매핑하는 블랙박스 함수로 생각합니다. 여기서 앞에서 토크나이저의 차이를 보았듯이, n과 m은 일반적으로 같지 않습니다.
원본 문자열 ˜S라고 할 때, [t0,t1,…,tn]를 공백과 함께 연결하여 타겟 문자열 ˜T을 만든 후 바이트 단위에서 Levenshtein alignment ˜A=Align(˜T,˜S)를 계산합니다. 그 후 token-to-byte alignments인 U=Align([t0,t1,…,tn],˜T)와 V=Align([s0,s1,…,sm],˜S)를 계산합니다. 이 alignemtns를 boolean adjacency 행렬로 표현하고, token-to-token alignment인 A=U˜AVT로 변환합니다.
마지막으로 각 source span의 값을 1은 span 내부, 0은 span 외부로 하는 불리언 벡터로 표현합니다. 예를 들어 [2,4)=[0,0,1,1,0,0,…]∈0,1m입니다. 그리고 이 벡터를 alignment A로 투영합니다.
Experiments
이 논문에서 결국 답을 얻고자 하는 문제는 단어 임베딩과는 다르게 contextual representations가 인코딩하는 정보는 무엇인가? 입니다. 따라서 모델이 어떻게 다양한 유형의 언어적 정보를 포착하는지를 밝혀내기 위해서, 비교 실험은 contextualized encoders의 다양한 측면을 분석하기 위해 설계되었습니다. 논문에서는 ablate이라는 어휘를 사용하는데, 이 어휘는 직역하면 제거, 절제 등의 의미를 갖습니다. 하지만 이런 맥락에서 ablate 또는 ablation study는 어떤 실험에 영향을 미치는 다양한 요소 중 하나를 제거하였을 때, 실험 결과가 어떻게 변하는지를 관찰하는 것을 의미합니다. 즉 이 맥락에서는 contextualized encoders의 다양한 측면을 각각 분리하여 면밀히 살피겠다는 의미입니다.
Lexical Baselines.
각 contextual encoder의 영향을 조사하기 위해서 probing model을 closely related context-independent word representations으로 훈련하였습니다. 문맥에 독립된 단어 표현의 예시로는 GloVe나 FastText가 있을 것입니다. 이 기준(baseline)은 주변 단어가 주어지지 않고 오직 lexical prior만으로 달성할 수 있는 성능을 측정합니다. Lexical prior은 어떤 단어에 대한 문맥이나 문장 구조가 주어지지 않아도 알 수 있는 정보를 의미합니다. 예를 들어서 hospital이라는 단어만 독립적으로 주어져도 사람들이 아프거나 다쳤을 때 가는 곳, 의사와 간호사가 일하는 곳 등의 정보를 알고 있습니다. 이러한 일반적인 상식을 lexical prior이라고 합니다. CoVe와는 300차원의 GloVe 벡터로 이루어진 임베딩 레이어와 비교하였고, ELMo와는 문맥에 독립적인 CNN 레이어의 출력과 비교하였습니다. GPT와 BERT 모델은 서브워드 임베딩을 사용하였습니다.
Randomized ELMo.
Randomized neural network는 당시 여러 태스크에서 놀라울정도로 강력한 성능을 보여주었는데, 이는 아키텍처가 유용한 특성 함수(feature functions)을 학습하는데 중요한 역할을 할 것임을 의미합니다. 인코더가 사전학습 과정에서 실제로 어떤 것을 배우는지 이해하기 위해서, 저자는 lexical layer(layer 0)의 모든 가중치를 임의의 직교 행렬(random orthonormal matricies)로 대체한 ELMo 모델의 버전과 비교하였습니다.
Word-Level CNN.
Contextual encoder는 국소적인 문맥을 모델링하는 것에 비해서 장거리 의존성(long-range dependency)은 어느 정도까지 학습할까요? 저자는 너비가 고정된 CNN을 도입하여 lexical baseline을 확장하였습니다. Lexical baseline이 단어 수준의 prior을 분리해낸다면, CNN baseline은 근처에 있는 문법 형태소와 같이 국소적인 관계(local relationship)을 분리해내어, 장거리의 문맥이 인코더 성능에 어떤 영향을 미치는지 알 수 있게 해줍니다. 이를 구현하기 위해서 저자는 제안한 probing model의 projection layer를 중심 단어에서 ±1또는 ±2 토큰까지 관찰하는 완전 연결된 CNN 레이어로 대체하였습니다.
Results
이제 모든 실험 설계가 끝났습니다. 드디어 각 모델이 각 위치에서 어떤 의미적, 통사적 정보를 인코딩하는지, 그리고 모델은 지역적인 정보만을 포착하는지, 아니면 긴 문장에 걸쳐 흩어져 있는 정보까지 이해하는지를 알 수 있습니다.
Comparison of representation models.
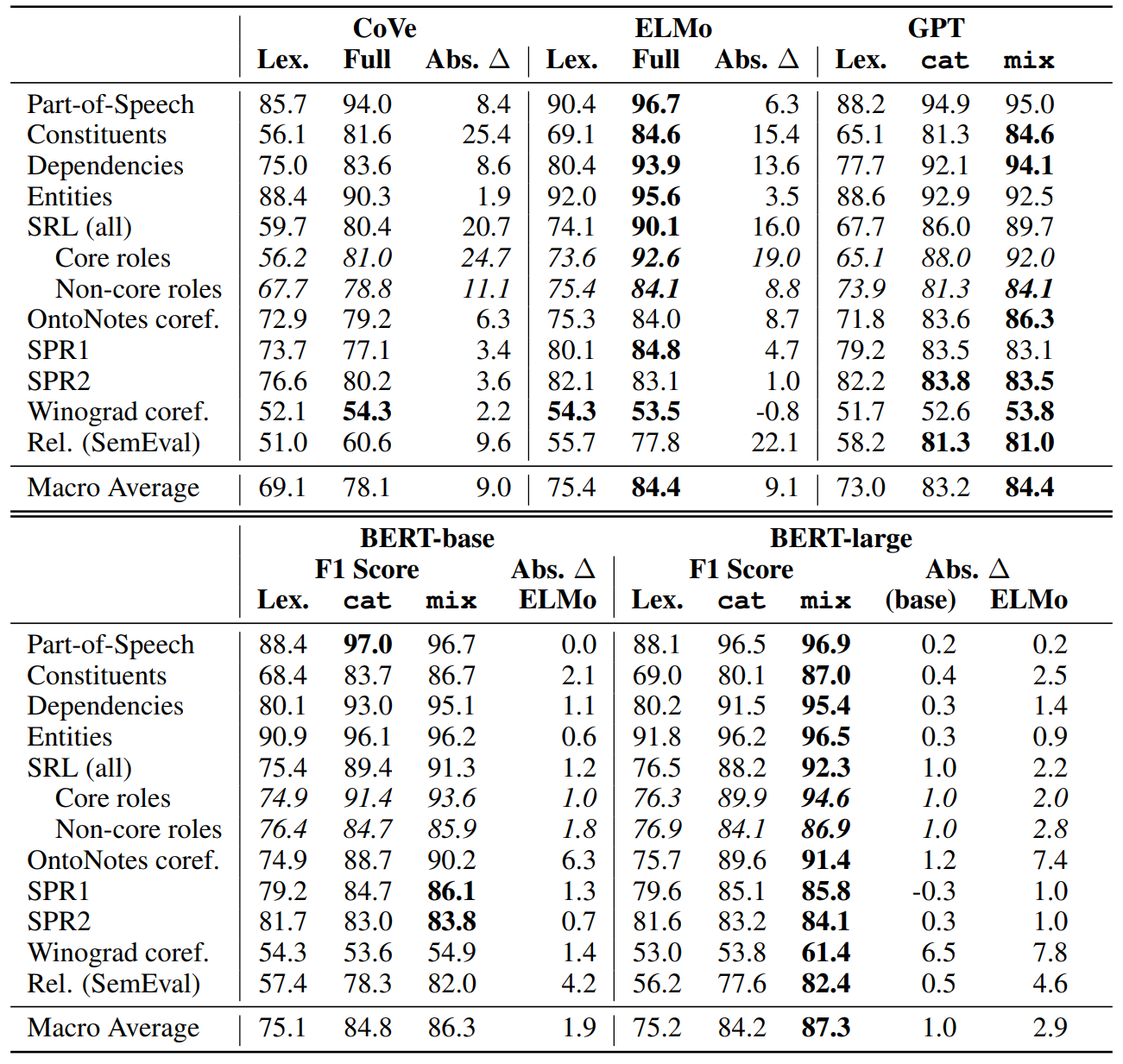
아래 표에서 ELMo, CoVe, GPT, BERT의 F1 점수를 비교할 수 있습니다. ELMo와 GPT는 모두 CoVe와 비교하여 큰 점수차를 보이는데, 이는 두 모델의 단어에 대한 벡터 표현이 CoVe에 비해서 문장 구조에 대한 세부 정보를 더 잘 표현함을 의미합니다. 네 모델은 모두 같은 문제에 사용될 수 있지만, 모두 아키텍처도 다르고, 사전 훈련 목표도 달랐으며, 학습 데이터의 양과 도메이 다르다는 것을 기억해야 합니다. 나아가 Winograd coreference 태스크를 제외하면 ELMo와 GPT 모델은 Glove 벡터의 성능을 각각 평균적으로 5.4점, 2.4점만큼 능가합니다. 이 차이는 문장 성분 분석이나 의미역 예측에서 눈에 띄게 나타나는데, 이는 두 모델이 단어 형태와 구조에 민감한 작업에 특히 유용함을 의미합니다Gen.
Genre Effects.
Probing model 학습 데이터의 대부분은 뉴스와이어나 웹 텍스트를 사용하였습니다. 이는 ELMo 학습에 사용한 Billion Word Benchmark와는 잘 맞지만, GPT 학습에 사용한 Book Corpus와는 잘 맞지 않습니다. 이 영향을 조절하기 위해서 공개된 코드를 사용하여 GPT 모델을 BWB 데이터로 학습시킨 버전을 만들었습니다. 그리고 이 모델이 원래 GPT 모델보다 약간 더 나은 성능을 보임을 발견하였습니다.
Encoding of syntactic vs. semantic information.
Lexical baseline과 비교하여 각 태스크에서 특정한 인코더의 contextual information이 어느 정도의 성능 향상을 가져오는지를 측정했습니다. ELMo, CoVe, GPT 모두 유사한 추세를 보이는 것을 확인할 수 있는데, dependency, constituent labeling과 같이 문장 구조를 고려하는 태스크에서 큰 차이를 보이고, SPR이나 Winograd와 같이 의미를 고려하는 태스크에서는 비교적 작은 차이를 보입니다.
SemEval 관계 분류 태스크는 의미 추론(semantic reasoning) 능력을 요하는데, ELMo는 lexical baseline에 비해서 22점이나 높은 F1 점수를 기록했고, BERT는 추가로 4.6점이 더 높습니다. Lexical baseline이 이 태스크에서 저조한 성적을 기록한 것은 아마 많은 관계 분류 문제가 단순히 문장 내에서 특정 키워드만을 보고 해결할 수 있다는 사실 때문일 것이라고 추정합니다. 예를 들어 caused라는 단어는 Cause-Effect라는 관계를 가짐을 알 수 있게 해줍니다. 이 가설을 검증하기 위해서, lexical baseline을 bag-of-words 특성을 증강하였고, 성능이 눈에 띄게 향상했음을 확인하였습니다.
Effects of architecture.
저자는 ELMo 모델에 대하여, 사전 학습 과정에서 얻은 지식보다, 모델의 아키텍처가 성능에 미치는 영향은 어느 정도인지에 대한 의문을 가졌습니다. 다음 그림은 ELMo와 구조적으로는 동일하지만 recurrent weights에 대한 정보를 가지지 않은 orthonormal encoder과 비교한 결과입니다. Orthonormal encoder가 lexical baseline에 비해서 더 나은 성능을 보이긴 하지만, Full ELMo를 고려하면 전체 성능 향상의 70%는 학습된 가중치에 의한 것임을 알 수 있습니다.
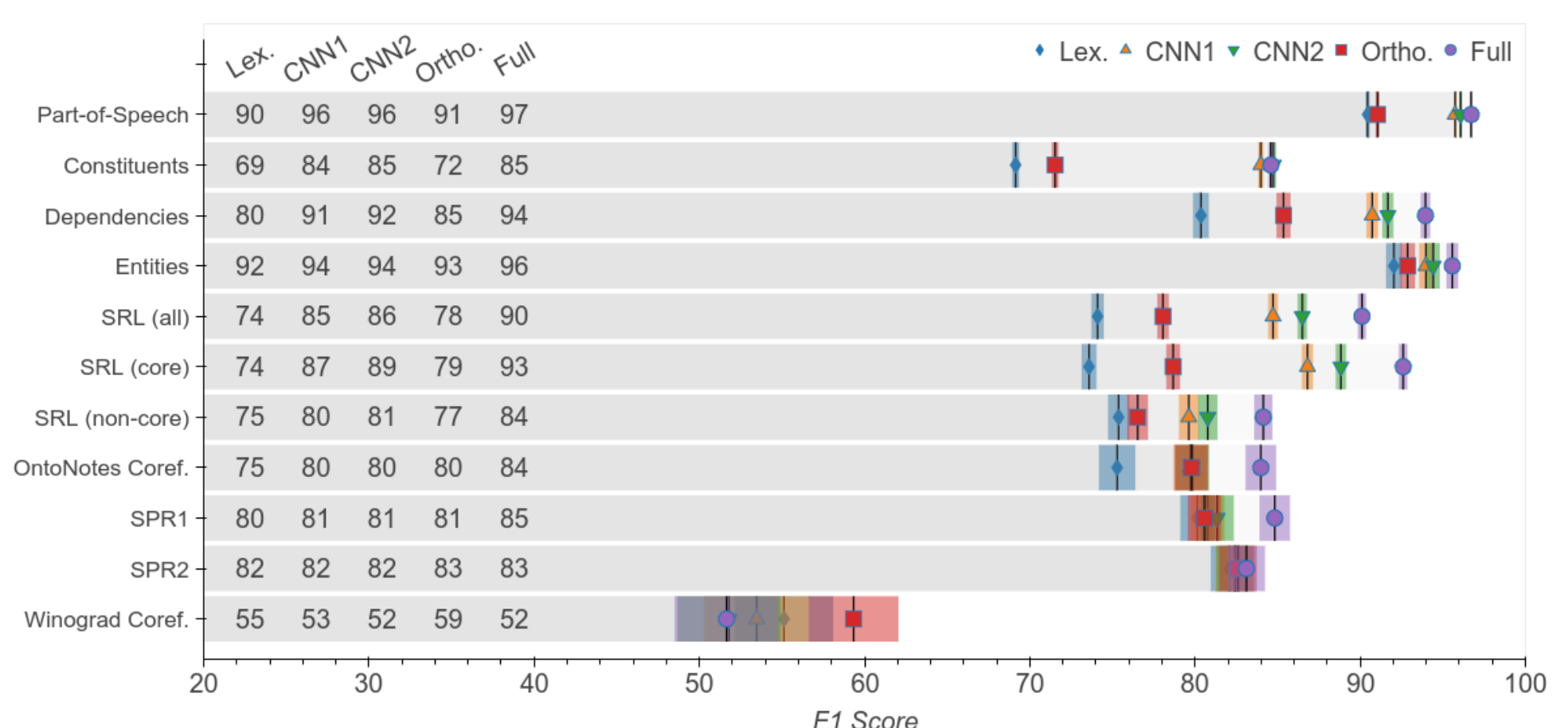
Encoding non-local context.
모델이 긴 거리에 걸쳐 있는 정보를 이해하는지를 측정하기 위해서 lexical baseline을 합성곱 레이어를 사용하여 확장하였습니다. CNN을 사용하는 것은 Full ELMo와 비교했을 때, 성능 차이의 70%를 좁혀주었습니다. CNN의 너비를 5로 하면 성능이 79%나 향상되었습니다. Nonterminal constituents 태스크에서는 CNN ±2 모델이 ELMo의 성능을 따라잡았는데, 이는 ELMo가 문장 성분 분석 태스크를 훌륭히 수행하지만, 이는 지역적인 정보에 대한 이해를 바탕으로 함을 의미합니다. 형태소 태깅, SRL과 같은 다른 구문론적 태스크에서는 CNN 모델이 ELMo에 성능에 약간 미치지 못했습니다. 반대로 상호참조와 같은 의미론적 태스크에서는 ELMo와 CNN 베이스라인의 차이가 큽니다. 결국 ELMo는 장거리 의존성을 학습하는 데서 강점을 갖는다는 것을 알 수 있습니다.
Conclusion
논문에서는 contextualized word embeddings를 연구하기 위해 설계된 edge probing이라는 새로운 태스크를 도입하였습니다. 이러한 태스크는 NLP의 핵심 태스크들에서 유래하였으며, 여러 의미론적, 구문론적 현상을 폭넓게 다룹니다. 이 태스크를 통해 저자는 문맥에 독립적인 lexical baseline에 비해서 contextual embedding이 얼마나 뛰어난 성능을 보이는지를 연구하였습니다.
분석한 내용에 따르면 일반적으로 contextualized embeddings은 non-contextualize embeddings에 비해서 문장 성분 예측과 같은 구문론적 태스크에서 뛰어난 성능을 보입니다. ELMo의 성능은 지역 정보를 포착하는 능력만으로는 설명할 수 없는데, 이는 contextualized embeddings가 장거리 의존성을 효과적으로 포착함을 의미합니다.
Further Thinking
원래는 이전 논문을 더 잘 이해하기 위해서 가볍게 읽어보자는 마음가짐으로 접한 논문이었습니다. 그런데 읽다 보니 오히려 모른다는 사실조차 몰랐던, 모르는 게 너무 많다는 것을 깨닫게 된 논문입니다. 임베딩은 NLP 전반에 걸친 배경지식을 넓게 요구하는 것 같다는 느낌이 들었습니다. 사실 자연어처리 문제를 딥러닝 모델로 풀 수 있게 해준 가장 큰 원인이 임베딩이라는 것을 생각하면 당연하기도 한 것 같습니다. 결국 단어의 의미를 잘 표현하는 벡터를 만드는 것이 자연어 처리 문제 해결의 핵심이자 출발점이기 때문입니다. 안타깝게도 논문의 내용 자체는 깊게 이해하지 못한 것 같지만, 그래도 논문 이곳저곳에 널리 퍼져있는 여러 배경지식들을 찾아보며 많이 공부한 것 같아서 유익했습니다. 나중에 기회가 된다면 논문을 다시 한 번 조금 더 깊게 탐구해보기 위한 시도를 해봐야겠습니다.




댓글