
Contextualized Word Vectors에 대한 개념을 처음으로 도입한 논문, Learned in Translation: Contextualized Word Vectors를 리뷰해보았습니다. 원래 contextualized representations의 시초는 ELMo라고 알고 있었는데, 앞서 몇 개의 논문을 읽다가 CoVe라는 존재에 대해서 알게 되었습니다. ELMo 만큼은 아니지만 그래도 임베딩 관련 논문에서 종종 등장하는 개념인 것 같아서 지나칠 수 없어서 조금 더 깊이 알아보았습니다. 이번 논문은 특히 수식이 많아서 쉽지는 않았지만, 그래도 앞서 리뷰한 두 논문만큼 자연어 처리나 언어학의 뿌리 깊은 곳의 배경지식까지 요구하는 것은 아니었기에 조금 더 편하게 읽은 것 같습니다. 번역을 통해 오히려 이해가 어려워지거나, 원문의 표현을 사용하는 게 원래 의미를 온전히 잘 전달할 것이라고 생각하는 표현은 원문의 표기를 따랐습니다. 오개념이나 오탈자가 있다면 댓글로 지적해주세요. 설명이 부족한 부분에 대해서도 말씀해주시면 본문을 수정하겠습니다.
Overview
전이학습(transfer learning)과 멀티태스크 러닝(multi-task learning)은 시너지를 내는 작업(synergistic tasks)에 대해서 유의미한 성능 향상을 불러왔습니다. 많은 경우에 이러한 시너지는 비슷한 컴포넌트를 갖는 아키텍처에서만 유효합니다. 컴퓨터 비전에서는, ImageNet으로 사전학습된 합성곱 신경망(CNNs)을 사용하여 더 복잡하고 깊은 모델을 초기화하는 것이 사실상의 표준이 되었습니다. 이러한 초기화 방법은 visual question answering(VQA)나 이미지 캡셔닝 등의 연관된 작업에서의 정확성을 향상시킵니다.
자연어 처리에서는 Word2Vec이나 GloVe와 같은 모델로 훈련된 분산 표현을 사용하여 딥러닝 모델의 단어 벡터를 초기화하는 것이 일반적인 방법이 되었습니다. 단어 벡터의 형태로 된 대규모의 레이블이없는 학습 데이터에서 유래한 정보를 전이하는 것은 형태소 태깅, 개체명 인식, 질문 답변과 같은 다양한 분야의 다운스트림 태스크에서 단어 벡터를 임의로 초기화하는 방법보다 더 나은 성능을 보입니다. 하지만 단어가 홀로 나타나는 경우는 거의 없습니다. 문장의 맥락을 포함하여 단어를 벡터로 표현하고 이를 공유한다면 NLP에서 전이학습의 효과가 한층 더 나아질 것입니다.
컴퓨터 비전에서 ImageNet에서 훈련된 CNN이 다른 태스크에 성공적으로 전이되는 것에 영감을 받아서, 저자는 큰 규모의 NLP 태스크에서 인코더를 훈련하고, 또 다른 NLP 태스크로 인코더를 전이하는 방법을 고안하였습니다. 기계 번역(MT)는 디코더에 의해서 다른 언어로 번역될 수 있도록 인코더가 문맥을 고려하여 단어를 인코딩해야 하는데, MT를 위해 설계된 어텐션 메커니즘을 기반으로 한 sequence-to-sequence 모델은 주로 다른 NLP 모델에서도 흔히 사용하는 LSTM 기반 인코더를 갖습니다. 저자는 일반적으로 MT 데이터는 재사용 가능한 모델을 위한 초석으로서 ImageNet에 필적하는 잠재력을 갖는다고 생각했습니다. 결국 NLP에서 MT-LSTM은 컴퓨터 비전의 ImageNet-CNN에 비견할만한 후보가 될 것입니다.
아래 그림처럼 저자는 LSTM 인코더를 여러 기계학습 데이터셋에서 훈련하고 NLP의 다른 태스크를 위해 학습된 모델의 성능을 향상하는데 사용할 수 있다는 것을 검증하였습니다.
인코더의 전이 가능성(transferability)을 테스트하기 위해서, 저자는 다양한 분류 태스크에 공통적으로 사용할 수 있는 아키텍처를 개발하였고, 질문 답변 태스크를 위해서는 Dynamic Coattention Network를 변형하여 사용하였습니다. 이러한 모델의 일반적인 입력으로 사용되는 단어 벡터에 context vectors(CoVe)라고 부르는 MT-LSTM의 출력을 추가하였습니다. 이런 방법은 사전학습된 단어 벡터만을 사용한 베이스라인 모델에 비해서 다운스트림 태스크에서 모델의 성능을 향상시켰습니다. Standford Sentiment Treebank(SST)와 Standford Natual Language Inference Corpus(SNLI)에서 CoVe는 기본 모델의 성능을 최고 수준(state-of-the-art)으로 끌어올렸습니다.
실험 과정에서 MT-LSTM 학습에 사용한 학습 데이터의 양은 다운스트림 태스크에서의 성능과 양의 상관관계를 가짐을 발견하였습니다. MT 데이터는 대부분의 다른 지도형 NLP 태스크에 비해서 더 풍부하다는 점에서 이것은 MT에 의존하는 것의 또 다른 장점입니다. 그리고 이는 더 높은 품질의 MT-LSTM이 더 유용한 정보를 전달한다것을 의미합니다. 이러한 사실은 기계 학습이 뛰어난 자연어 이해 능력을 갖는 모델에 대한 후속 연구를 위한 적합한 후보자라는 아이디어를 뒷받침합니다.
Related Work
Transfer Learning
전이학습, 또는 도메인 적응(domain adaptation)은 독립적으로 수집한 데이터셋 사이에 시너지 관계가 있는 여러 분야에 적용되었습니다. Saenko는 하나의 도메인을 위해 개발된 객체 인식 모델을 도메인에 의한 특징 분포의 변화를 최소화하는 변환을 학습하여 새로운 imaging conditions에 맞게 조정하였습니다. NLP에서 Collobert는 비지도 학습으로 훈련한 벡터 표현을 사용하여 개체명 인식, 형태소 태킹, 청킹(chunking)과 같은 지도 학습 태스크의 성능을 개선하였습니다. NLP의 당시 연구는 이처럼 사전학습된 단어 벡터를 사용하여 추론(entailment), 감성 분석, 요약, 질문 답변과 같은 모델의 성능을 향상하는 방향으로 계속해서 연구하였습니다. Ramachandran은 sequence-to-sequence 모델을 사전학습된 언어 모델로 초기화하고 특정 태스크로 파인튜닝하는 방법을 제안했습니다. Kiros는 주변 문장을 예측하는 문장 벡터를 출력하는 비지도 학습법을 제안했습니다. 저자도 마찬가지로 단어 벡터보다 높은 수준의 representations을 전이하는 방법을 제안하는데, 앞의 방법과는 다르게 지도 학습을 사용하여 문장 인코더를 훈련하고 파인튜닝 없이 텍스트 분류나 질문 답변을 위한 모델의 성능이 개선됨을 입증하였습니다.
Nueral Machine Translation
전이 학습의 source domain은 당시 신경망 기계 번역의 출현과 함께 성능이 크게 향상된 기계 번역(machine translation, MT)입니다. Sutskever은 2014년에 기계번역을 위한, 신경망을 사용한 인코더-디코더 구조의 sequence-to-sequence 모델을 연구하였습니다. Bahdanau는 2015년, 어텐션 메커니즘을 사용하여 sequence-to-squence 모델을 개선하였는데, 이 모델에서 디코더가 시퀀스 생성의 각 단계에서 매번 인코더의 벡터 표현을 사용합니다. Luong은 2015년 후속 연구를 통해 기계 번역 태스크에서 여러 어텐션 메커니즘에 대해 연구하였습니다. 어텐션 메커니즘은 추론, 요약, 질문 답변등 여러 NLP 태스크에도 성공적으로 적용되었습니다. 이 연구에서도 NMT를 위해 훈련한 인코더가 다른 NLP 태스크에 잘 전이됨을 입증합니다.
Transfer Learning and Machine Translation
기계 번역은 원본 언어의 문장의 정보를 잃지 않고 대상 언어로 충실히 재현해야 하는 태스크이기 때문에, 본질적으로 전이 학습의 source domain으로 적합합니다. 게다가 MT는 전이학습에 사용할 수 있는 데이터도 풍부합니다. Hill은 2016년 여러 source domain에서 의미 유사도(semantic similarity) 측정 태스크로의 전이학습의 효과에 대해 연구하였습니다. 후속 연구를 통해 NMT 인코더를 통해 얻은 고정된 차원의 representations의 성능이 semantic similarity 태스크로 단일 언어를 사용하여 학습된 인코더의 representations보다 뛰어나다는 것을 발견하였습니다. 이전 연구와 다르게 저자는 NMT 인코더의 고정된 차원의 벡터 표현을 사용하지는 않습니다. 대신, 입력 시퀀스의 각 토큰에 대한 벡터 표현을 전이합니다. 이 방식은 학습된 인코더가 후속 LSTM, 어텐션 메커니즘, 일반적으로 시퀀스를 입력받는 레이어에 잘 호환되도록 합니다.
Machine Translation Model
인코더를 다른 태스크에 잘 전이하기 위해서 어텐션에 기반한 seq2seq 모델을 영어-독일어 번역을 위해서 학습하는 것으로 시작합니다. 원본 언어의 단어 시퀀스 wx=[wx1,…,wxn]와 타겟 언어의단어 시퀀스 wz=[wz1,…,wzm] 주어진 상황을 가정합니다. GloVe(wx)를 단어 wx에 대응하는 GloVe 벡터의 시퀀스라고 하고, z는 단어 wz에 대하여 임의로 초기화된 단어 벡터의 시퀀스라고 하겠습니다.
GloVe(wx)를 두 개의 레이어를 가진 양방향 LSTM에 주입합니다. 나중에 전이에 사용할 사전 학습된 인코더가 BiLSTM과 같이 두개의 레이어를 가진다는 것을 나타내기 위하여 MT-LSTM이라고 명명하였습니다. MT-LSTM은 다음과 같은 수식으로 은닉 상태(hidden state)를 계산합니다.
기계 번역에서 MT-LSTM은 어텐션 기반의 디코더에 각 타임스텝에서 출력 단어의 분포 p(ˆwzt|H,wz1,…,wzt−1)을 생성하기 위한 문맥을 제공합니다.
타임스텝 t에서 디코더는 먼저 두 레이어를 가진 단방향 LSTM을 사용하여 이전 타임스텝의 타켓 임베딩 zt−1과 문맥에 대해 조정된(context-adjusted) 은닉상태 ˜ht−1를 통해 hdect을 생성합니다.
그 후 디코더는 각 타임스텝의 인코딩된 벡터와 현재 디코더의 상태를 연관짓는 어텐션 가중치 α의 벡터를 계산합니다. 여기서 H는 h의 각 원소를 시간 차원으로 쌓은(stacked) 벡터를 의미합니다.
디코더는 이 가중치를 가중합을 계산할 때 계수로 사용하고, 이 값은 디코더 상태와 연결된 후 tanh 레이어를 통과하여 문맥에 의해 조정된 은닉 상태인 ˜h를 만듭니다.
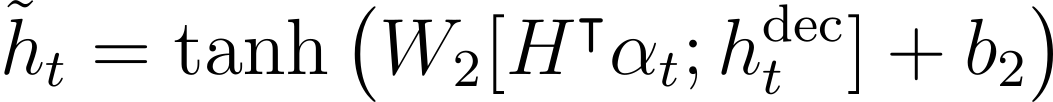
출력 단어에 대한 분포는 context-adjusted hidden state의 마지막 변환에 의해 다음과 같이 생성됩니다.
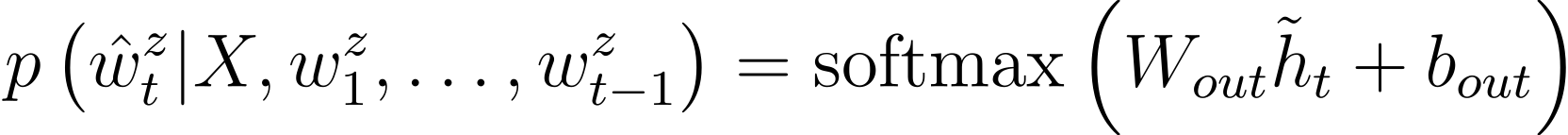
상당히 많은 수식이 나열되었는데, 수식의 의미를 다시 한번 파악해보겠습니다. 결국 핵심은 인코더-디코더 구조를 갖는 모델을 훈련한 후 이 언어에 대한 학습이 잘 된 인코더를 전이학습에 사용하고자 하는 것입니다. 여기서 모델은 영어-독일어 번역을 수행하며 학습합니다. 먼저 (1)번 식는 입력 문장의 각 단어를 GloVe의 임베딩을 사용하여 벡터로 변환합니다. 그리고 이 벡터화된 입력 문장을 MT-LSTM에 주입하여 은닉 상태 h를 얻습니다. LSTM은 기본적으로 RNN을 기반으로 하므로 매 타임스텝마다 새로운 토큰을 입력받고, h를 갱신할 것입니다. 이때, 매 타임 스텝마다 갱신되는 h를 모은 것이 H입니다.
기계번역 태스크에서 MT-LSTM의 디코더는 인코더에서 생성한 H와 이전 단계까지 생성된 각 단어 벡터인 wz1,…,wzt−1를 바탕으로 이번 타임 스텝에 생성할 단어 ˆwzt에 대한 확률 분포를 계산하는 것이 최종적인 목표입니다.
이를 위해서 먼저 타임스텝 t마다 디코더는 두 레이어를 가진 단방향 LSTM을 사용하여 hdect을 생성합니다. (2)번 식을 들여다보면, 이 은닉 상태는 LSTM에 이전 타임스텝까지 생성된 정보를 벡터화한 타겟 임베딩과 뒤에서 계산할, 문맥에 따라 조정한 이전 타임 스텝의 은닉 상태를 주입하여 계산하는 것을 알 수 있습니다. 쉽게 생각하면, 일반적인 RNN에서와 같이 이전 타임 스텝까지의 예측값과 이전 타임 스텝의 은닉 상태를 입력 받아 이번 타임 스텝의 은닉 상태를 생성한다는 것입니다. 하지만 여기서는 이 공식을 조금 변형하여, 예측과 은닉 상태를 계산하는 방법을 바꿨습니다.
이후 (3)번 식에서 디코더는 인코더의 각 타임스텝의 은닉 상태와 디코더의 이번 타임 스텝의 은닉 상태를 계산하여 일종의 어텐션 가중치를 만듭니다. 어텐션 메커니즘의 핵심은 입력과 출력 시퀀스의 관계를 정량화하는 것인데, 이러한 맥락에서 이번 타임 스텝의 출력이 인코더의 각 타임 스텝의 출력과는 어떤 관계를 갖는지 확인하겠다는 의미입니다.
이제 (4)번 식에서 이 가중치를 바탕으로 가중합을 계산합니다. 즉 인코더의 각 타임스텝에서의 출력을 얼마나 고려할지를 계산하고, 디코더의 출력과 연결합니다. 이 결과가 바로 context-adjusted hidden state입니다.
결국 앞에서, 디코더의 은닉 상태를 계산할 때 이 context-adjusted hidden state를 사용하는데, 매 타임 스텝마다 디코더의 은닉 상태를 그냥 계산하지 않고, 이러한 과정을 거쳐서 변형된 hidden state를 사용한다는 의미입니다.
Context Vectors(CoVe)
저자는 MT-LSTM에서 학습한 내용을 문맥 벡터(context vector)로 간주하고 이를 다운스트림 태스크로 전이하였습니다. w는 단어의 시퀀스이고 GloVe(w)를 GloVe 모델이 이 단어에 대해 생성한 벡터라고 할 때, MT-LSTM이 생성한 문맥 벡터의 시퀀스를 다음과 같이 정의합니다.
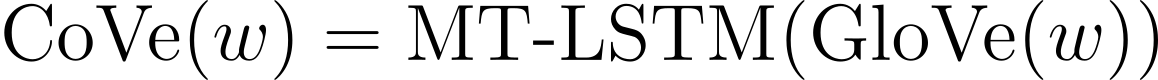
분류와 질문 답변 태스크에서는, 입력 시퀀스 w에 대하여 GloVe(w)와 이에 대응하는 CoVe(w) 벡터를 연결하여 다음과 같이 나타내었습니다.
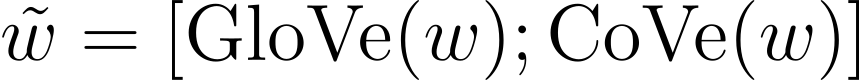
Classification with CoVe
CoVe가 다른 태스크에 얼마나 잘 전이되는지를 검증하기 위하여 설계한 biattentive classification network(BCN)에 대해 설명하겠습니다. 아래 그림과 같이 이 모델은 single-sentence classification과 two-sentence classification 태스크 모두를 처리하기 위해 설계되었습니다. 단문장 분류 작업에서 입력 시퀀스는 두 개의 시퀀스가 되도록 복제되므로, 이후에는 두 시퀀스가 입력되는 상황으로 가정하겠습니다.
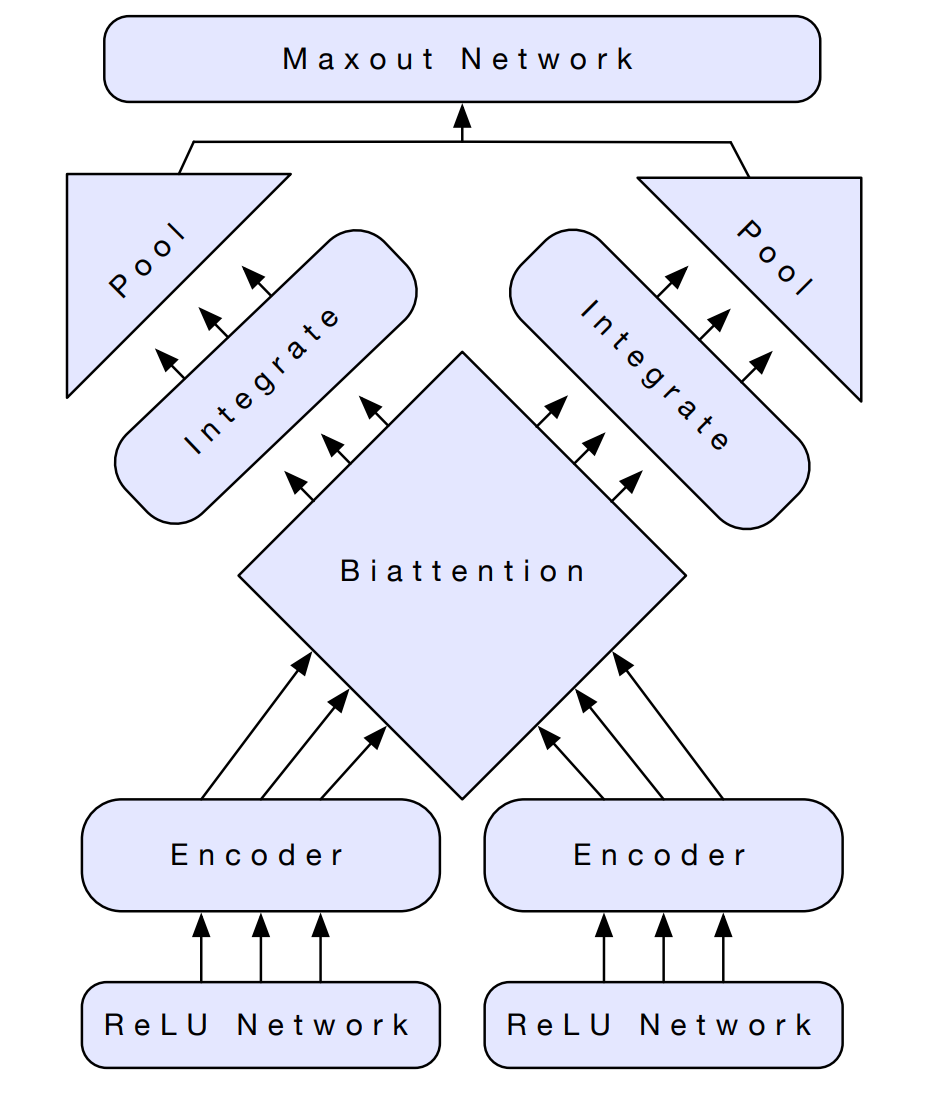
앞의 수식에서 설명한 것과 같이 입력 시퀀스 wx와 wy는 모델에 주입되기 전에 벡터의 시퀀스인 ˜wx,˜wy로 변환됩니다.
f는 ˜wx,˜wy에 대하여 피드포워드 신경망과 ReLU 레이어를 통과하는 것을 의미하는 함수이고, 양방향 LSTM은 이 함수의 출력을 사용하여 다음과 같은 task-specific representations을 계산합니다.
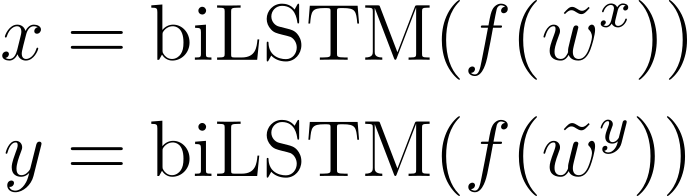
이 시퀀스는 시간 차원에 대하여 쌓아서(stacked along the time axis) 행렬 X,Y가 됩니다.
서로 의존적인 벡터 표현을 계산하기 위해서 biattention 메커니즘을 사용합니다. biattention은 우선 affinity matrix A=XY⊺를 계산합니다. 그 후 어텐션 가중치를 추출하고 열 방향으로 정규화합니다. 이 값은 x=y일 경우 self-attention과 같이 취급됩니다.

그 후 다음과 같은 context summareis를 사용하여 두 시퀀스를 연관짓습니다.

Conditioning information을 두 개의 서로 다른 하나의 레이어를 가진 양방향 LSTM의 각 시퀀스의 벡터 표현과 통합시켰습니다. 이 과정에서 concatenation 연산이 사용되었는데, 각 벡터는 다음과 같은 의미를 갖습니다. 원본 벡터 표현은 conditioning 과정에서 정보 손실 방지를 위해 사용하였고, context summaries와의 차이는 원본 신호와의 차이를 이해하기 위해서, 그리고 원본 벡터와 context summareis의 element-wise 곱셈은 원본 신호의 증폭이나 약화를 위해서 사용하였습니다.
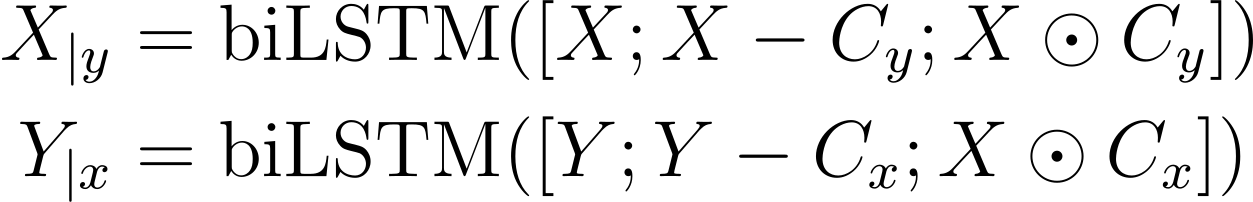
양방향 LSTM의 출력은 시간 차원을 따라 pooling 연산이 수행됩니다. 특성 추출을 위해서 max와 mean pooling이 각각 다른 모델에서 사용되었지만, min pooling과 self-attentive pooling을 더하는 것이 일부 태스크에 도움이 된다는 사실을 발견하였습니다. 각각은 conditioned sequences에서 다른 측면에 집중합니다.
매 타임스텝에서 self-attentive pooling은 각 시퀀스에 대해 다음과 같은 연산을 통해 가중치를 계산합니다.

그 후 이 가중치를 사용하여 다음과 같이 각 시퀀스에 대하여 가중합을 계산합니다.
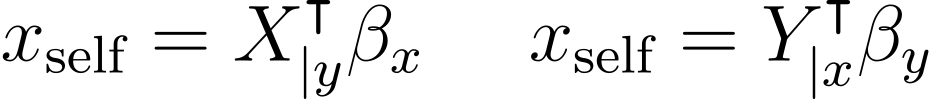
Pooled representations은 다음과 같이 모든 입력에 대해 하나의 representations으로 통합됩니다.
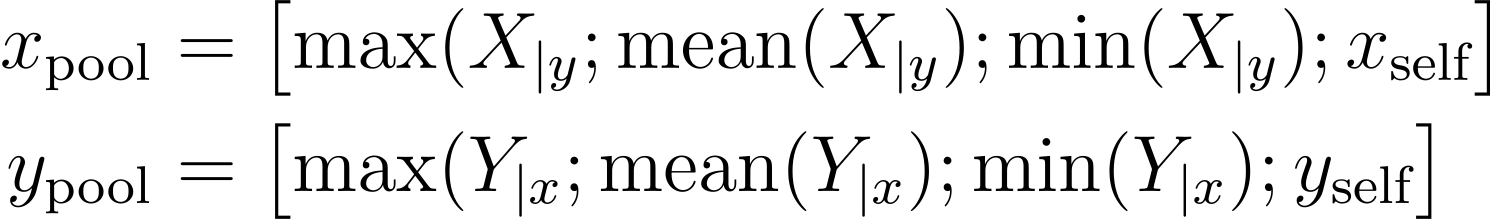
이 결합된 벡터 표현은 세 개의 레이어와 배치 정규화가 수행된 maxout network에 주입되어 타겟 클래스들에 대한 확률 분포를 생성합니다.
여기서도 수식의 의미를 다시 한번 간단하게 정리하고 넘어가겠습니다. 먼저 여기서는 본격적으로 전이 학습의 효과를 검증하기 위한 과정임을 이해해야 합니다. 앞에서 Context Vectors(CoVe)를 정의하였고, 이를 분류 작업을 위해 특별히 설계한 모델의 입력으로 넣어줍니다. 두 개의 문장이 입력되는 상황이라고 할 때 (7), (8)번 식과 같이 두 문장이 각각 모델의 입력이 됩니다. LSTM은 타임스텝마다 새로운 입력이 들어오므로 매 타임스텝마다의 입력인 벡터는 모여서 행렬 X, Y가 됩니다. (9)번 수식과 같이 이후 두 행렬을 통해 어텐션 가중치가 계산되는데, 이 값은 (10)번 식에서 context summary를 계산하는데 사용됩니다. Context summary는 두 입력 시퀀스가 어떻게 연관되는지에 대한 정보를 담고 있습니다.
그 후 (11), (12)번 수식에서 앞에서 계산된 벡터를 사용하여 다양한 연산을 수행합니다. 그 결과로 다음과 같이 세 개의 벡터가 만들어집니다. 원본 입력의 정보, 하나의 정보가 다른 입력에 대해 갖고 있는 정보, 그리고 그 정보를 얼마나 사용할지에 대한 수치인데 이들을 모두 모아서 하나의 벡터로 만듭니다. 두 문장의 연관성에 대한 정보가 담기므로 계속해서 X와 Y가 한 수식에서 동시에 등장하는 것을 볼 수 있습니다.
이렇게 만든 벡터는 LSTM의 pooling 레이어를 거칩니다. 여러 가지 pooling 방식을 사용하는데, 또 한 번 각 pooling 연산을 통해 얻은 벡터를 모아서 x_\textrm{pool}와 y_\textrm{pool}를 만듭니다. 이 벡터는 최종적으로 몇 가지 레이어를 거친 후, 분류 태스크에서 각 타켓 클래스에 대한 확률에 대한 정보를 갖게 됩니다.
Question Answering with CoVe
질문 답변 태스크에서는 x와 y를 분류 태스크에서 다음 수식만을 사용하여 계산합니다. 한 가지 다른 점은 함수가 g로 대체되었는데, 이는 활성화 함수로 ReLU 대신 tanh를 사용합니다. 이 경우에 두 시퀀스 중 하나는 문서에 해당하고 나머지 하나는 질문에 해당합니다. 두 시퀀스는 이후 원본 Dynamic Coattention Network(DCN)에서 구현된 것과 같이 coattention과 dynamic encoder에 주입됩니다.
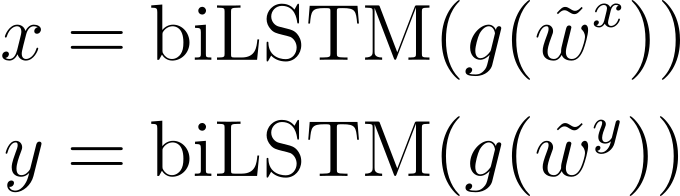
Datasets
Machine Translation
서로 다른 세 개의 MT-LSTM의 학습을 위해서 세 개의 다른 영어-독일어 기계번역 데이터를 사용하였습니다. 각각은 Moses Toolkit를 사용하여 토큰화되었습니다. 각각의 데이터셋은 그 크기가 다른데, 따라서 각 데이터셋을 사용하여 훈련한 모델도 MT-Small, MT-Medium, MT-Large로 명명하였습니다. 마찬가지로 각 모델로 학습한 인코더의 컨텍스트 벡터를 CoVe-S, CoVe-M, CoVe-L로 부릅니다.
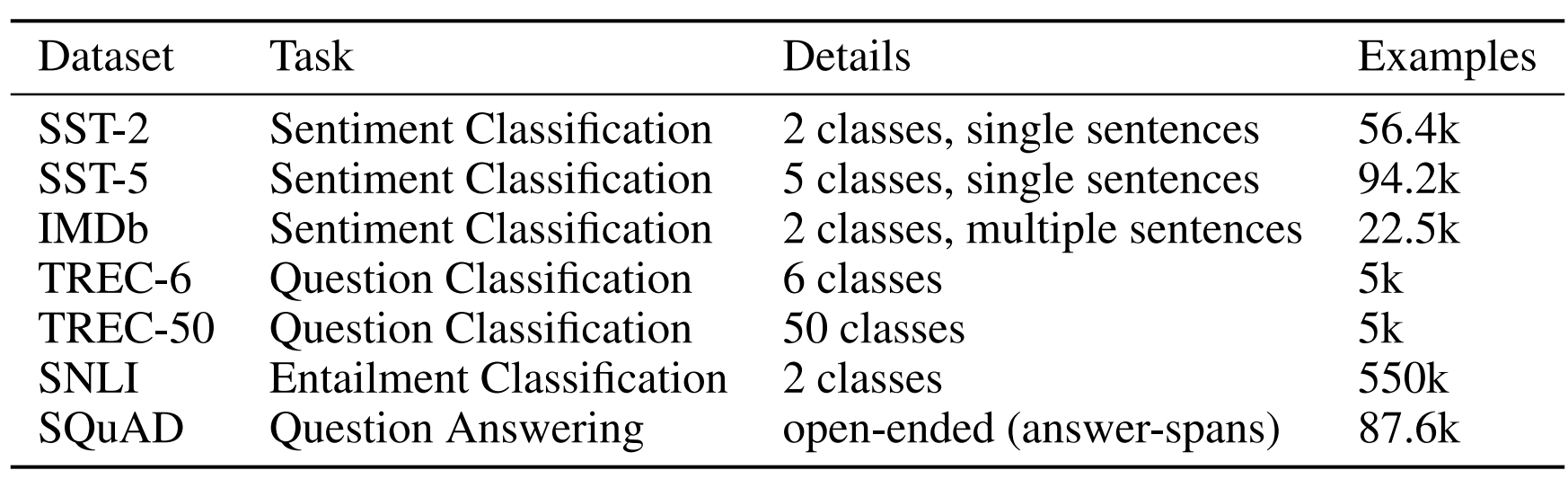
다운스트림 태스크의 데이터셋에 대한 설명은 논문의 표로 대체하겠습니다.
Experiments
Machine Translation
MT-Small로 학습한 MT-LSTM의 2016년 Multi30k 테스트 데이터에 대한 uncased, tokenized BLEU 점수가 38.5입니다. MT-Medium으로 학습한 모델은 2014년 IWSLT 테스트 데이터에 대해 25.54점을, MT-Large로 학습한 모델은 WMT 2016 테스트 데이터에 대해 28.96점을 얻었습니다. 이 결과는 이 모델들이 각 데이터셋 대하여 강건한 베이스라인 모델임을 의미합니다. 작은 데이터에서 학습한 모델이 더 높은 BLEU 점수를 얻었지만, 이 데이터는 더 제한된 도메인에 대하여 비교적 단순한 데이터셋임에 유의해야 합니다.
Classification and Question Answering
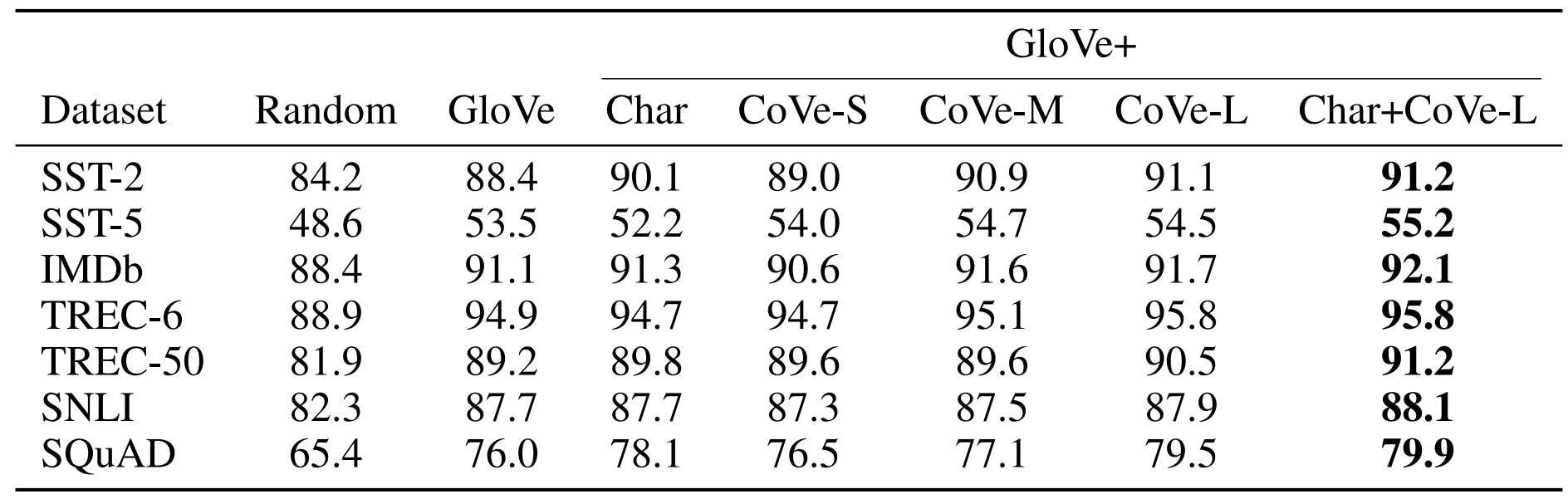
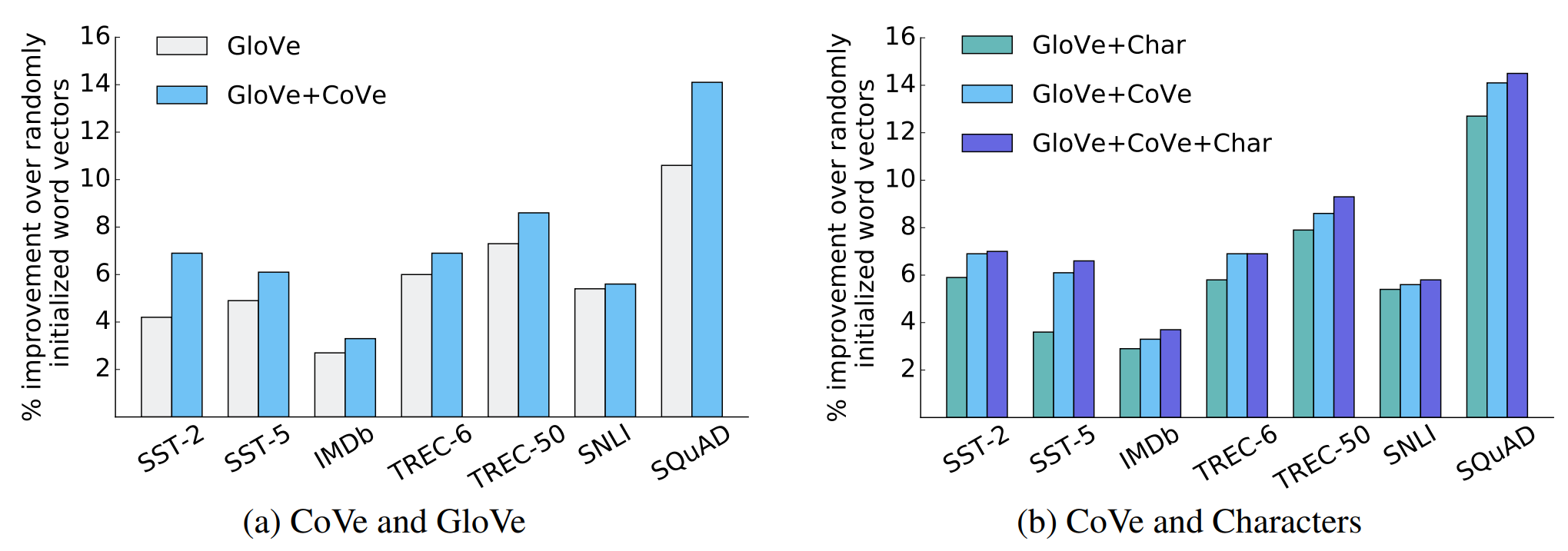
GloVe, character n-grams, CoVe와 각각을 섞어서 사용했을 때 각 태스크에서의 점수는 다음과 같습니다.
Benefits of CoVe
다음 그래프를 통해 각 태스크에서 CoVe를 사용했을 때의 효과를 한 눈에 알 수 있습니다. 오른쪽 그래프에서 CoVe를 사용했을 때의 성능 향삭 폭이 가장 큰 것을 알 수 있습니다. 특히 CoVe 뿐만 아니라 문자 단계의 n-gram 임베딩을 추가했을 때 일부 태스크에서 성능이 더욱 향상되는 것을 볼 수 있습니다. 이는 CoVe가 word-level 뿐만 아니라 character-level에 대한 정보도 보충해준다는 것을 의미합니다.
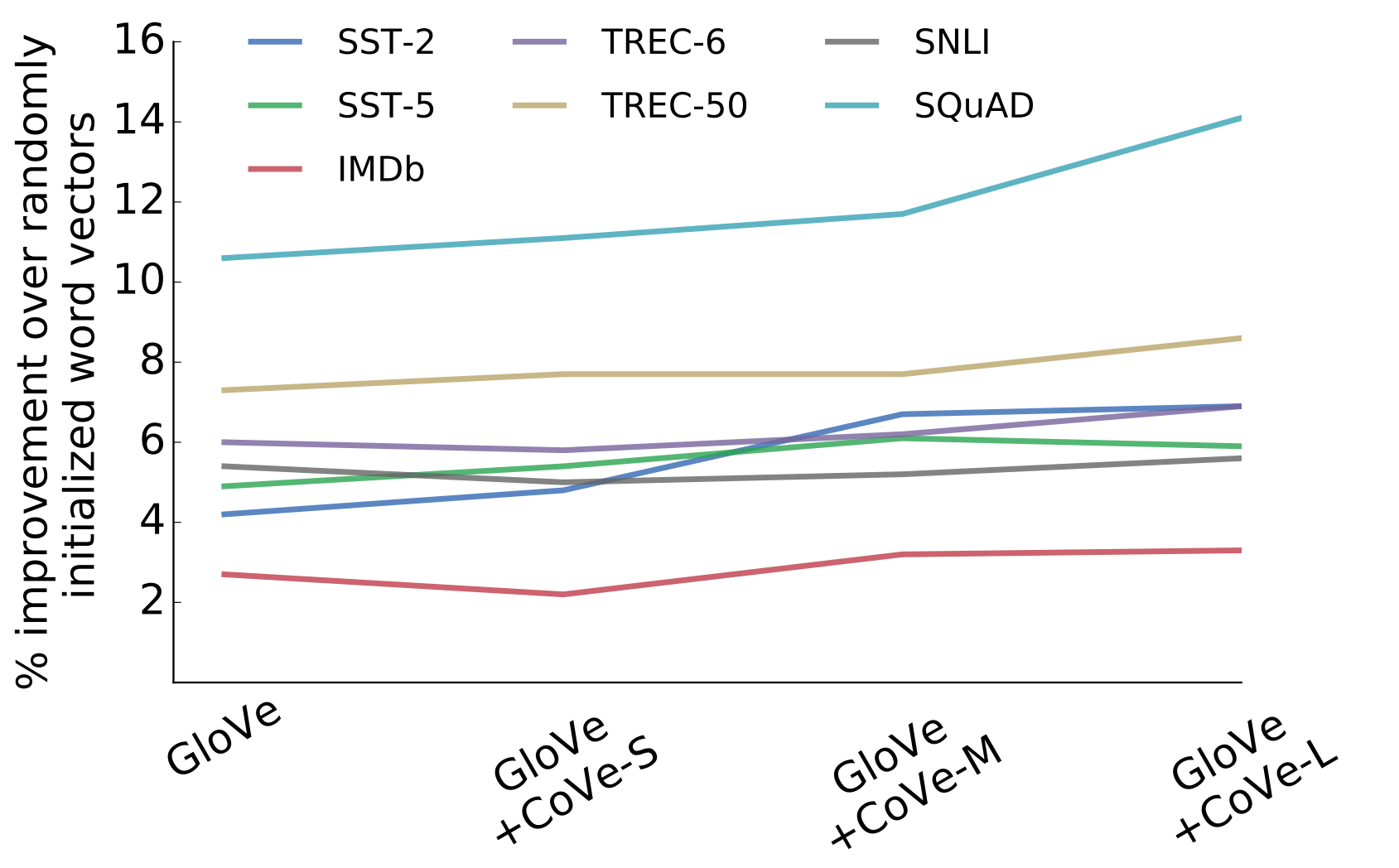
The Effects of MT Trainign Data
MT-LSTM 학습에 서로 다른 데이터셋을 사용하여 각 데이터가 다운스트림 태스크에 어떤 영향을 미치는지를 확인하였습니다. 아래 그래프를 바탕으로 다음과 같은 사실을 알 수 있습니다. 먼저 데이터셋의 크기가 커질수록, 일반적으로 더 복잡하고 다양한 언어를 사용하는데, 이는 다운스트림 태스크에서 더 큰 효과를 가져옵니다. 이 사실은 MT 데이터가 NLP에서 전이학습에 매우 적합한 리소스라는 처음의 가설을 뒷받침합니다.
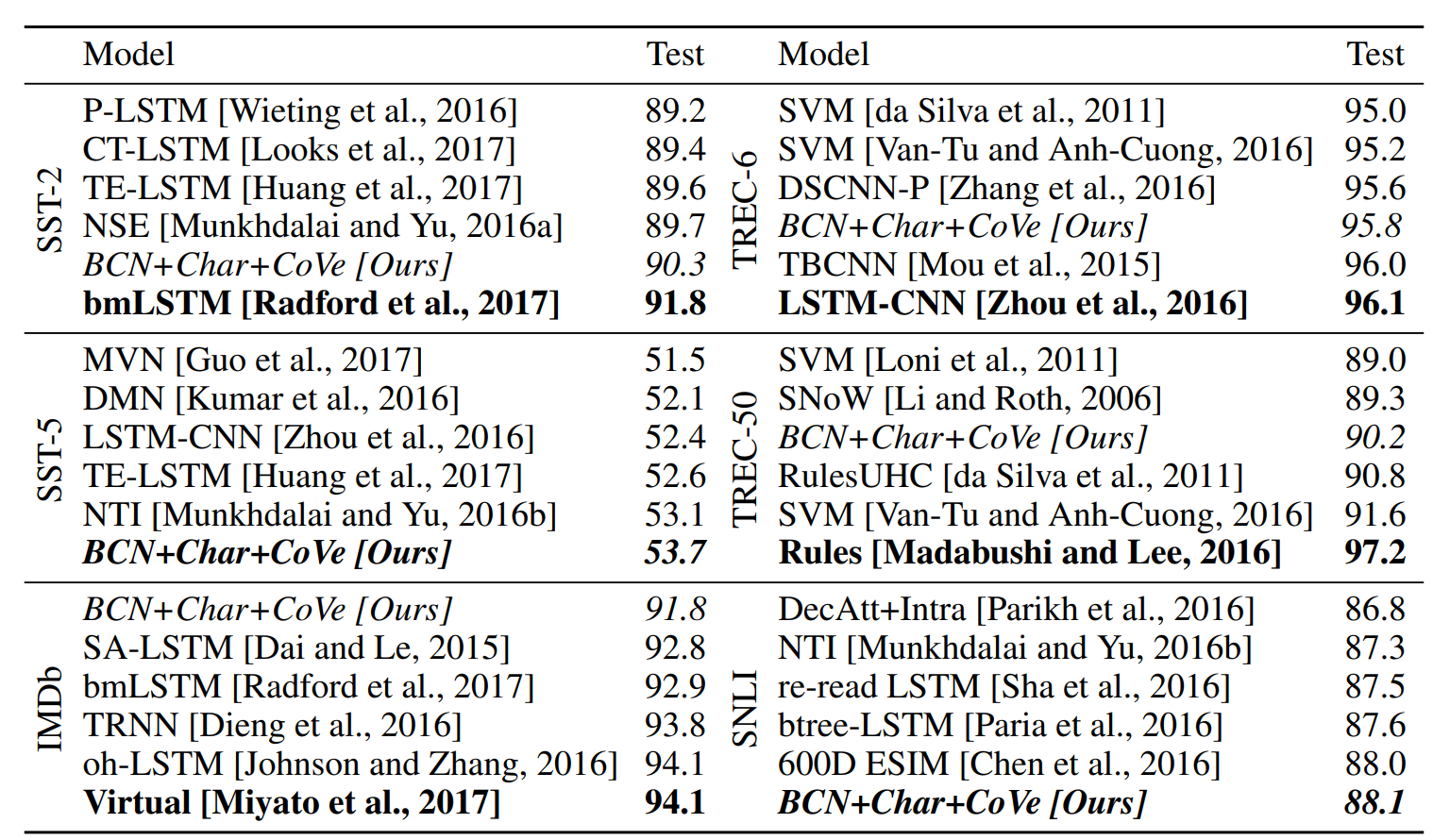
Test Performance
다음 표를 통해 각 태스크에서 가장 높은 검증 정확도를 보인 모델의 테스트 정확도를 확인할 수 있습니다. SST-5와 SNLI의 최종 테스트 점수는 기존 모델과 비교했을 때 가장 뛰어난 성능을 보임을 알 수 있습니다.
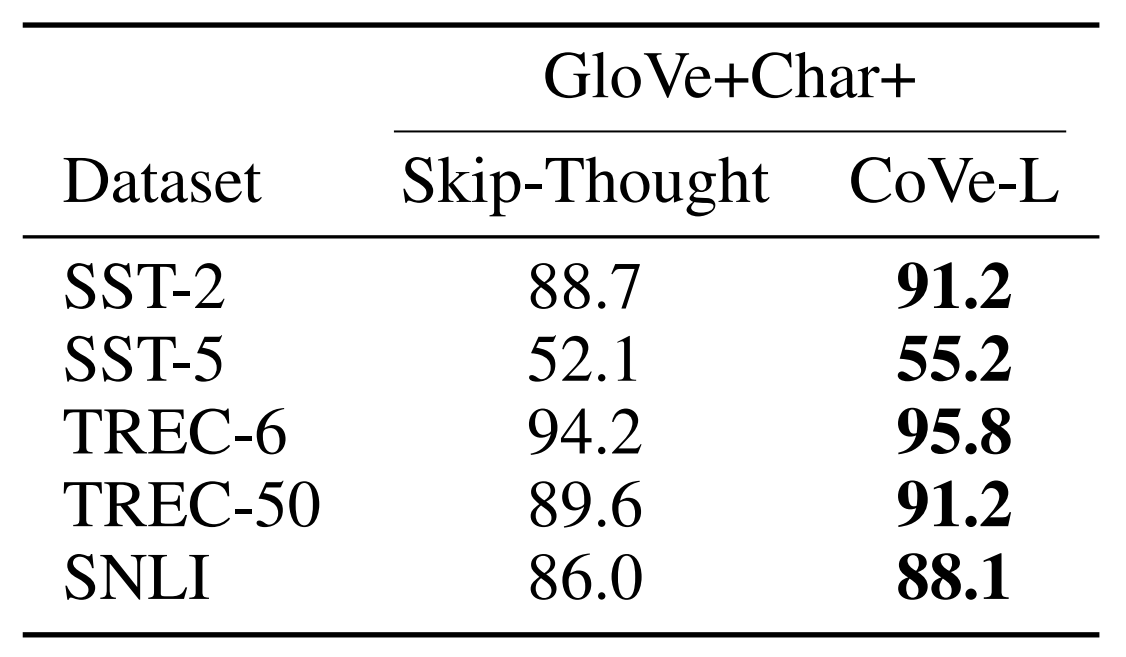
Comparison to Skip-Thought Vectors
Kiros는 문장을 하나의 skip-thought 벡터로 인코딩하는 방법을 제안하였고, 이는 다양한 태스크에 잘 전이됩니다. Skip-thought와 CoVe는 모두 사전학습 인코더를 사용하여 단어보다 더 높은 수준에서 정보를 이해합니다. 하지만 skip-thought 인코더는 인코더의 마지막 출력에만 의존하는 비지도 학습 방식을 사용합니다. 반면 MT-LSTM은 지도 학습을 사용하여 입력 시퀀스의 각 단어와 연관이 있는 중간 출력을 사용합니다. 추가로 skip-thought 벡터는 600차원을 가진 CoVe보다 더 많은 4800 차원을 가져 학습이 불안정합니다. 아래 표는 실제로 CoVe가 skip-thought에 비해 전이학습에 적합함을 보여줍니다.
Conclusion
저자는 지식 전이를 위해 기계 학습 태스크에서 사전 학습된 인코더를 도입하여 NLP 분야의 다양한 다운스트림 태스크에 사용하였습니다. 그리고 모든 경우에 CoVe를 사용한 모델이 GloVe, character n-gram 임베딩을 사용하여 단어 벡터를 임의로 초기화하는 베이스라인보다 더 나은 성능을 보였습니다. 저자는 이 연구가 통해 더 많은 가중치가 재사용되어 통합된 NLP 모델이 구축되기를 희망합니다.
Further Thinking
원래 임베딩에 대한 논문을 처음 읽은 후, 어느 정도 지식이 쌓이면 ELMo와 BERT 논문을 읽으려고 했습니다. 그런데 여러 임베딩 관련 논문에서 CoVe가 자주 등장하여 지나칠 수가 없었습니다. 일반적으로 ELMo가 contextualized representations의 시초로 알려져있지만, 조금 더 넓은 의미에서는 CoVe가 먼저라고 하는게 맞지 않나라는 생각도 들었습니다. 아직은 ELMo에 대해서는 기존 논문에서 언급된 내용 정도밖에 알지 못하므로, 더 공부한 후에 어떻게 ELMo가 contextualized representations의 시초가 되었는지, 왜 더 유명하고 일반적인 모델이 되었는지를 공부해봐야겠다는 생각이 들었습니다.




댓글